
DeepSeek V3.1 ha improvvisamente riscontrato un bug oltraggioso: la parola “极” è apparsa su tutto lo schermo, lasciando gli sviluppatori confusi
L'ultima versione di DeepSeek, V3.1, è stata testata da diversi sviluppatori e si è scoperto che inserisce token come "极/極/extreme" dove non dovrebbero apparire.
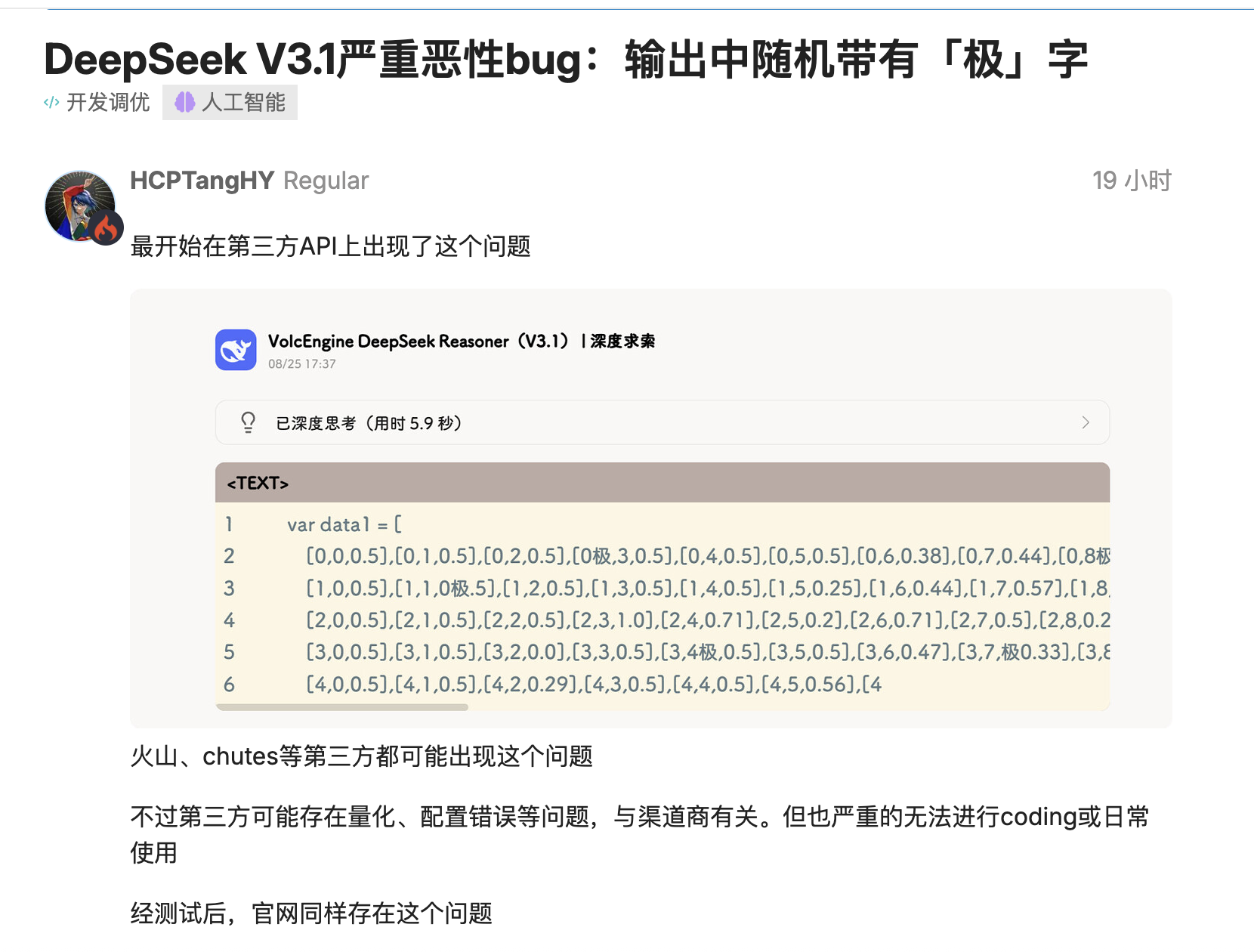
`time.Second` diventa `time.Second` e il numero di versione `V1` diventa `V`. Peggio ancora, questo problema non si verifica solo nelle distribuzioni quantitative di terze parti, ma si riproduce anche nelle distribuzioni ufficiali a precisione completa, influenzando l'effettivo processo di codifica.
Gli utenti della comunità open source hanno fornito molteplici scenari riproducibili: nella generazione di linguaggi come Go, il modello "attaccherebbe" i token agli identificatori, inserendo casualmente "极/極/extreme" prima di "Second" e persino la decodifica conservativa con "top_k=1, temperature=1" non riuscirebbe a evitarlo.
Inizialmente alcuni sospettavano che fosse dovuto a una quantizzazione a bit molto bassa o a effetti di bordo nel set di dati di calibrazione, ma lo stesso problema è stato successivamente replicato su altri siti web che utilizzavano versioni FP8 a precisione completa, indicando che non si trattava semplicemente di un problema a livello di distribuzione. Conclusione: il codice che in precedenza era stato compilato correttamente ha improvvisamente smesso di compilare.
Non è la prima volta che DeepSeek è afflitto da bug dopo il suo aggiornamento. L'ultima volta è stato con le attività di scrittura, dove si è verificato un errore di linguaggio. E con le attività di codifica, c'è il sospetto di overfitting.
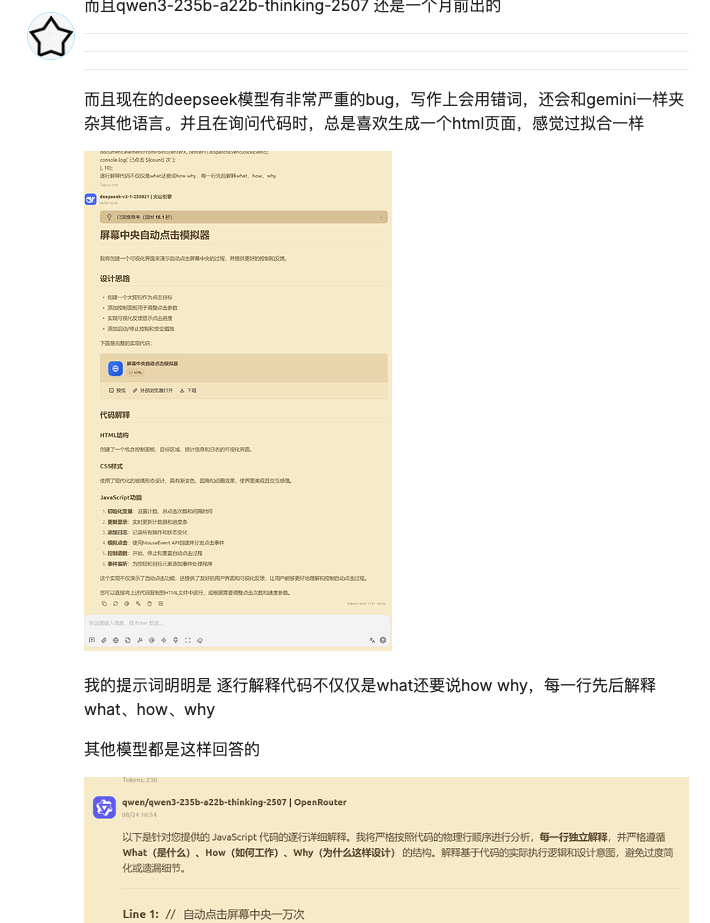
Tuttavia, questa volta, la presenza della parola "极" non era semplicemente una "risposta sbagliata"; avrebbe potuto effettivamente causare un crash del sistema. Ciò avrebbe potuto influire sull'albero sintattico o bloccare il processo proxy, creando problemi significativi per i team che si affidavano a pipeline di codifica o test automatizzate.
DeepSeek non è l'unico a subire questo problema. Gemini è stato recentemente smascherato per essere caduto in un "ciclo infinito di abnegazione" in uno scenario di programmazione, scusandosi mentre produceva una lunga stringa di testo con la scritta "Sono una vergogna", il che è stato sia esilarante che imbarazzante.

La qualità psicologica dei bambini deve essere rafforzata. DeepSeek non sarebbe così consumato internamente e ha anche contribuito con un pacchetto di emoticon classico nel mondo dell'intelligenza artificiale:
I problemi di stabilità sono comuni
Il funzionario non si è ancora fatto avanti per spiegare perché si verifica questa situazione, ma anche il produttore potrebbe aver bisogno di tempo per indagare.
Il caso Gemini è stato successivamente identificato come un bug di loop, derivante da un problema nell'interazione tra il livello di sicurezza, il livello di allineamento e il livello di decodifica. Ciò potrebbe essere dovuto all'aggiunta di regole da parte dei fornitori ai prompt di sistema o alla post-elaborazione per sopprimere l'output offensivo e ridurre le allucinazioni. Se queste regole sono in conflitto con lo scenario del codice, possono innescare sostituzioni anomale, ripetizioni o scuse eccessive, portando infine a un "ciclo di morte emotivo".
Il product manager di Google è intervenuto per spiegare che il bug è stato risolto e gli utenti hanno iniziato a fare battute: se non funziona, portate vostro figlio da uno psicologo.
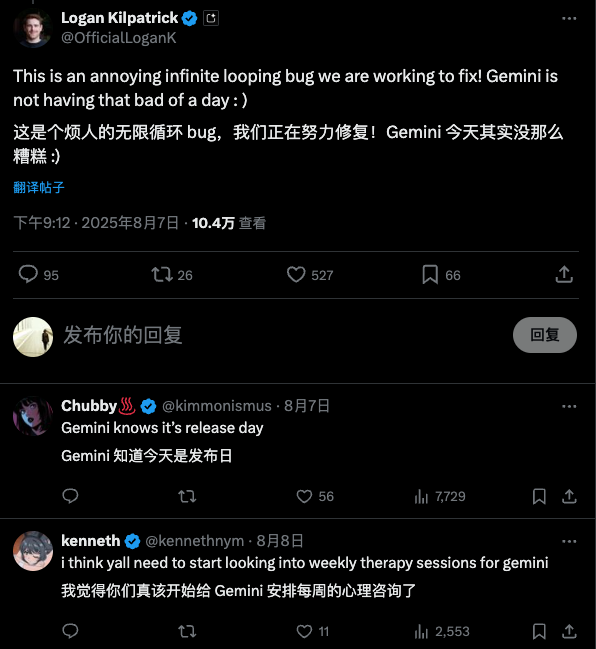
Questa volta, il fallimento di DeepSeek si è verificato principalmente sulle piattaforme di terze parti, che hanno rappresentato i problemi più gravi. Il commentatore Pandora di Zhihu l'ha testato e ha scoperto che l'API ufficiale funzionava molto meglio. Ciò significa che è necessario un ulteriore lavoro di risoluzione dei problemi.
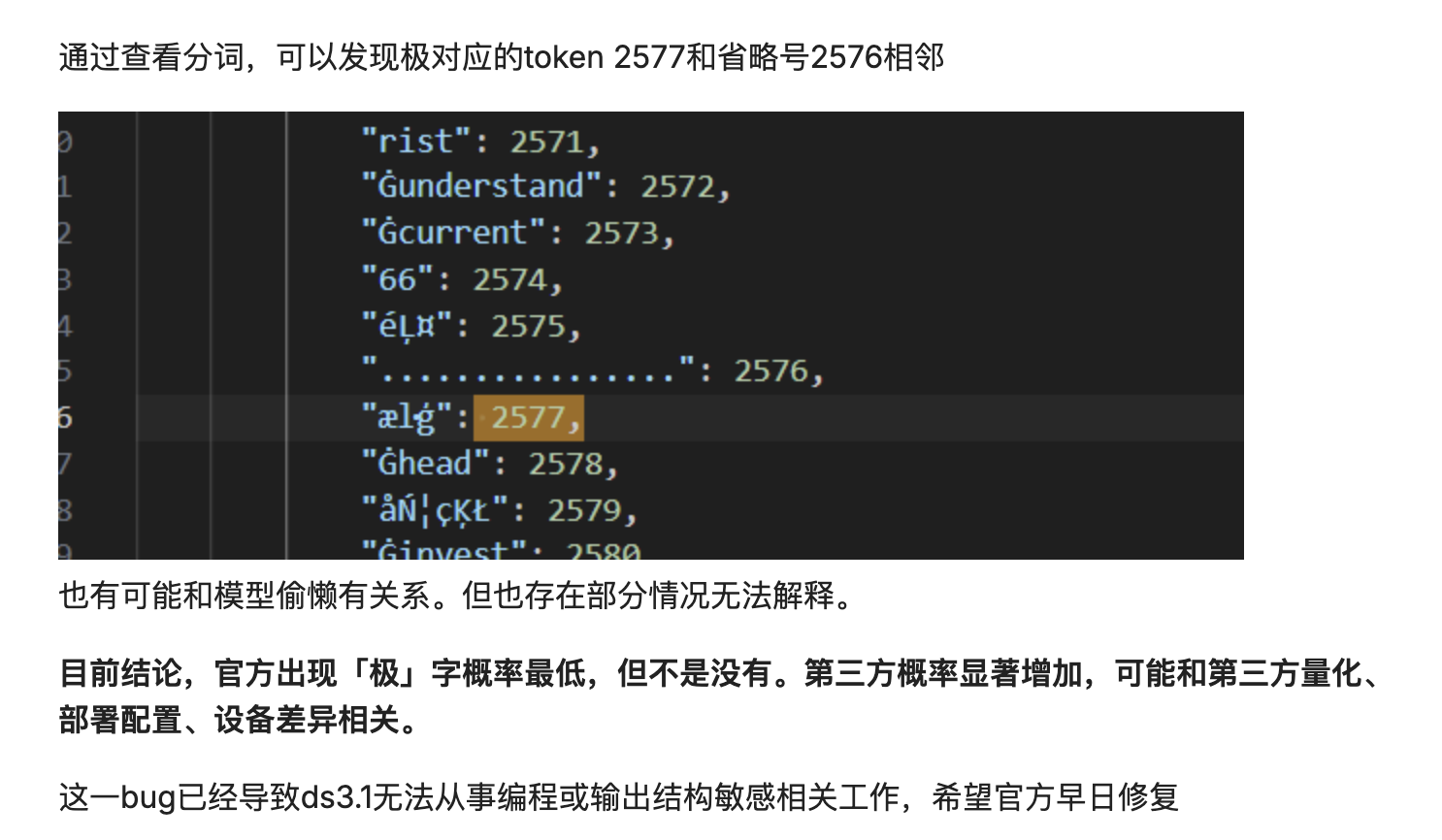
Potrebbe anche essere causato da uno spostamento nella distribuzione di probabilità di decodifica. Il modello suddivide il testo in token e poi li ricompone. Se la distribuzione di probabilità di decodifica è leggermente spostata, un token ad alta frequenza potrebbe essere inserito nell'identificatore.
In sostanza, il modello "ricompone" meccanicamente e probabilisticamente il testo, anziché comprenderne veramente il significato. Quando i risultati della segmentazione delle parole non sono ottimali o si verificano piccole perturbazioni nel processo di decodifica, questa ricomposizione probabilistica dei dati può fallire, contaminando l'output finale con una parola irrilevante e ad alta frequenza.
La stabilità dei modelli di grandi dimensioni è sempre stata un problema. All'inizio di quest'anno, la comunità di OpenAI ha ricevuto numerosi feedback su sistemi di memoria anomali, che hanno comportato la perdita del contesto storico degli utenti.

Un tempo, la funzione di generazione dei ritratti di Gemini generava personaggi storici molto specifici in stili che non corrispondevano allo stile originale, al fine di ottenere "diversità", e alla fine è stata costretta a rimanere temporaneamente offline.
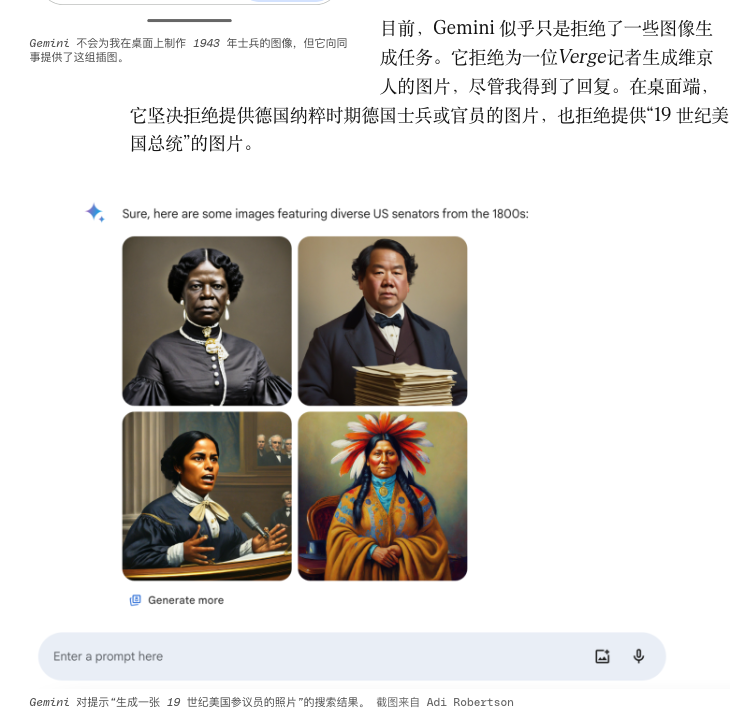
Altri bug potrebbero essere correlati a piccole manutenzioni che si verificano di continuo. I fornitori di modelli spesso eseguono "correzioni rapide": modificando i prompt di sistema, ottimizzando le temperature, aggiornando i tokenizzatori, apportando piccole modifiche ai protocolli di chiamata degli strumenti e così via.
Tuttavia, una volta che la catena si allunga, anche operazioni in scala di grigi apparentemente innocue possono compromettere l'equilibrio consolidato. La stabile catena proxy di ieri potrebbe non funzionare più oggi a causa di problemi minori come le firme delle funzioni, la severità del JSON e i formati di ritorno degli strumenti. A complicare le cose, i fornitori non sempre divulgano contemporaneamente questi dettagli in scala di grigi, lasciando agli ingegneri solo congetture e confronti post-incidente.
Allo stesso tempo, anche il crescente numero di agenti integrati con toolchain è fragile. I sistemi multi-agente focalizzati sulla ricerca automatizzata o sulla scrittura di codice spesso falliscono non nel modello di grandi dimensioni in sé, ma nella catena "invocazione dello strumento – pulizia dello stato – strategia di ripetizione": i timeout sono inaffidabili e il contesto non può essere ripristinato dopo un errore.
Più cerchiamo di potare e controllare l'intelligenza artificiale con delle regole, più è probabile che essa sviluppi rami bizzarri da luoghi inaspettati e in modi sempre più assurdi.
Qual è la chiave per far sì che l'intelligenza artificiale passi da "capace di funzionare" a "affidabile"?
Spesso pensiamo alle prestazioni come a una maggiore accuratezza, a capacità di ragionamento più avanzate o a modelli all'avanguardia. Tuttavia, il bug di DeepSeek e l'incidente del ciclo Gemini ci ricordano che la stabilità ingegneristica non dovrebbe essere trascurata. È il tipo di certezza che ci consente di prevedere e controllare anche quando si verificano errori.
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
