
Aggiornamento del modello mondiale di Fei-Fei Li: genera mondi 3D in tempo reale, solo una GPU

Mentre Ultraman di OpenAI continuava ad acquistare schede grafiche e potenza di calcolo ovunque per supportare il suo modello di generazione video Sora 2.
Il laboratorio di Fei-Fei Li, The World Labs, è in grado di gestire un intero mondo su una singola scheda grafica. Oggi hanno rilasciato una nuova tecnologia chiamata RTFM (Real-Time Frame Model), un modello di generazione di mondi in tempo reale completamente nuovo.

A differenza di Marble, il mondo generato da immagini rilasciato a metà settembre, RTFM non solo utilizza una singola foto per generare un mondo 3D in cui possiamo vagare ed esplorare liberamente, ma, cosa più importante, è progettato per funzionare in modo efficiente su una singola GPU H100 e generarlo in tempo reale.
Attualmente, RTFM è stato ufficialmente rilasciato come versione di anteprima per la ricerca e ne è disponibile una demo per consentirti di provarlo tu stesso.
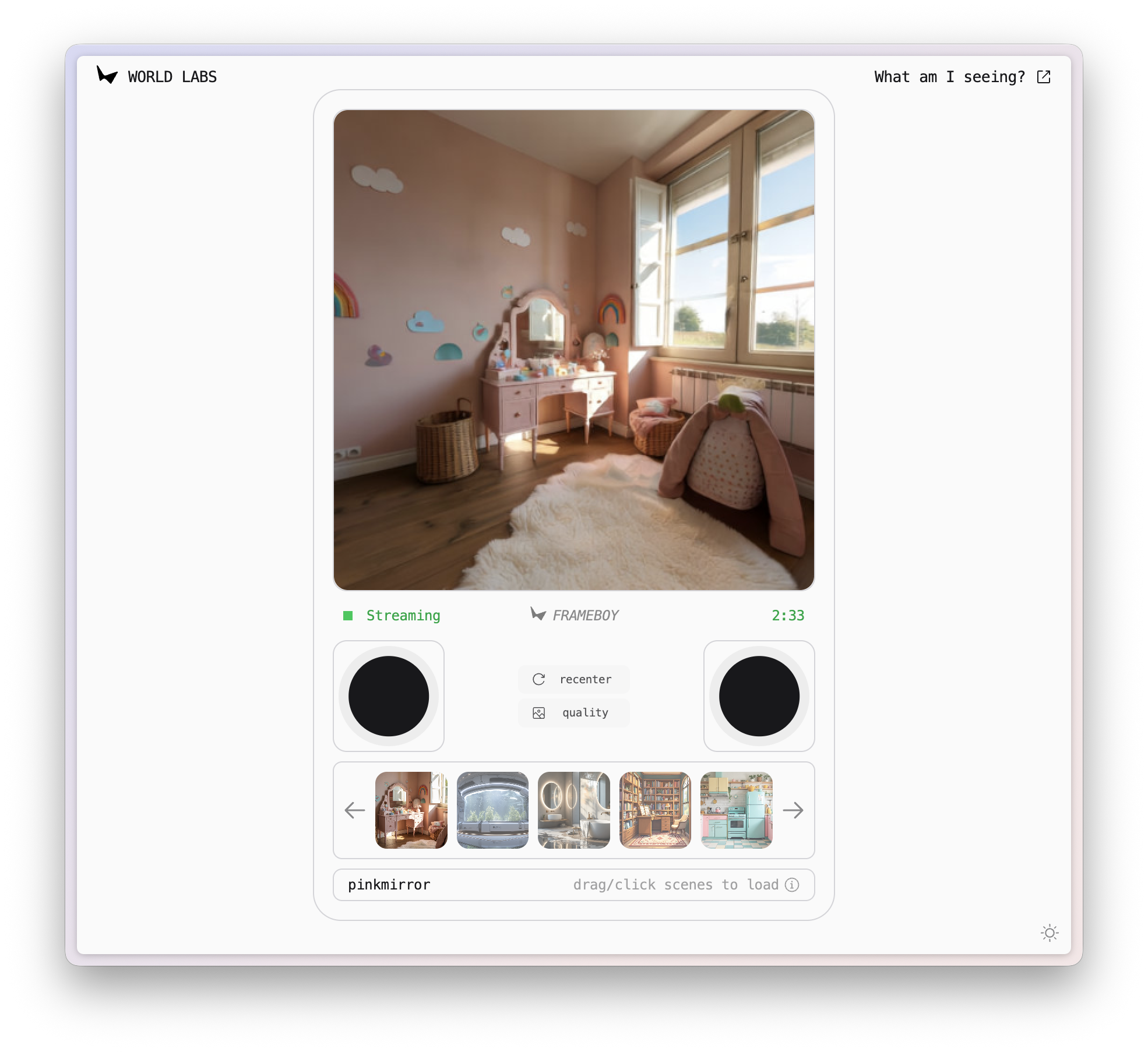
▲ Collegamento demo RTFM: https://rtfm.worldlabs.ai/
Ho scoperto inaspettatamente che il nome di questa demo è FRAMEBOY. Combinando il layout della pagina web, mi è subito venuto in mente il vecchio Game Boy.
Un mondo come questo, con luci, riflessi e ombre realistici, il tutto in tempo reale davanti ai nostri occhi, è, in un certo senso, solo un altro modo di giocare.
Più che semplice generazione, più interazione in tempo reale
La capacità principale di RTFM è la capacità di generare video interattivi in tempo reale. Può partire da un'immagine statica e generare una scena 3D liberamente esplorabile.
A differenza di molti modelli di mondo, RTFM è in grado di apprendere e riprodurre effetti visivi estremamente complessi e realistici. Che si tratti di riflessi su pavimenti in marmo, ombre proiettate da oggetti al sole o viste attraverso il vetro, RTFM li simula accuratamente.
RTFM non si basa sulla programmazione grafica tradizionale, ma consente al modello di evolversi continuamente attraverso l'apprendimento end-to-end di enormi quantità di dati video.

Alla base di questa capacità ci sono tre principi fondamentali attorno ai quali è stato progettato RTFM.
Efficienza: se vogliamo avvicinare il futuro al presente, i requisiti computazionali del modello mondiale rappresentano l'ostacolo più grande.
Che si tratti di video generati dall'intelligenza artificiale come Sora o Genie 3 di Google, non ancora ufficialmente rilasciato, entrambi pongono enormi sfide computazionali. Ricerche correlate hanno evidenziato che per generare un flusso video interattivo 4K a 60 fps in tempo reale, il modello di intelligenza artificiale deve elaborare un numero di token al secondo all'incirca equivalente al contenuto testuale di un libro di Harry Potter.
Se vogliamo mantenere la persistenza di questo contenuto generato durante un'interazione che dura più di un'ora, il contesto richiesto per l'elaborazione supererà i 100 milioni di token. Questo non è né pratico né conveniente per l'attuale infrastruttura informatica.

L'obiettivo del team di Fei-Fei Li è "eseguire i modelli di domani sull'hardware di oggi e fornire l'anteprima con la massima fedeltà".
Grazie all'ottimizzazione estrema dell'architettura, della distillazione del modello e del processo di inferenza, nonché alla riprogettazione dell'intero sistema, sono riusciti a ottenere RTFM, utilizzando una sola GPU H100 per eseguire l'inferenza a frame rate interattivi e generare risultati in tempo reale.
Scalabilità: dai modelli video ai modelli mondiali.
I motori 3D tradizionali utilizzano strutture esplicite come mesh triangolari, nuvole di punti gaussiane e rendering voxel, basandosi interamente su complesse conoscenze di computer grafica. Ogni oggetto deve essere modellato, texturizzato, illuminato e sottoposto a shadow baking. Questo approccio è simile al mondo 3D di Hunyuan che abbiamo introdotto in precedenza, focalizzato sulla generazione di una pipeline 3D completa.

Metodo 3D tradizionale (sinistra) e metodo RTFM (destra)
A differenza di Hunyuan, World Lab adotta un approccio diverso. RTFM non costruisce modelli 3D espliciti. Utilizza invece un trasformatore di diffusione autoregressivo simile a Sora per apprendere modelli di mondo direttamente dalle sequenze di fotogrammi video.
Ad esempio, il modello non ha più bisogno di sapere "questo è un muro" o "quella è una lampada". Impara solo cos'è il "senso spaziale" attraverso l'apprendimento da migliaia di video e impara a prevedere la nuova prospettiva successiva dalla sequenza di immagini 2D in input.
A differenza del metodo di generazione di risorse 3D, RTFM può sfruttare al meglio i dati e la potenza di calcolo in continua crescita, ottenendo così una scalabilità illimitata.
Persistenza , che mantiene il modello mondiale coerente come una nano banana.
La maggior parte dei modelli di generazione video ha un difetto intrinseco: la mancanza di memoria. Anche se Sora può generare 25 secondi di filmati spettacolari in una sola volta, il mondo finisce quando il video viene generato e non può fornire un'interazione continua.
Tuttavia, se vogliamo ricordare tutti gli scenari, l'onere computazionale aumenterà inevitabilmente man mano che l'esplorazione si approfondisce.

RTFM cerca di garantire la persistenza del mondo generato. Introduce un meccanismo chiamato "memoria spaziale", che assegna una "posa" precisa (posizione e orientamento) nello spazio 3D a ciascun fotogramma generato.
Quando si generano nuove immagini, il modello utilizza una tecnica chiamata "context juggling", che utilizza come riferimenti solo i fotogrammi vicini alla nuova immagine, anziché il contesto globale.

Ciò consente l'RTFM, consentendoci di entrare nel mondo, uscirne e ritornarvi ripetutamente senza aumentare l'onere computazionale.
Attualmente, la demo RTFM dura solo tre minuti, dopodiché perde la memoria del mondo. Ho passato molto tempo a trascinare i joystick sinistro e destro nella demo, e mi ha ricordato l'affermazione di Fei-Fei Li secondo cui l'intelligenza spaziale dovrebbe essere il prossimo passo nell'AGI.

Ci sarà davvero la possibilità in futuro di creare una connessione chiara tra il mondo reale e quello virtuale, come in Ready Player One? Basta guardare l'attuale modello di gioco per rendersi conto che ci sono ancora troppi contenuti da caricare.
Dopotutto, anche una singola GPU H100 costa più di 25.000 dollari. Ma con il calo del prezzo della potenza di calcolo e la velocità degli algoritmi, potremmo assistere a un "aggiornamento" davvero significativo del modello mondiale, un giorno in cui la realtà sarà completamente generata.
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
