
Il Gemini 3 è finalmente uscito. Qual è il suo vero asso nella manica?
Quando è stata rilasciata la versione di anteprima di Gemini 3 Pro, la prima reazione di molte persone è stata probabilmente: Finalmente è arrivata .
Dopo quasi un mese di teaser e fughe di notizie – con accenni qua e là a parametri più potenti, inferenze più intelligenti e una grafica più elaborata – tutti non vedono l'ora di vederlo. Se a questo si aggiungono i contrattacchi di OpenAI e Gork, è chiaro che Gemini 3 sarà un lancio colossale.

Anche i principali punti di forza del Gemini 3 sono noti: ragionamento più efficace, dialogo più naturale e comprensione multimodale più intuitiva. L'affermazione ufficiale è che supera il Gemini 2.5 in una serie di parametri accademici.
Tuttavia, se ci concentriamo solo su questi numeri, è facile trascurare un cambiamento più cruciale:
Il Gemini 3 sembra più un "aggiornamento di sistema" della suite Google che lo circonda che un semplice aggiornamento di modello.
Per quanto riguarda gli aggiornamenti dei modelli, Google ha già chiarito la sua posizione.
Per prima cosa, passiamo rapidamente in rassegna le "metriche concrete", in modo che tutti abbiano le idee chiare:
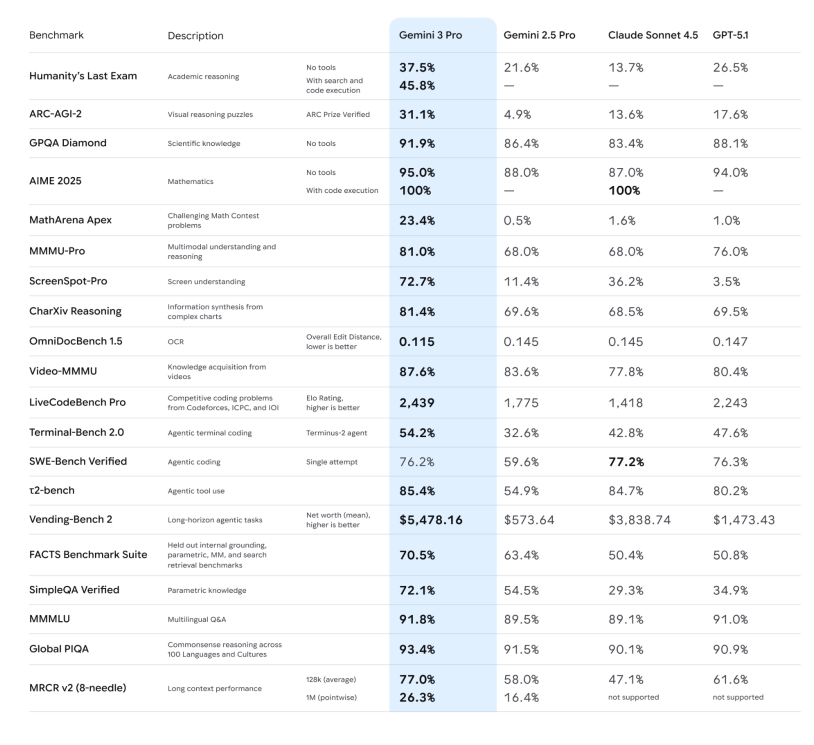 – Capacità di ragionamento: la dichiarazione ufficiale sottolinea che Gemini 3 Pro ha raggiunto nuovi punteggi elevati in una serie di benchmark di ragionamento e matematica ad alta difficoltà, come Humanity's Last Exam, GPQA Diamond e MathArena, posizionandolo come un "modello di ragionamento di livello dottorale".
– Capacità di ragionamento: la dichiarazione ufficiale sottolinea che Gemini 3 Pro ha raggiunto nuovi punteggi elevati in una serie di benchmark di ragionamento e matematica ad alta difficoltà, come Humanity's Last Exam, GPQA Diamond e MathArena, posizionandolo come un "modello di ragionamento di livello dottorale".
– Comprensione multimodale: non solo possono guardare immagini e PDF, ma possono anche ottenere punteggi leader del settore in video lunghi ed esami multimodali (MMMU-Pro, Video-MMMU), dimostrando un miglioramento significativo nella loro capacità di descrivere immagini e riassumere i punti chiave dei video.
– Modalità Deep Think: i test ARC-AGI dimostrano che l'attivazione di Deep Think comporta un notevole miglioramento nella risoluzione di nuovi tipi di problemi.
Da queste prospettive, è facile classificare il Gemini 3 come "una generazione di modelli multiuso più intelligente rispetto al 2.5". Ma se questo è tutto, è solo un nome nuovo in classifica. Persino Josh Woodward, in un'intervista, ha affermato che questi parametri rigorosi dovrebbero essere usati solo come riferimento.

In altre parole, "quanti punti sono stati totalizzati" è solo un modo relativamente intuitivo di rappresentare il punteggio. La parte davvero interessante è dove Google lo ha incorporato e cosa intende collegarlo. In questo aggiornamento, la "multimodalità nativa" è chiaramente la priorità assoluta.

Se dovessimo trovare una linea di demarcazione per gli attuali grandi modelli, questa sarebbe: supportano semplicemente la multimodalità oppure sono stati progettati fin dall'inizio per essere "nativamente multimodali"?
Questo concetto è stato proposto da Google nel 2023, durante l'era Gemini 1, e da allora è stato il fulcro della loro strategia: combinare fin dall'inizio più modalità, come testo, codice, immagini, audio e video, nei dati di pre-addestramento, anziché addestrare prima un ampio modello di testo e poi allegare sottomodelli visivi e vocali.
Quest'ultimo approccio è la strategia che molti modelli hanno utilizzato in passato per l'elaborazione multimodale. In sostanza, è ancora in stile "pipeline": il parlato deve prima essere immesso nell'ASR, e poi il testo convertito viene immesso nel modello linguistico; l'elaborazione delle immagini deve prima passare attraverso un codificatore visivo indipendente, e poi le caratteristiche vengono collegate al modello linguistico.
Gemini 3 tenta di ripiegare questa pipeline: lo stesso grande Transformer vede simultaneamente testo, immagini, audio e persino sezioni video durante la fase di pre-addestramento, il che gli consente di apprendere i punti in comune e le differenze di questi segnali nello stesso spazio di rappresentazione.
Meno passaggi di elaborazione significano meno perdita di informazioni. Per un modello, l'apprendimento multimodale nativo non consiste semplicemente nell'"apprendere più formati di input", ma nell'eliminare passaggi non necessari. Ridurre questi passaggi significa preservare un'intonazione più completa, dettagli visivi più densi e un ordine temporale più accurato.
Ancora più importante, questo ha un impatto rivoluzionario sul livello applicativo: quando un modello presuppone fin dall'inizio che "il mondo è multimodale", i prodotti che crea sono più simili a una nuova forma di interazione che a semplici robot che rispondono a domande e risposte.
Da Search ad Antigravity, nasce un nuovo autobus.
Con il lancio di Gemini 3, Google ha anche aggiornato la modalità AI nella barra di ricerca. In questa modalità, non si vede più una riga di link blu, ma un'intera area di contenuti dinamici generati da Gemini 3, che può includere riepiloghi, schede strutturate e cronologie. Sebbene venga attivata in modo condizionale, è raro che la ricerca venga avviata direttamente al rilascio del modello.
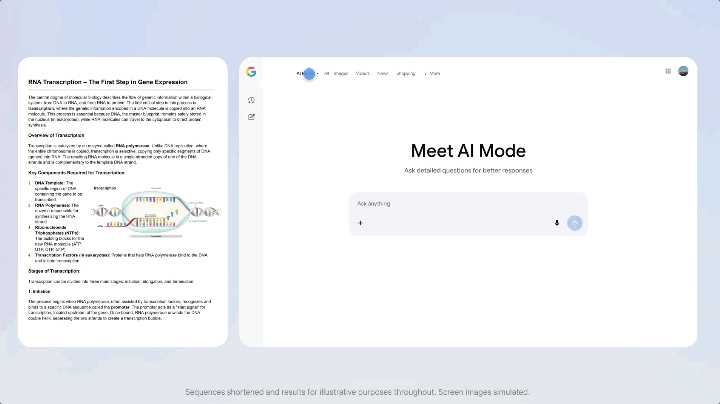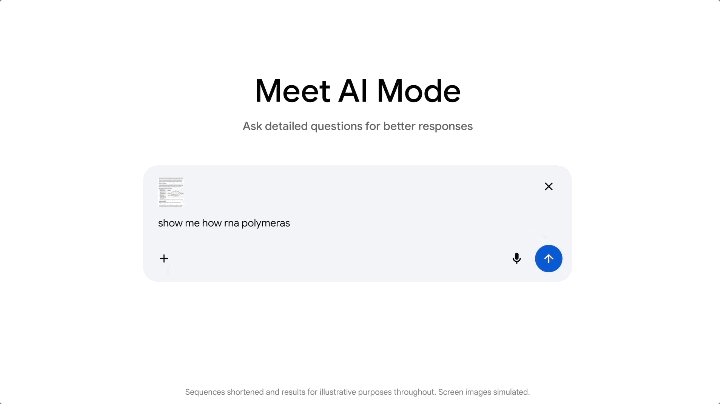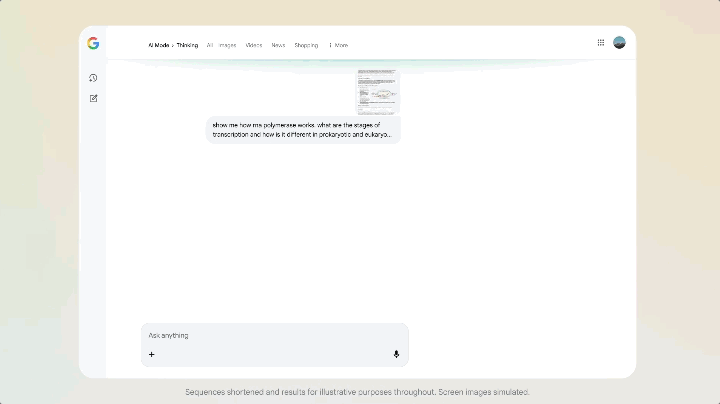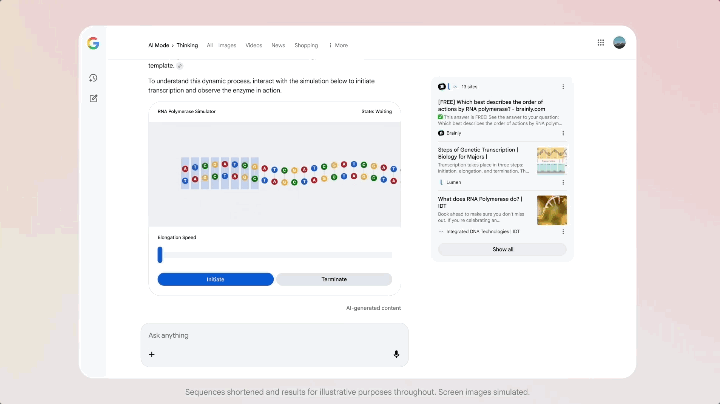
Ciò che è ancora più speciale è che la modalità AI supporta l'uso di Gemini 3 per abilitare nuove esperienze di interfaccia utente generativa, come layout visivi immersivi, strumenti interattivi e simulazioni, tutti generati in tempo reale in base al contenuto della query.
Questo approccio è stato adottato e diffuso in una vasta gamma di prodotti Google. Ufficialmente, viene descritto come un "partner di pensiero", che offre risposte più dirette, meno banalità, più "prospettive personali" e più "azioni autodirette".
Grazie alle sue capacità multimodali, puoi fargli guardare un video di qualcuno che gioca e aiutarti a identificare problemi di movimento e a generare un piano di allenamento; ascoltare una lezione audio e lui può generare una scheda di apprendimento con quiz; oppure combinare diverse note scritte a mano, PDF e pagine web in un riepilogo completo con immagini e testo.

Questa parte è più una narrazione da "super assistente personale": dopo aver inserito Gemini 3 nell'app, questa cerca di coprire casi di utilizzo quotidiano per l'apprendimento, la vita e il lavoro d'ufficio leggero, con lo stile di "tu ti preoccupi di meno, io lavorerò di più".
Per quanto riguarda le API, Gemini 3 Pro è ufficialmente elencato come "il più adatto per la codifica di agenzie e la codifica di vibrazioni": ovvero, non solo può scrivere front-end e creare interazioni, ma anche richiamare strumenti e completare attività di sviluppo passo dopo passo in attività complesse.
Ciò che questa volta è più impressionante è la capacità di Gemini di generare strumenti applicativi "completi".

Questo ci porta al nuovo IDE: Antigravity. Ufficialmente, è concepito come un ambiente di sviluppo "con l'intelligenza artificiale come protagonista". Questo obiettivo è raggiunto attraverso i seguenti metodi:
– Più agenti AI possono accedere direttamente all'editor, al terminale e al browser;
Si divideranno il lavoro: alcuni scriveranno il codice, altri cercheranno la documentazione e altri ancora eseguiranno i test;
– Tutte le operazioni verranno registrate come artefatti: elenco delle attività, piano di esecuzione, screenshot di pagine web, registrazione dello schermo del browser, ecc., in modo che gli utenti possano verificare "cosa hai fatto" in seguito.
In un test in cui uno YouTuber ha intervistato il product manager di Gemini, il compito era progettare un sito web di reclutamento e il comando era così semplice che bastava copiare, copiare, copiare tutto, senza apportare alcuna modifica, e semplicemente incollare.
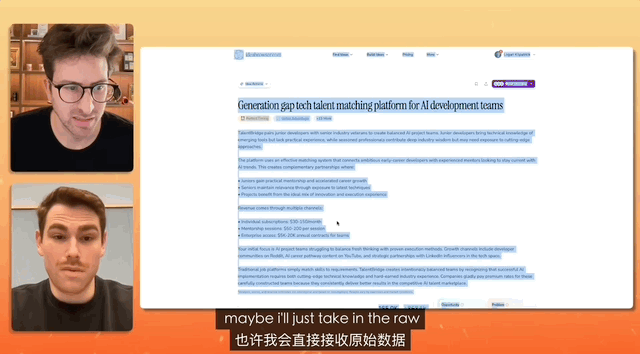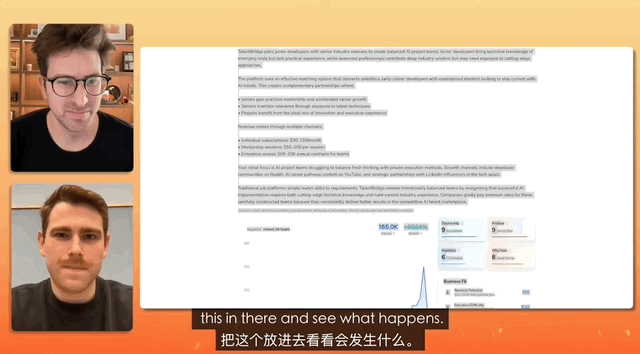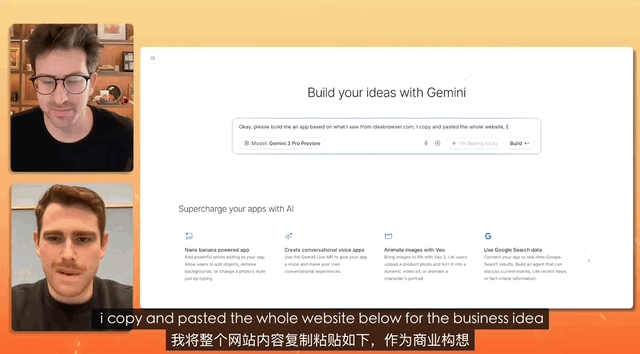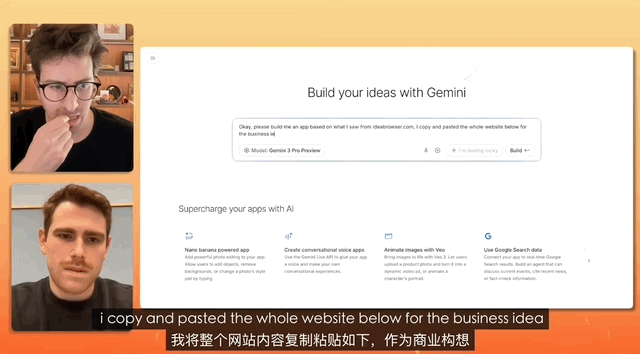
Alla fine, Gemini ha completato autonomamente l'analisi del testo confuso e ha creato un sito web completo, gestendo autonomamente tutta la configurazione e la distribuzione del materiale.
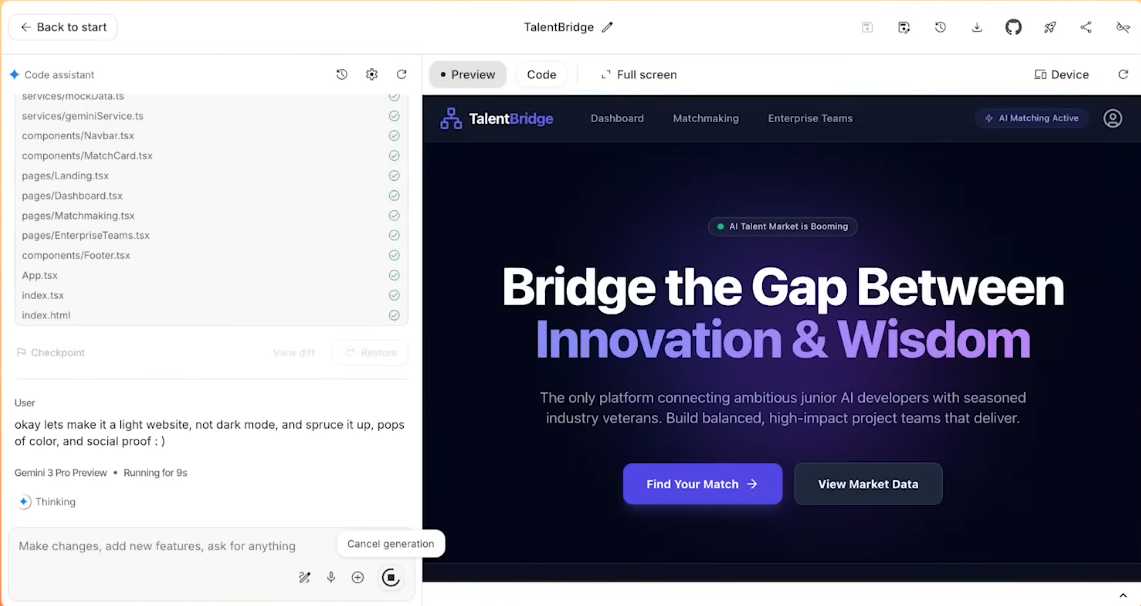
Da questa prospettiva, Gemini 3 non è solo un "modello più intelligente", ma piuttosto un nuovo bus che Google vuole utilizzare per collegare insieme Ricerca, App, Workspace e strumenti per sviluppatori.
Tornando alla sensazione più intuitiva: la differenza più evidente tra Gemini 3 e il suo predecessore è che è più disponibile e più bravo ad "aiutarti a collaborare". Questa è anche l'aspettativa che Google ha nei suoi confronti.
Si esercita pressione su tutte le parti
Oltre a Google stessa, la versione Gemini 3 Preview ha di fatto aperto una nuova strada per l'intero settore dei modelli di grandi dimensioni: l'esplosione delle applicazioni con capacità multimodali è inevitabile.
In precedenza, le capacità multimodali (la capacità di vedere e sentire) erano un bonus; ora, il "multimodale nativo" sarà un requisito fondamentale, e non potrà essere un'imitazione a metà. Le capacità di comprensione audiovisiva end-to-end di Gemini 3 costringeranno OpenAI, Anthropic (Claude) e la comunità open source ad accelerare l'abbandono graduale dei vecchi paradigmi. Per i produttori di modelli che si affidano ancora a "screenshot + OCR" per comprendere le immagini, il conto alla rovescia tecnologico è iniziato.
Anche il "guscio" e lo strato intermedio subiranno un'enorme pressione. Le potenti funzionalità di pianificazione degli agenti di Gemini 3 surclassano direttamente molte startup di workflow agentici presenti sul mercato attuale. Quando il modello di base stesso sarà in grado di gestire perfettamente il ciclo chiuso di "decomposizione dell'intento – invocazione dello strumento – feedback dei risultati", la realtà del "modello come applicazione" sarà un passo più vicina.
Inoltre, anche i produttori di telefoni cellulari potrebbero percepire un cambiamento di tendenza. Il design leggero e la reattività del Gemini 3 riflettono il fatto che Google sta potenziando le sue capacità per i modelli edge. Considerando anche le precedenti collaborazioni di Apple con diversi produttori di modelli, si può ipotizzare che la concorrenza nel settore si sposterà da una "guerra di potenza di calcolo", che si limita a confrontare i parametri del cloud, a una "guerra di esperienza", che si concentra sulla capacità di essere implementata in terminali come telefoni cellulari, occhiali e automobili.
Non è più così importante chi è il più forte; ciò che conta è chi è "sempre a tua disposizione".
Nella prima metà della competizione tra modelli su larga scala, la domanda era ancora: "Quale modello è più forte?". Parametri, punteggi e classifiche erano tutti incentrati sul "talento". Con la generazione Gemini 3, la domanda si è gradualmente spostata su: "Quali capacità sono realmente radicate nel prodotto e negli utenti?"
Questa volta la risposta di Google è un percorso relativamente chiaro: partendo dal modello Gemini 3 sottostante, si collega alle chiamate degli strumenti e all'architettura dell'agenzia, per poi collegarsi a interfacce di prodotto specifiche come Ricerca, App Gemini, Workspace e Antigravity.
Si può pensare che Google utilizzi Gemini 3 per fare della multimodalità nativa la sua nuova carta vincente e per integrare un nuovo "bus intelligente" in tutti i prodotti del suo ecosistema, in modo che lo stesso set di funzionalità possa essere utilizzato a tutti i livelli.
Per quanto riguarda la possibilità che possa cambiare in modo definitivo il modo in cui si cerca, si scrive e si programma ogni giorno, la risposta non sarà nella conferenza stampa, ma nei prossimi mesi: vedremo quante persone lo integreranno inconsciamente nel loro flusso di lavoro quotidiano.
Se davvero si arrivasse a questo punto, chi è il numero uno in classifica potrebbe non essere più così importante.
#Benvenuti a seguire l'account WeChat ufficiale di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
