
Com’è collegare quattro Mac Studio di fascia alta e far funzionare due macchine DeepSeek contemporaneamente per soli 400.000 yuan?

Qualche mese fa, iFanr ha implementato con successo un modello locale DeepSeek da 671B (versione quantizzata a 4 bit) su un Mac Studio con processore M3 Ultra. Se quattro Mac Studio di fascia alta con processori M3 Ultra fossero collegati tra loro utilizzando strumenti open source per formare un "cluster di intelligenza artificiale a livello desktop", il limite massimo dell'inferenza locale potrebbe essere ulteriormente innalzato?
Questo è anche il problema che Exo Labs, una startup britannica, sta cercando di risolvere.
Non dare per scontato che l'Università di Oxford abbia una fornitura illimitata di GPU
Si potrebbe pensare che un'università prestigiosa come Oxford abbia più GPU di quante ne possa utilizzare, ma non è affatto così.
I fondatori di Exo Labs, Alex e Seth, si sono laureati all'Università di Oxford. Anche in un'istituzione così prestigiosa, l'accesso ai cluster GPU richiede mesi di attesa in coda e le richieste possono essere inoltrate solo una scheda alla volta, rendendo il processo lungo e inefficiente.
Si rendono conto che l'attuale infrastruttura di intelligenza artificiale altamente centralizzata emargina i singoli ricercatori e i piccoli team.
Lo scorso luglio hanno lanciato il loro primo esperimento, eseguendo con successo il modello LLaMA utilizzando due MacBook Pro in tandem. Sebbene le prestazioni fossero limitate, con un output di soli tre token al secondo, sono state sufficienti a dimostrare la fattibilità dell'utilizzo dell'architettura Apple Silicon per il ragionamento di intelligenza artificiale distribuita.

La svolta arrivò con il lancio di M3 Ultra Mac Studio. I suoi 512 GB di memoria unificata, gli 819 GB/s di larghezza di banda di memoria, una GPU a 80 core e la capacità di trasferimento bidirezionale di 80 Gbps di Thunderbolt 5 resero i cluster di intelligenza artificiale locali una realtà.
Com'è eseguire contemporaneamente due modelli da 67 miliardi di parametri?
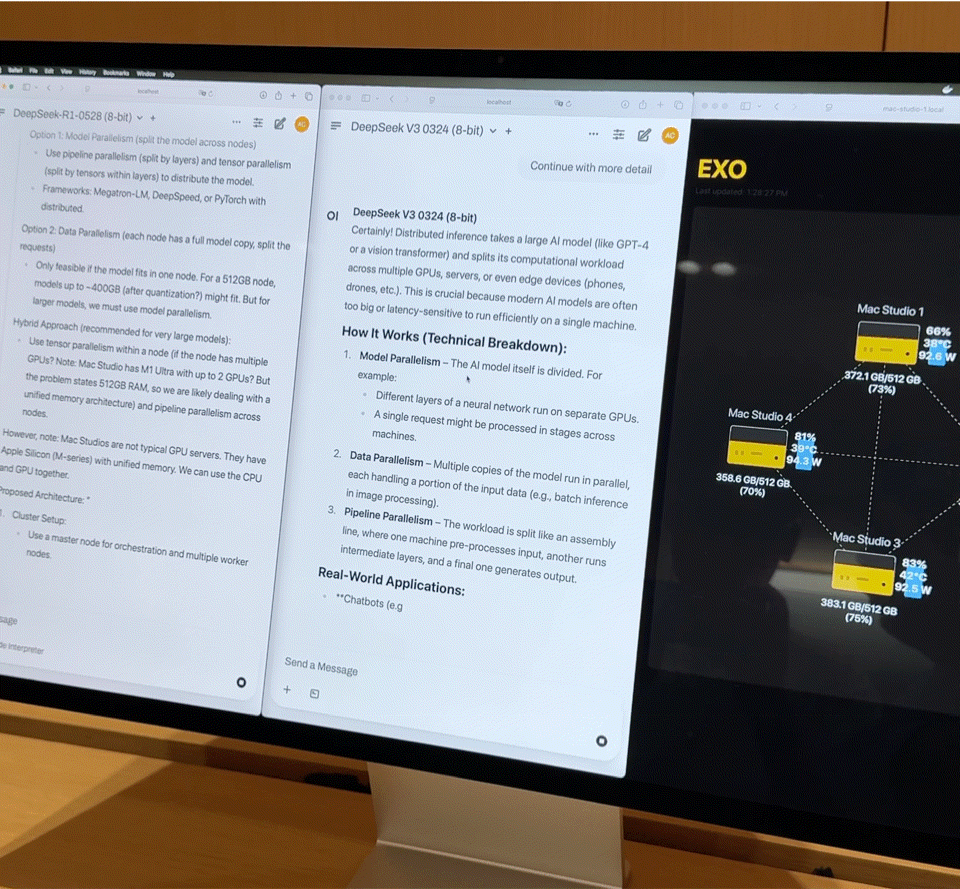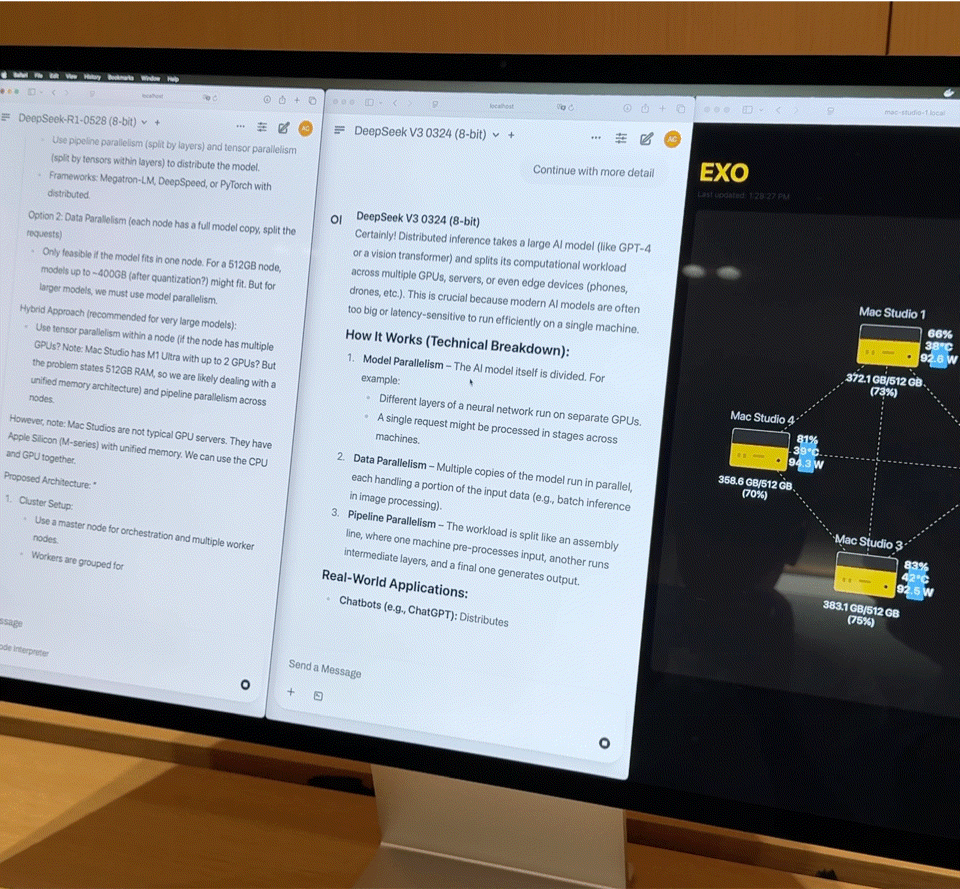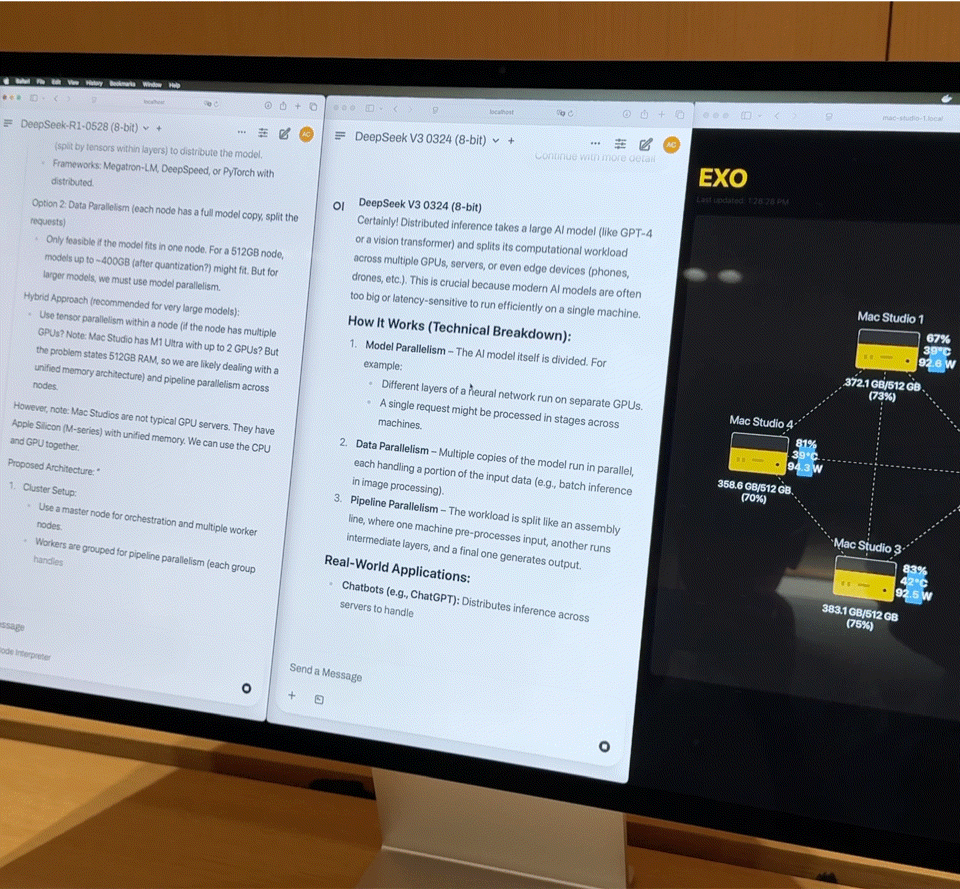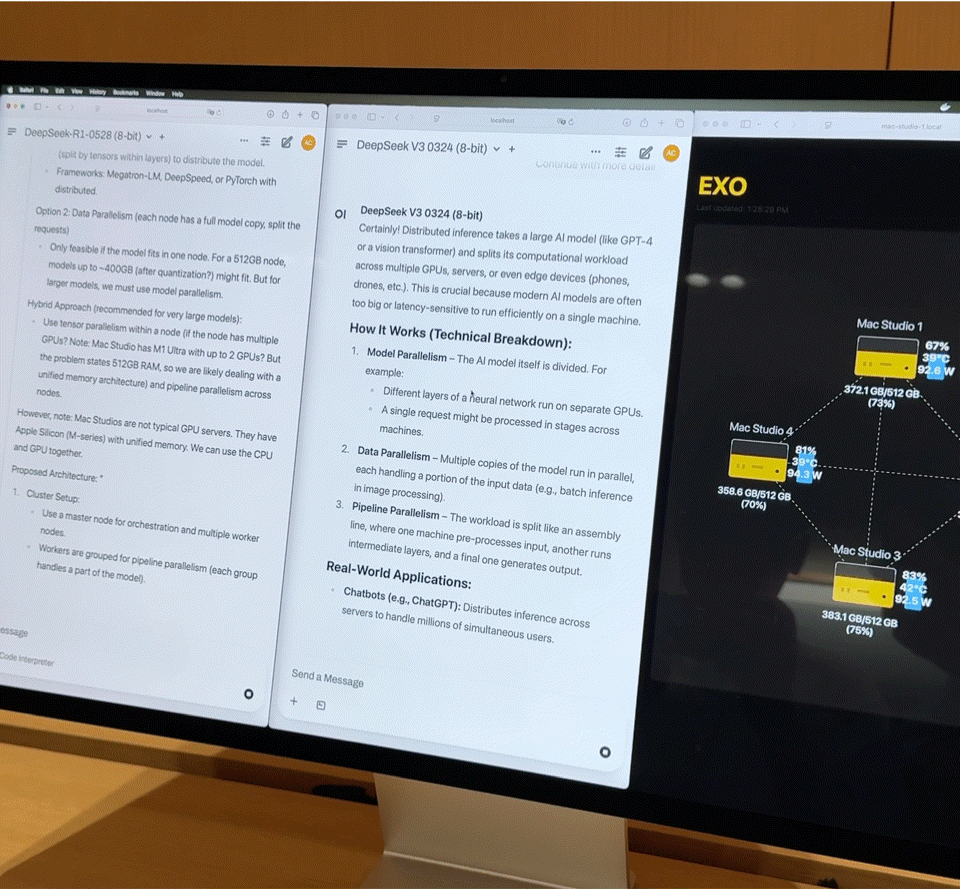
Dopo aver collegato quattro Mac Studio di fascia alta con processori M3 Ultra tramite Thunderbolt 5, i dati sulle prestazioni sono davvero impressionanti:
- CPU a 128 core (32×4)
- 240 core GPU (80×4)
- Memoria unificata da 2 TB (512 GB x 4)
- La larghezza di banda della memoria totale supera i 3 TB/s
Questa combinazione è quasi equivalente a un piccolo supercomputer domestico. Tuttavia, l'hardware è solo la base; la chiave per liberare appieno la sua potenza risiede in Exo V2, la piattaforma di scheduling di modelli distribuiti sviluppata da Exo Labs. Exo V2 suddivide automaticamente il modello in base alla disponibilità di memoria e larghezza di banda, distribuendolo sul nodo più appropriato.
Sul posto, Exo V2 ha dimostrato le seguenti capacità principali:
- Caricamento di modelli di grandi dimensioni: un modello DeepSeek completo con quantizzazione a 8 bit richiede oltre 700 GB di memoria, ben oltre la capacità di un singolo Mac Studio. Exo suddivide il modello su due Mac Studio per completare il processo di caricamento. Una volta attivato, la sua "velocità di digitazione" supera la velocità di lettura umana.
- Inferenza parallela: DeepSeek R1, anch'esso con 67 miliardi di parametri, è stato caricato su DeepSeek V3. Il sistema ha immediatamente distribuito R1 ai due dispositivi rimanenti, consentendo l'inferenza parallela di due modelli di grandi dimensioni e supportando l'interrogazione simultanea da parte di più utenti.
- Domande e risposte su documenti privati : trascina un PDF del report finanziario aziendale e il modello completerà l'integrazione delle conoscenze e le domande e risposte in locale. Non si basa su risorse cloud e i dati sono completamente privati e controllabili.
- Ottimizzazione semplificata: le aziende con migliaia di documenti interni possono eseguire ottimizzazioni locali utilizzando la tecnologia QLoRA + LoRA. Ottimizzare una singola macchina può richiedere giorni, ma grazie alle funzionalità di pianificazione dei cluster di Exo, le attività di training possono essere accelerate linearmente, riducendo significativamente i tempi.
Enorme differenza di costo
iFanr ha osservato il diagramma topologico nel backstage e ha scoperto che, anche se le quattro macchine erano sottoposte contemporaneamente a un carico elevato, il consumo energetico dell'intero sistema era sempre controllato entro i 400 W e non si sentiva quasi alcun rumore della ventola durante il funzionamento.
Per ottenere le stesse prestazioni con le soluzioni server tradizionali, è necessario installare almeno 20 schede grafiche A100. Il costo del server e delle apparecchiature di rete supera i 2 milioni di RMB, il consumo energetico raggiunge diversi kilowatt e sono necessari una sala computer e un sistema di raffreddamento indipendenti.
I chip Apple hanno inaspettatamente trovato una nuova posizione nell'onda dell'intelligenza artificiale

Il Mac Studio M3 Ultra parte da 32.999 yuan e viene fornito con 96 GB di memoria unificata, mentre la versione top di gamma da 512 GB è effettivamente costosa. Tuttavia, dal punto di vista tecnico, i vantaggi offerti dall'architettura di memoria unificata sono rivoluzionari.
Quando Apple progettò per la prima volta il chip M, era pensato principalmente per la creazione personale efficiente e a basso consumo energetico. Tuttavia, funzionalità come la memoria unificata, una GPU ad alta larghezza di banda e l'aggregazione multipath Thunderbolt hanno inaspettatamente trovato una nuova nicchia nell'era dell'intelligenza artificiale.
Le GPU tradizionali, anche le schede workstation di fascia alta, in genere dispongono di soli 96 GB di memoria video. La memoria unificata di Apple consente a CPU e GPU di condividere la stessa memoria ad alta larghezza di banda, eliminando la necessità di frequenti trasferimenti di dati tra diversi livelli di archiviazione. Questo è fondamentale per l'inferenza di modelli su larga scala.
Naturalmente, la soluzione EXO ha anche un posizionamento specifico. Non è progettata per competere direttamente con l'H100, né per addestrare la prossima generazione di GPT. Piuttosto, è pensata per risolvere problemi applicativi pratici: eseguire i propri modelli, proteggere i propri dati ed eseguire le necessarie ottimizzazioni e regolazioni.
Se H100 è il re in cima alla piramide, allora Mac Studio sta diventando il coltellino svizzero nelle mani dei team di piccole e medie dimensioni.
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
