
DeepSeek ha appena rilasciato un nuovo modello, portando i modelli piccoli e belli a nuovi livelli.
Proprio ora, DeepSeek ha reso open source un modello 3B, DeepSeek-OCR. Sebbene 3B sia di piccole dimensioni, contiene innovazioni significative nella sua modellazione.
Come tutti sappiamo, tutti gli attuali LLM si trovano ad affrontare un dilemma inevitabile quando elaborano testi lunghi: la complessità computazionale cresce in modo quadratico. Più lunga è la sequenza, maggiore è la potenza di calcolo consumata.
Così, il team di DeepSeek ha avuto un'idea brillante. Dato che una singola immagine può contenere una grande quantità di informazioni testuali utilizzando relativamente pochi token, perché non convertire il testo direttamente in un'immagine? Questa tecnica è nota come "compressione ottica", ovvero l'utilizzo di modalità visive per ridurre le dimensioni delle informazioni testuali.
L'OCR è naturalmente adatto a verificare questa idea perché esegue una conversione "visivo→testo" e l'effetto può essere valutato quantitativamente.
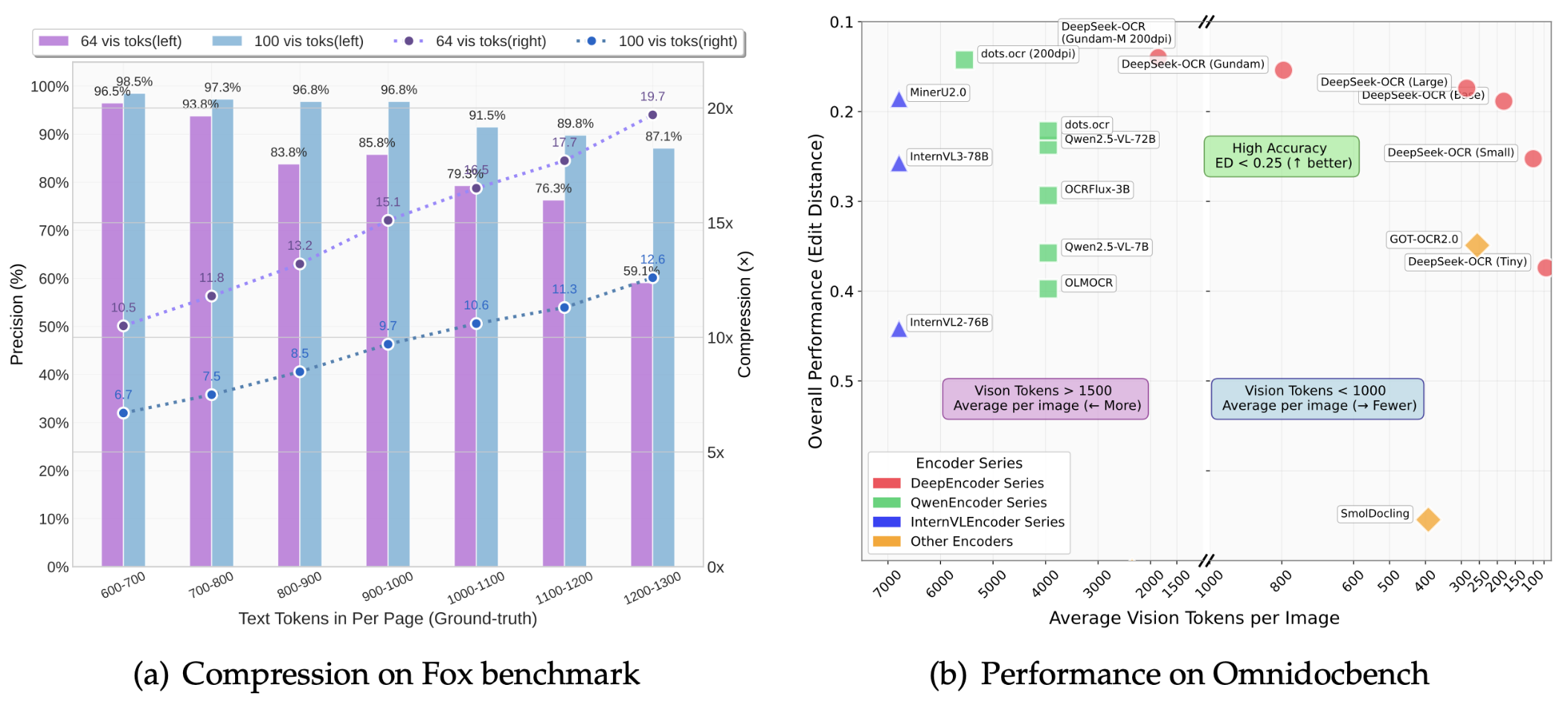
Il documento dimostra che il tasso di compressione di DeepSeek-OCR può raggiungere 10 volte e che la precisione dell'OCR può essere mantenuta a oltre il 97%.
Cosa significa questo? Significa che contenuti che in precedenza richiedevano 1.000 token di testo ora possono essere espressi con soli 100 token visivi. Anche con un rapporto di compressione 20x, la precisione rimane intorno al 60%, il che è complessivamente piuttosto impressionante.
I risultati del benchmark OmniDocBench mostrano:
- Utilizzando solo 100 token visivi, supera le prestazioni di GOT-OCR2.0 (256 token per pagina)
- Con meno di 800 token visivi, ha battuto MinerU2.0 (oltre 6.000 token per pagina in media)
In condizioni di produzione reali, una singola scheda grafica A100-40G può generare oltre 200.000 pagine di dati di training LLM/VLM al giorno. Con 20 nodi (160 A100), il numero sale a 33 milioni di pagine al giorno.
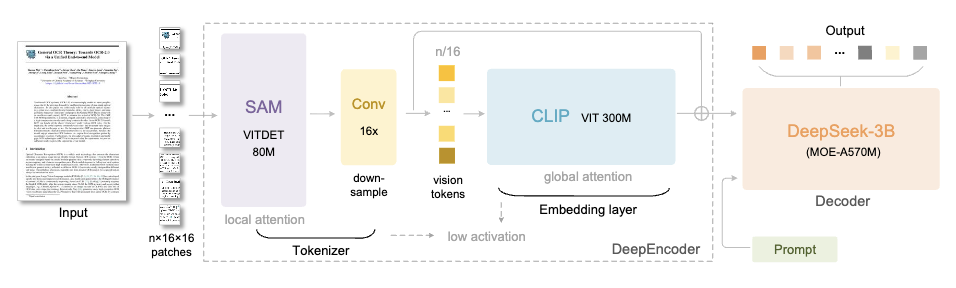
DeepSeek-OCR è costituito da due componenti principali:
- DeepEncoder (encoder): responsabile dell'estrazione e della compressione delle caratteristiche dell'immagine
- DeepSeek3B-MoE (decoder): responsabile della ricostruzione del testo da token visivi compressi
Concentriamoci sul motore DeepEncoder.
La sua architettura è molto intelligente. Collegando SAM-base (80 milioni di parametri) e CLIP-large (300 milioni di parametri), il primo è responsabile dell'"attenzione alla finestra" per estrarre le caratteristiche visive, mentre il secondo è responsabile dell'"attenzione globale" per comprendere le informazioni nel loro complesso.
Un compressore di convoluzione 16× viene aggiunto al centro per ridurre significativamente il numero di token prima di entrare nel livello di attenzione globale.
Ad esempio, un'immagine 1024×1024 verrà suddivisa in 4096 token patch. Tuttavia, dopo l'elaborazione del compressore, il numero di token che entrano nel livello di attenzione globale sarà notevolmente ridotto.
Il vantaggio è che garantisce la capacità di elaborare input ad alta risoluzione controllando al contempo il sovraccarico della memoria di attivazione.
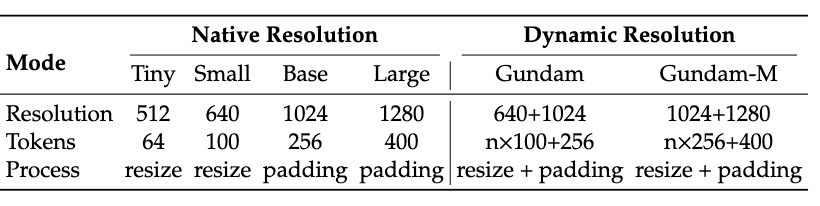
Inoltre, DeepEncoder supporta anche l'input multi-risoluzione, dalla modalità Tiny 512×512 (64 Token) alla modalità Large 1280×1280 (400 Token), tutte gestite da un unico modello.
La versione open source supporta attualmente quattro modalità: Tiny, Small, Base e Large a risoluzione nativa, oltre alla modalità Gundam a risoluzione dinamica, che massimizza la flessibilità.
Il decoder utilizza l'architettura DeepSeek-3B-MoE.
Nonostante abbia solo 3 miliardi di parametri, il modello utilizza un design Mixed-of-Experts (MoE), attivando 6 dei 64 esperti, più 2 esperti condivisi, per un totale effettivo di circa 570 milioni di parametri attivati. Questo conferisce al modello la potenza espressiva di un modello a 3 miliardi di parametri, mantenendo al contempo l'efficienza inferenziale di un modello a 500 milioni di parametri.
Il compito del decodificatore è ricostruire il testo originale a partire dai token visivi compressi, un processo che può essere appreso efficacemente dal modello linguistico compatto tramite un addestramento in stile OCR.
Anche in termini di dati, il team DeepSeek ha investito molto.
Sono stati raccolti da Internet 30 milioni di pagine di dati PDF multilingue, che coprono circa 100 lingue, di cui 25 milioni di pagine sono in cinese e inglese.
I dati sono divisi in due categorie: le annotazioni grossolane vengono estratte direttamente dal PDF utilizzando fitz, principalmente per addestrare le capacità di riconoscimento di alcune lingue; le annotazioni fini vengono generate utilizzando modelli quali PP-DocLayout, MinerU e GOT-OCR2.0 e contengono dati di alta qualità che intrecciano rilevamento e riconoscimento.
Per alcune lingue, il team ha anche sviluppato un meccanismo di "volano del modello", utilizzando prima un modello di analisi del layout con capacità di generalizzazione interlinguistica per il rilevamento, poi utilizzando i dati generati da Fitz per addestrare GOT-OCR2.0 e infine utilizzando il modello addestrato per annotare altri dati, ripetendo questo ciclo per generare infine 600.000 campioni.
Inoltre, sono presenti 3 milioni di dati di documenti Word, che migliorano principalmente le capacità di riconoscimento delle formule e di analisi delle tabelle HTML.
Per l'OCR della scena, abbiamo raccolto immagini dai set di dati LAION e Wukong e le abbiamo annotate utilizzando PaddleOCR, con 10 milioni di campioni ciascuno in cinese e inglese.

DeepSeek-OCR non solo riconosce il testo, ma offre anche funzionalità di "analisi approfondita". Con una sola parola chiave unificata, può eseguire l'estrazione strutturata di immagini complesse di vario tipo:
- Grafici: i grafici nei report di ricerca finanziaria possono essere estratti direttamente come dati strutturati
- Strutture chimiche: identificare e convertire in formato SMILES
- Geometria: Copia e analisi strutturata della geometria piana
- Immagini naturali: generare didascalie dense
Ciò ha un grande potenziale applicativo nei settori STEM, in particolare in ambiti quali chimica, fisica e matematica che richiedono l'elaborazione di un gran numero di simboli e grafici.
Qui dobbiamo menzionare un'idea creativa proposta dal team di DeepSeek: utilizzare la compressione ottica per simulare il meccanismo di dimenticanza umano.
La memoria umana si deteriora con il tempo, e i ricordi degli eventi più vecchi diventano sempre più sfocati. Il team di DeepSeek si è chiesto se l'intelligenza artificiale potesse raggiungere lo stesso obiettivo. La loro soluzione:
- Rendi il contenuto della conversazione storica oltre il round k in un'immagine
- Compressione iniziale, ottenendo una riduzione del token di circa 10 volte
- Per un contesto più ampio, continua a ridurre le dimensioni dell'immagine
- Man mano che l'immagine diventa più piccola, il contenuto diventa sempre più sfocato, fino a raggiungere l'effetto di "dimenticanza del testo".
Questo è molto simile alla curva di decadimento della memoria umana, dove le informazioni recenti mantengono un'elevata fedeltà, mentre i ricordi a lungo termine svaniscono naturalmente.
Sebbene si tratti ancora di una direzione di ricerca iniziale, se verrà realizzata rappresenterà un'enorme svolta nell'elaborazione di contesti ultra lunghi: il contesto recente mantiene un'alta risoluzione, il contesto storico richiede meno risorse di elaborazione e, in teoria, può supportare un "contesto infinito".
In breve, DeepSeek-OCR è in superficie un modello OCR, ma in realtà esplora una proposta più ampia: la modalità visiva può essere utilizzata come mezzo di compressione efficiente per l'elaborazione delle informazioni testuali LLM?
La risposta preliminare è sì, ed è stata dimostrata la capacità di compressione del token da 7 a 20 volte.
Naturalmente, il team riconosce che questo è solo l'inizio. L'OCR da solo non è sufficiente per convalidare completamente la compressione ottica contestuale. Prevedono di condurre successivi test di conversione da digitale a ottico, alternando pre-addestramento, test "ago nel pagliaio" e altre valutazioni sistematiche.
Ma in ogni caso, questo aggiunge una nuova traccia all'evoluzione di VLM e LLM.
L'anno scorso, in questo periodo, tutti stavano ancora pensando a come far sì che il modello "ricordasse di più".
Quest'anno, DeepSeek ha adottato l'approccio opposto: cosa succederebbe se il modello imparasse a "dimenticare" qualcosa? In effetti, l'evoluzione dell'intelligenza artificiale a volte riguarda la sottrazione, non l'addizione. Anche il piccolo e il bello possono raggiungere grandi risultati, e il piccolo modello 3B DeepSeek-OCR ne è la prova perfetta.
Pagina iniziale di GitHub:
http://github.com/deepseek-ai/DeepSeek-OCR
carta:
https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf
Scarica il modello:
https://huggingface.co/deepseek-ai/DeepSeek-OCR
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
