
Doubao ha appena rilasciato diversi modelli di grandi dimensioni: rendendo DeepSeek più utile, e la versione audio di Sora ha stupito il pubblico.

Devo dirlo, siamo nel 2025 e quando pongo una domanda all'intelligenza artificiale, l'esperienza è spesso polarizzata.
Risponde a domande semplici in pochi secondi, ma è come se non ricevesse alcuna risposta.
Le cose complesse richiedono una riflessione approfondita e ci vorranno più di 30 secondi per riflettere.
E con ogni risposta, l'IA continua a "bruciare" gettoni.
Per le aziende, il consumo di token si traduce direttamente in costi. Sebbene i modelli che abilitano il deep learning possano migliorare significativamente le prestazioni, la latenza aumenta, il consumo di token aumenta e i costi salgono alle stelle.
Questo è un punto dolente per l'intero settore.
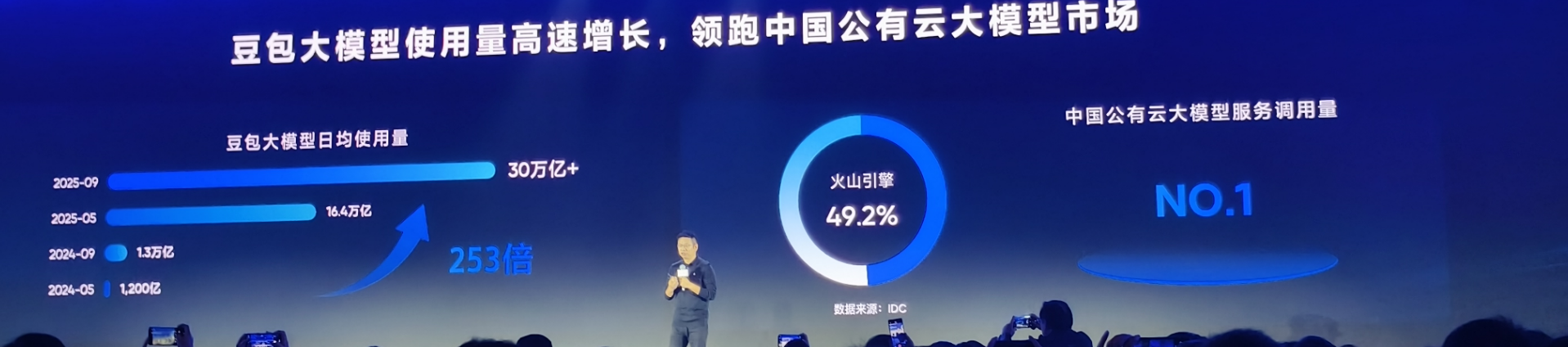
Con il crescente numero di applicazioni di intelligenza artificiale, anche il consumo di token sta aumentando vertiginosamente. Ad esempio, il modello Doubao ha visto il suo utilizzo medio giornaliero di token superare i 30 trilioni entro la fine di settembre, con un aumento di oltre l'80% rispetto alla fine di maggio. E questo rappresenta solo una parte del mercato.
Con la domanda di intelligenza artificiale in crescita a questo ritmo, la scelta è tra risparmiare denaro utilizzando modelli leggeri con prestazioni scadenti o investire per garantire le prestazioni con modelli di fascia alta. La domanda diventa: chi dovrebbe dare priorità alle prestazioni o ai costi?
Il 16 ottobre, Volcano Engine ha utilizzato quattro nuovi prodotti al FORCE LINK AI Innovation Tour di Wuhan per dirvi: solo i bambini fanno le loro scelte.
Il modello Doubao Large 1.6 supporta nativamente la regolazione della lunghezza del pensiero a 4 livelli, Doubao 1.6 Lite dimezza i costi e migliora l'effetto, e sono disponibili anche il modello di sintesi vocale Doubao 2.0 e il modello di riproduzione del suono 2.0.
Secondo un rapporto di IDC, nella prima metà del 2025, Volcano Engine ha conquistato una quota del 49,2% del mercato cinese dei servizi di cloud pubblico di grandi dimensioni, posizionandosi saldamente al primo posto.
Quale concetto?
Per ogni due aziende che utilizzano grandi modelli nel cloud, una utilizza Volcano Engine.
Nella conferenza stampa di oggi, è stato affermato che, sebbene la modalità Deep Thinking possa migliorare le prestazioni del 31%, l'utilizzo effettivo è pari solo al 18% a causa della latenza, dell'aumento dei costi e dell'impennata del consumo di token. Per dirla senza mezzi termini, le aziende vorrebbero utilizzarla, ma semplicemente non possono permettersela.
Per risolvere questo problema, il nuovo Doubao Big Model 1.6 offre quattro livelli di lunghezza di pensiero: Minimo, Basso, Medio e Alto.
Si tratta del primo modello in Cina che supporta in modo nativo "l'adeguamento graduale della lunghezza del pensiero".
Come capirlo?
È come installare un "cambio" per l'intelligenza artificiale: per le query semplici, usa la modalità Minima per risparmiare token e per i ragionamenti complessi, passa alla modalità Alta per mantenere l'effetto.
Le aziende possono bilanciare in modo flessibile effetti, latenza e costi in base allo scenario, migliorando ulteriormente l'efficienza di pensiero.
Prendiamo come esempio la modalità di pensiero di basso livello.
Rispetto alla modalità di pensiero singolo precedente all'aggiornamento, i token di output totali sono stati ridotti direttamente del 77,5% e il tempo di pensiero è diminuito dell'84,6%.
L'effetto? Rimane invariato.
Quando il costo di ogni token può essere controllato con precisione, più ne acquisti, più risparmi; più dettagliata è l'ottimizzazione, più guadagni.
Volcano Engine ha lanciato anche il modello Doubao 1.6 Lite di grandi dimensioni, più leggero e con una velocità di inferenza maggiore rispetto al modello di punta.
In termini di prestazioni, questo modello supera Doubao 1.5 pro, con un miglioramento del 14% nella valutazione degli scenari a livello aziendale.
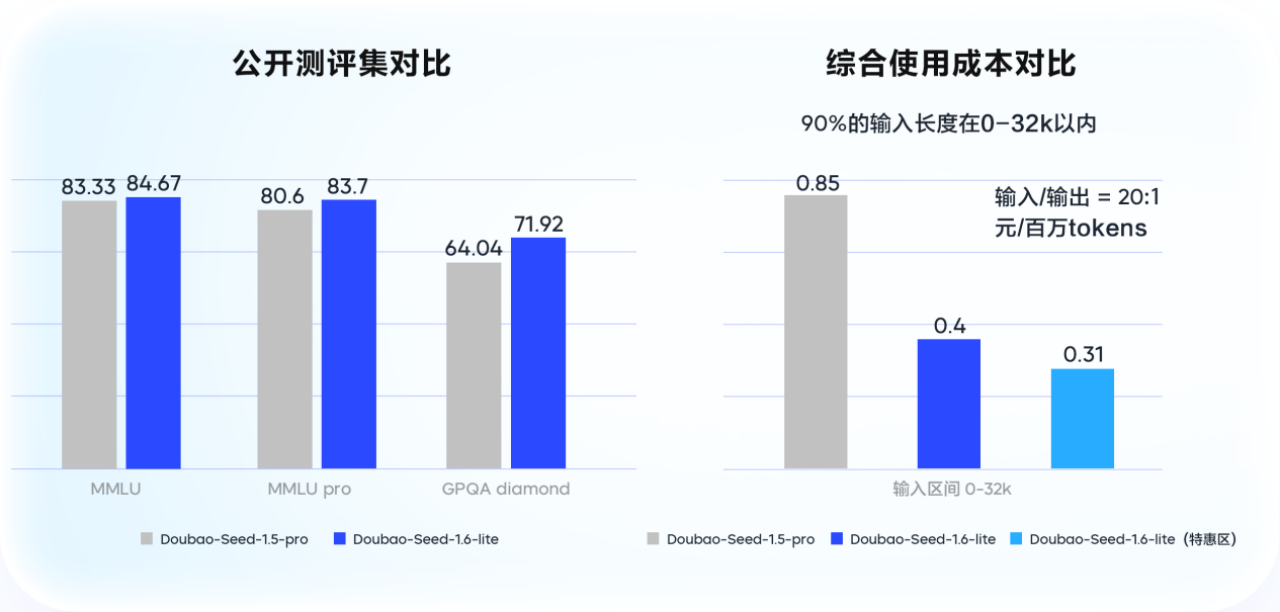
In termini di costi, nell'intervallo di input 0-32k, il costo di utilizzo complessivo è ridotto del 53,3% rispetto a Doubao 1.5 pro.
L'effetto è migliore e il costo è dimezzato.
Questo aumento della "densità del valore del token unitario" significa essenzialmente che ogni centesimo viene speso saggiamente.
Alla conferenza, Volcano Engine ha presentato anche il modello di sintesi vocale Doubao 2.0 e il modello di riproduzione del suono 2.0.
La voce sta diventando il metodo di interazione principale per le applicazioni di intelligenza artificiale.
Ma ciò che è più degno di nota della loro più forte espressione emotiva o della loro più precisa esecuzione delle istruzioni è che finalmente riescono a recitare con precisione formule complesse.
Può sembrare insignificante, ma in ambito educativo leggere ad alta voce formule e simboli complessi è sempre stato un problema arduo.
Attualmente, la precisione di lettura di modelli simili presenti sul mercato è generalmente inferiore al 50%.
Dopo l'ottimizzazione mirata dei due modelli vocali appena rilasciati, il tasso di accuratezza nella recitazione di formule complesse in tutte le materie, dalla scuola elementare alla scuola superiore, è salito al 90%.

Dietro a tutto questo c'è una nuova architettura di sintesi vocale sviluppata sulla base del modello linguistico di grandi dimensioni Doubao, che consente sia ai suoni sintetizzati che a quelli riprodotti di avere profonde capacità di comprensione semantica e di ampliare le capacità di ragionamento contestuale.
L'intelligenza artificiale non converte più il testo in suono in modo insensato, ma prima "capisce" il contenuto e poi "esprime le emozioni in modo accurato".
Gli utenti possono utilizzare il linguaggio naturale per regolare con precisione la velocità del parlato, l'emozione, la voce, il tono e i cambiamenti di stile, massimizzando il controllo della voce.
Vuoi qualcosa di più delicato? "Qualcosa di delicato."
Vuoi emozionarti di più? "Leggi con entusiasmo".
Alla conferenza stampa, Volcano Engine ha mostrato una demo molto interessante:
È stato creato un libro illustrato per bambini sul tema della protezione del moriglione di Baer a Wuhan. Il modello di creazione di immagini Doubao Seedream4.0 ha generato le illustrazioni, mentre il modello di sintesi vocale Doubao 2.0 ha fornito l'interpretazione emotiva.
Durante il processo è anche possibile controllare l'effetto di lettura in tempo reale tramite istruzioni.
Dal suo primo lancio nel maggio dello scorso anno, la famiglia di modelli vocali Doubao ha coperto sette aree principali, tra cui sintesi vocale, riconoscimento vocale, riproduzione del suono, parlato in tempo reale, interpretazione simultanea, creazione di musica e creazione di podcast, ed è stata collegata a oltre 460 milioni di terminali intelligenti.

Nella conferenza stampa di oggi, Tan Dai ha evidenziato tre principali tendenze di sviluppo nei grandi modelli globali di intelligenza artificiale:
I modelli di pensiero profondo vengono integrati in modo sempre più profondo con capacità di comprensione multimodale. I modelli video, di immagini e vocali stanno gradualmente raggiungendo livelli applicativi di livello produttivo e gli agenti complessi a livello aziendale stanno maturando.
Aspetta, fermiamoci un attimo.
Con l'emergere di sempre più modelli, come possiamo scegliere il modello più conveniente in base a esigenze specifiche?
Questa potrebbe essere una domanda che spinge molte aziende a riflettere.
Volcano Engine ha lanciato Smart Model Router, la prima soluzione in Cina per la selezione intelligente dei modelli.
A partire da oggi, gli utenti possono selezionare la funzione "Smart Model Routing" su Volcano Ark.
Questa funzione supporta tre modalità: "Modalità bilanciata", "Modalità priorità effetti" e "Modalità priorità costi" e può selezionare automaticamente il modello più appropriato per le richieste di attività.

Perché è necessario?
Perché compiti diversi hanno requisiti completamente diversi per la "densità di valore" dei token.
Il sistema di assistenza clienti risponde alla domanda "Come restituire un prodotto?" con un modello semplificato.
Tuttavia, quando si tratta di diagnosi medica e analisi dei casi, è necessario utilizzare il modello più solido.
Sebbene il consumo di token sia lo stesso, la densità di valore è molto diversa.
L'essenza del routing intelligente dei modelli è lasciare che sia l'intelligenza artificiale a decidere autonomamente "quanti token vale la pena bruciare per questa attività".
Attualmente, il routing intelligente del modello Volcano Engine supporta già una varietà di modelli tradizionali, tra cui Doubao, DeepSeek, Qwen e Kimi.
Prendiamo come esempio DeepSeek, i dati misurati:
Nella modalità effect-first, l'effetto del modello dopo il routing intelligente è migliorato del 14% rispetto all'utilizzo diretto di DeepSeek-V3.1.
In modalità cost-first, pur ottenendo risultati simili a DeepSeek-V3.1, il costo complessivo del modello può essere ridotto fino al 70%.
Quando la selezione del modello stesso viene affidata all'intelligenza artificiale, si crea un ciclo di feedback positivo nell'intero settore:
Le capacità più solide del modello sbloccano nuovi scenari applicativi → L'esplosione di nuove applicazioni fa aumentare il consumo di token → L'aumento del consumo impone un'ottimizzazione continua del routing intelligente → L'ottimizzazione del routing riduce ulteriormente i costi unitari → Costi inferiori liberano una maggiore elasticità della domanda → Il rilascio della domanda a sua volta fa aumentare il consumo complessivo.
Questo ci ricorda il 1882, quando Edison costruì la prima centrale elettrica commerciale al mondo. Nessuno avrebbe potuto prevedere che l'unità di misura "kilowattora" avrebbe dato vita all'intero sistema industriale moderno.
Oggi i token stanno diventando i “kilowattora” dell’era dell’intelligenza artificiale.
L'elenco del "Trillion Token Club" recentemente annunciato da OpenAI e i 130 trilioni di token bruciati da Google ogni mese confermano entrambi il vigoroso aumento della produttività.
Naturalmente, un buon modello è solo il punto di partenza e una buona esperienza è l'obiettivo finale.
Quando poni una domanda all'IA, non dovresti preoccuparti se è veloce o valida. Il pensiero a livelli consente risposte immediate e accurate a domande semplici, fornendo al contempo ragionamenti approfonditi ed efficienza per domande complesse.
Grazie al routing intelligente non dovrai più preoccuparti di quale modello scegliere: l'intelligenza artificiale troverà quello più adatto.
Utilizzando il linguaggio naturale, è possibile controllare con precisione il modello vocale, anziché essere sopraffatti da una moltitudine di parametri. Ogni iterazione di queste tecnologie ha un unico obiettivo finale: renderle accessibili e, soprattutto, efficaci per gli utenti.
Forse è così che dovrebbe essere l'intelligenza artificiale.
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
