
La tirata cinese di Musk e Ultraman: il video dell’IA si trasforma finalmente da “giocattolo” in uno “strumento”

Se oggigiorno navighi sui social media, troverai video virali con immagini straordinarie, spesso prodotte dall'intelligenza artificiale. Tuttavia, come creatore, oltre a creare un'"attrazione", c'è un problema che va oltre le immagini e che non è stato affrontato adeguatamente.
Il problema è il dialogo.
Ad esempio, se chiedo all'IA di generare una bella scena di pioggia, non è difficile. Ma se chiedo all'IA di generare una scena di rottura sotto la pioggia con trama e dialoghi, e i dialoghi devono essere in cinese autentico, è un compito molto complicato.
Il contenuto generato dall'intelligenza artificiale è o una vera e propria "pantomima" che richiede al creatore di sincronizzare le labbra e doppiare in una fase successiva; oppure può parlare, ma la voce e l'intonazione sono innaturali, piene di "sensazioni uomo-macchina" e "tono di traduzione", il che rovina all'istante la trama che dovrebbe essere triste.
Questa è anche una delle sfide più grandi dell'attuale generazione di video basati sull'intelligenza artificiale: come gestire i dialoghi, in particolare quelli cinesi, con emozioni complesse.
Si può affermare che la capacità dell'IA di gestire conversazioni in cinese naturali e fluenti sia la chiave per trasformarsi da un giocattolo "per divertimento" in un vero e proprio strumento di produttività.
Il modello video MuseSteamer 2.0 di Baidu, rilasciato oggi, sembra risolvere questo problema fondamentale. La sua caratteristica più sorprendente è che si tratta della prima tecnologia al mondo di generazione integrata di audio e video in cinese. Basata su un corpus di testi cinese, la tecnologia è in grado di generare video di conversazioni in cinese con audio e video sincronizzati, movimenti labiali accurati ed emozioni naturali in un unico passaggio.

Per verificare se risolve davvero i problemi dei creatori o se si tratta solo di una dimostrazione tecnica nel video promozionale, ho deciso di ignorare i casi ufficiali selezionati (Demo) e di progettare alcune scene "difficili" più vicine alle esigenze creative quotidiane delle persone comuni, per esplorarne personalmente la realtà.
Indirizzo dell'esperienza: https://huixiang.baidu.com/
Da un'immagine a un confronto sonoro
Questa volta Baidu Steam Engine offre modelli di 4 generazioni, tutti in grado di generare un video da un'immagine, ovvero Steam Engine 2.0 turbo, pro, lite e versione audio; modelli diversi consumeranno un numero diverso di punti e gli utenti gratuiti possono ottenere una quantità limitata di valore di immaginazione (punti) effettuando l'accesso ogni mese.
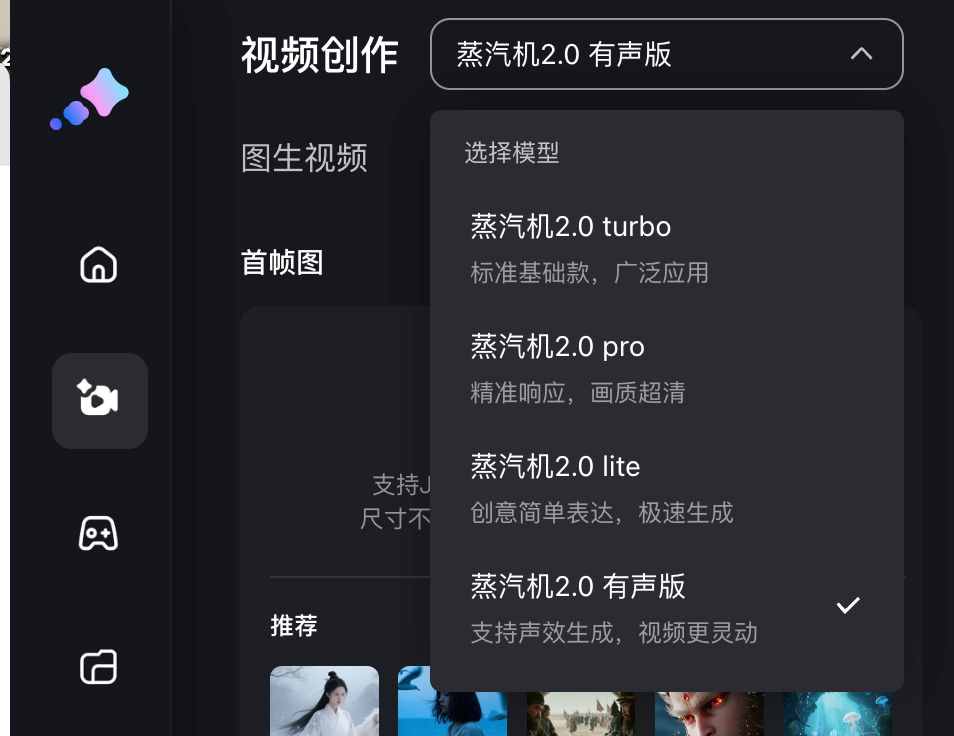
La versione audio può generare video da 5 o 10 secondi, mentre la Turbo e le altre tre versioni sono da 5 secondi. In termini di pixel, ad eccezione della versione Pro che supporta 1080p, le altre tre versioni offrono una qualità dell'immagine ad alta definizione a 720p.
Gli forniamo direttamente un'immagine e poi seguiamo le istruzioni nella pagina di generazione del video per inserire il contenuto del video e le linee tematiche che desideri generare; per un video di 5 secondi, le linee devono essere controllate entro 20 parole, mentre per un video di 10 secondi, il numero di parole deve essere controllato entro 35 parole.

▲ Abbiamo caricato una foto di Musk e Ultraman, con il seguente messaggio: Due persone stanno discutendo tra loro. La persona a sinistra dice: "L'IA che hai creato non ha alcun profitto". La persona a destra dice: "Il tuo marketing non ha alcun profitto". Generato da Steam Engine 2.0 Versione audio.
Innanzitutto, Musk e Ultraman nelle foto statiche sono guidati in modo naturale, le loro espressioni facciali e i movimenti del corpo sono piuttosto fluidi e sostanzialmente coerenti con le immagini caricate. La capacità di base della generazione di immagini in video è ancora molto solida.
Ancora più importante, la performance dei dialoghi è davvero ai vertici della sincronizzazione labiale cinese. I movimenti labiali riproducono fedelmente la pronuncia di parole come "bottom line" e "marketing", senza ritardi o disallineamenti evidenti.

▲ Un primo fotogramma dei goblin della Montagna Langlang, accompagnato da un segnale: Nel fotogramma, un goblin cinghiale, con in mano un forcone, guarda con aria di attesa il corpulento Coach Bear accanto a lui. Battute: (0-5 secondi) Il goblin cinghiale, con in mano un forcone, dice: "Coach, lucidiamo la nostra armatura. Combatteremo con più forza!" (5-10 secondi) Il corpulento Coach Bear lo guarda dall'alto in basso e lo interrompe impaziente: "Chi ha tempo? Prima taglia mille frecce per me!"
Durante la conferenza stampa, Baidu ha specificamente affermato che questa è la logica di generazione alla base dell'" integrazione audio e video ". Il suono e l'immagine vengono concepiti simultaneamente, anziché essere abbinati in un secondo momento. Durante l'addestramento, l'immagine e il suono vengono inseriti in un unico modello per un apprendimento sincrono.
Esiste inoltre una tecnologia pionieristica chiamata "Latent Multi Modal Planner"; la multimodalità è facile da comprendere, in quanto si riferisce a testo, immagini e audio, e "latente" è un termine del deep learning che si concentra sull'apprendimento di caratteristiche latenti. Questa tecnologia può pianificare autonomamente più identità di personaggi, linee e logiche di interazione nello spazio di generazione latente.
In parole povere, possiamo immaginarlo come un regista integrato nell'intelligenza artificiale. Quando riceve l'istruzione di "lasciare che due persone litighino", non lascerà stupidamente che i due parlino contemporaneamente, ma pianificherà autonomamente il copione della lite.
Abbiamo anche provato alcuni dialetti, come il cinese nord-orientale, per vedere se non ci sarebbero stati problemi nelle conversazioni tra più persone.

▲ Suggerimento: la donna vestita di blu sul lato sinistro dello schermo sussurra velocemente e freddamente nel dialetto del Nord-Est: "Sorella, la sincerità è il nostro carbone, ma è anche il fuoco che ci brucia fino alla morte"; la donna vestita di viola e rosa sul lato destro dello schermo risponde con decisione nel dialetto del Nord-Est: "Allora perché no, bruciarlo in modo più pulito"; generato dalla versione audio di Steam Engine 2.0.
Far parlare Zhen Huan e Shen Meizhuang in dialetto nord-orientale all'interno del modello audio e video integrato è stato un po' impegnativo, ma le espressioni dei personaggi, i movimenti delle labbra, i movimenti degli orecchini e dei copricapi sono stati resi in modo molto naturale. Anche le voci cinesi erano molto dettagliate, il che, a mio avviso , dimostra un profondo adattamento al contesto cinese.
C'è anche questa classica immagine meme, che alla fine non è "Vieni ad assaggiare la mia carne fresca".

Uno screenshot dal cortometraggio "Wan Wan Wo Xiang". La didascalia recita: Tang Sanzang, con indosso un cappello rosso, punta il dito contro il naso dell'uomo con le corna e dice con rabbia: "Vuoi ancora assaggiare la mia carne fresca? Assolutamente no!"
Baidu Steam Engine affronta con precisione il problema creativo di consentire a una singola immagine di parlare e recitare una scena. Semplifica il processo multi-strumento, precedentemente macchinoso, in un'unica operazione "un'immagine + una frase". Questo libera senza dubbio la produttività per scenari come la creazione di meme, il dialogo umano virtuale, la condivisione di conoscenze e la produzione di sketch.
C'è ancora molta strada da fare prima di poter davvero eguagliare le performance di doppiaggio dei video di recente successo "Empresses in the Palace" e "Let the Bullets Fly". Tuttavia, dato lo stato attuale della tecnologia di generazione video basata sull'intelligenza artificiale, credo che sia solo questione di tempo prima che l'intelligenza artificiale possa esprimere emozioni umane più sfumate e contrastanti. Dopotutto, il modello Steam Engine 1.0 è stato rilasciato all'inizio del mese scorso.
Può gestire movimenti di telecamera e scene di grandi dimensioni?
Oltre alla prima generazione integrata di audio e video con voce a due giocatori nelle scene cinesi, un altro miglioramento del Baidu Steam Engine 2.0 è la qualità delle immagini a livello cinematografico e il movimento complesso della telecamera a livello master .
Nei precedenti video conversazionali, emozioni, espressioni e generazione facciale 3D hanno dimostrato un'espressione realistica e dettagliata dei personaggi. Abbiamo continuato a testare transizioni e inquadrature vuote, comuni in spot pubblicitari e cortometraggi, che rappresentano un altro requisito essenziale per i video di intelligenza artificiale, oltre alla conversazione.

▲ Fornisci la prima immagine del fotogramma con il prompt: Un'inquadratura che inizia con un primo piano di un libro aperto su una scrivania, si solleva lentamente e infine si blocca sulla scena della strada piovosa fuori dalla finestra; generata da Steam Engine 2.0 Pro.
A giudicare dal video risultante, la Steam Engine ha seguito le istruzioni alla perfezione. Tutti i movimenti della telecamera – primi piani, riprese, fermi immagine – sono stati eseguiti con straordinaria fluidità, senza problemi di mosso o incomprensioni delle istruzioni. Ciò dimostra la solida conoscenza della terminologia fotografica.
Quando l'intelligenza artificiale impara il cinese autentico, arriva una nuova svolta nella creazione video
Dopo questo test, penso che il posizionamento di Baidu Steam Engine 2.0 sia molto chiaro: non è concepito per essere un modello onnicomprensivo in stile Sora, ma ha scelto un percorso più pragmatico: utilizzando il "dialogo cinese" come punto di svolta fondamentale, ha fatto evolvere il video basato sull'intelligenza artificiale da un interessante "giocattolo" a uno "strumento" che può essere trasmesso come film.
Evita la competizione interna basata semplicemente sulla qualità e sulla lunghezza delle immagini e dedica più energie alla risoluzione del problema più critico e più localizzato: far sì che i video dell'IA "parlino cinese" davvero e lo parlino meglio delle persone reali.
Questa trasformazione da "giocattolo" a "strumento" è stata verificata in ambiti creativi e commerciali reali.
Yao Qi, un regista di effetti visivi di calibro hollywoodiano, ha lavorato a film come "2012", "Matrix 3" e "Transformers 3". Ha anche creato gli iconici effetti d'azione Guzheng nel dramma fantascientifico cinese "Il problema dei tre corpi". Questa volta, ha utilizzato il motore a vapore Baidu per creare un cortometraggio fantascientifico di alta qualità con oltre 40 inquadrature con effetti speciali complessi ed elaborati, ciascuna generata tre volte per un totale di oltre 120 clip, il tutto per soli 330,6 yuan.

▲ Video della conferenza stampa "Viaggio di ritorno a casa"
Quando il costo di produzione visiva di un cortometraggio, che prima richiedeva un budget di milioni di yuan, viene compresso a un livello inimmaginabilmente basso, ciò che viene sovvertito non è solo il budget, ma anche la soglia e i diritti di creazione.

Non si tratta solo di ridurre i costi; si tratta di passare dalla creazione di una clip accattivante alla narrazione di una storia completa. Quando i grandi effetti visivi possono essere integrati perfettamente con la narrazione e i dialoghi, l'intelligenza artificiale si evolve davvero da un semplice plug-in per effetti speciali a uno strumento altamente efficiente per i creatori.
Negli scenari di marketing di marca, questo modello stravolge anche il processo di produzione video convenzionale. Ad esempio, Yili Beichang aveva bisogno di produrre un video promozionale per il suo latte di capra in polvere, intitolato "Una pecora attraversa il mare per vederti". I metodi di produzione tradizionali richiedono in genere dalle quattro alle sei settimane e le riprese prevedevano la rappresentazione del magico viaggio di "Little Lamb Shasha" a bordo di una mongolfiera, tra praterie olandesi e fabbriche high-tech. Questo approccio era costoso e impegnativo.

Questa volta, il team di produzione ha utilizzato una macchina a vapore per realizzare queste scene fantastiche, che sarebbero state difficili da ottenere con l'azione dal vivo, attraverso un rendering stilizzato basato sull'intelligenza artificiale. Ancora più importante, l'intelligenza artificiale ha integrato perfettamente nella narrazione punti di forza chiave come l'approvvigionamento di latte olandese e una formula probiotica, riducendo il ciclo di produzione a pochi giorni. Le immagini risultanti sono rimaste fluide ed esprimevano perfettamente la filosofia del marchio.
Che si tratti di creatori professionisti o di innumerevoli creatori e marchi di piccole e medie dimensioni, tutti hanno sostanzialmente acquisito una "cyberpenna". Con solo "un'immagine e una frase", puoi dare vita a un Guerriero di Terracotta statico e fare una telefonata, o far chiacchierare Zhang Fei con te mentre ricami. Questa barriera alla creatività in via di estinzione sta rimodellando l'equazione dei costi e le regole competitive del settore dei contenuti.
Certo, non è un perfetto coltellino svizzero . Attualmente, presenta delle limitazioni sulla lunghezza dei video che può generare per effetti puramente visivi e non dialoghi, e la scelta di suoni e stili potrebbe essere più ricca.
Tuttavia, nell'era dei prodotti di intelligenza artificiale in rapida evoluzione, non esiste un prodotto veramente perfetto. Piuttosto, i prodotti più efficaci sono quelli che possono essere implementati più rapidamente per soddisfare le reali esigenze degli utenti. Il motore a vapore di Baidu ha evitato la vanità di una corsa agli armamenti tecnologici, scegliendo invece un approccio più pragmatico e orientato al mercato. È come un martello concentrato a piantare chiodi. Sebbene non possa piallare il legno, raggiunge la perfezione nel compito di piantare chiodi.
Guardando il personaggio generato dall'intelligenza artificiale parlare liberamente davanti a me, senza percepire nulla di meccanico, non posso fare a meno di provare un'ondata di meraviglia. Gli strumenti alla fine diventeranno invisibili, ma la creatività brillerà sempre. Ciò che la macchina a vapore ha fatto è stato restituire il sogno della regia, un tempo incredibilmente costoso e riservato a pochi eletti, a chiunque avesse qualcosa da dire.
Ora non ci mancano più buoni strumenti, ma ci mancano idee nuove; e le idee originali nascono da tentativi ripetuti.
Testo|Li Chaofan e Zhang Zihao
Per visualizzare il video nell'articolo, fare clic su questo collegamento: https://mp.weixin.qq.com/s/cy7m7e97AVVo5VqUcnS0_w
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
