
OpenAI ha appena rilasciato due modelli open source! Possono essere eseguiti su telefoni cellulari e laptop, e gli ex studenti dell’Università di Pechino sono in prima linea in questo progetto.

Dopo cinque anni, OpenAI ha appena rilasciato ufficialmente due modelli linguistici ponderati open source: gpt-oss-120b e gpt-oss-20b. L'ultima volta che hanno reso open source un modello linguistico è stato GPT-2 nel 2019.
OpenAI è veramente aperto.
Oggi, anche il mondo dell'intelligenza artificiale è pieno di polvere da sparo. OpenAI ha reso open source gpt-oss, Anthropic ha lanciato Claude Opus 4.1 (report dettagliato di seguito) e Google DeepMind ha rilasciato Genie 3. I tre giganti hanno sfoderato le loro carte vincenti lo stesso giorno, inscenando una battaglia tra dei.
Il CEO di OpenAI, Sam Altman, ha espresso il suo entusiasmo sui social media: "GPT-OSS è stato rilasciato! Abbiamo creato un modello aperto con prestazioni di livello O4-mini, che può essere eseguito su laptop di fascia alta. Sono molto orgoglioso del team; questa è una grande vittoria tecnica".
I punti salienti del modello sono riassunti come segue:
- gpt-oss-120b: un modello aperto di grandi dimensioni adatto a casi d'uso di produzione, generici e ad alta inferenza, in esecuzione su una singola GPU H100 (117 miliardi di parametri, 5,1 miliardi di attivazioni), progettato per essere eseguito in data center e su desktop e laptop di fascia alta
- gpt-oss-20b: un modello aperto di medie dimensioni per casi d'uso a bassa latenza, locali o specializzati (21B parametri, 3.6B parametri di attivazione) che può essere eseguito sulla maggior parte dei desktop e laptop.
- Licenza Apache 2.0: libera da sviluppare, senza restrizioni copyleft o rischi di brevetto, ideale per la sperimentazione, la personalizzazione e la distribuzione commerciale.
- Inferenza configurabile: regola facilmente l'intensità dell'inferenza (bassa, media o alta) in base al tuo caso d'uso specifico e ai requisiti di latenza. Catena di inferenza completa: ottieni l'accesso completo al processo di inferenza del modello per un debug più semplice e una maggiore affidabilità dell'output. Questa funzionalità non è destinata alla visualizzazione da parte degli utenti finali.
- Ottimizzabile: grazie alla regolazione fine dei parametri, il modello può essere completamente personalizzato per soddisfare le esigenze di utilizzo specifiche dell'utente.
- Funzionalità dell'agente intelligente: sfrutta le funzionalità native del modello per eseguire chiamate di funzioni, navigazione web, esecuzione di codice Python e output strutturato.
- Quantizzazione MXFP4 nativa: i modelli vengono addestrati utilizzando la precisione MXFP4 nativa per i livelli MoE, consentendo al modello gpt-oss-120b di essere eseguito su una singola GPU H100 e al modello gpt-oss-20b di essere eseguito su 16 GB di memoria.
OpenAI finalmente rende open source la sua intelligenza artificiale, ma questa volta è davvero diverso
A giudicare dalle specifiche tecniche, questa volta OpenAI fa davvero sul serio. Non si è limitata a proporre un modello open source ridotto per cavarsela, ma ha invece lanciato un progetto genuino con prestazioni simili a quelle del suo fiore all'occhiello closed source.
Secondo la presentazione ufficiale di OpenAI, gpt-oss-120b ha un totale di 117 miliardi di parametri e 5,1 miliardi di parametri di attivazione. Può essere eseguito su una singola GPU H100 e richiede solo 80 GB di memoria. È progettato per ambienti di produzione, applicazioni generiche e casi d'uso con elevati requisiti di inferenza. Può essere implementato nei data center ed eseguito su desktop e laptop di fascia alta.
In confronto, gpt-oss-20b ha 21 miliardi di parametri totali e 3,6 miliardi di parametri di attivazione. È ottimizzato per casi d'uso a bassa latenza, localizzati o specializzati e richiede solo 16 GB di memoria per funzionare, il che significa che la maggior parte dei desktop e laptop moderni può gestirlo.
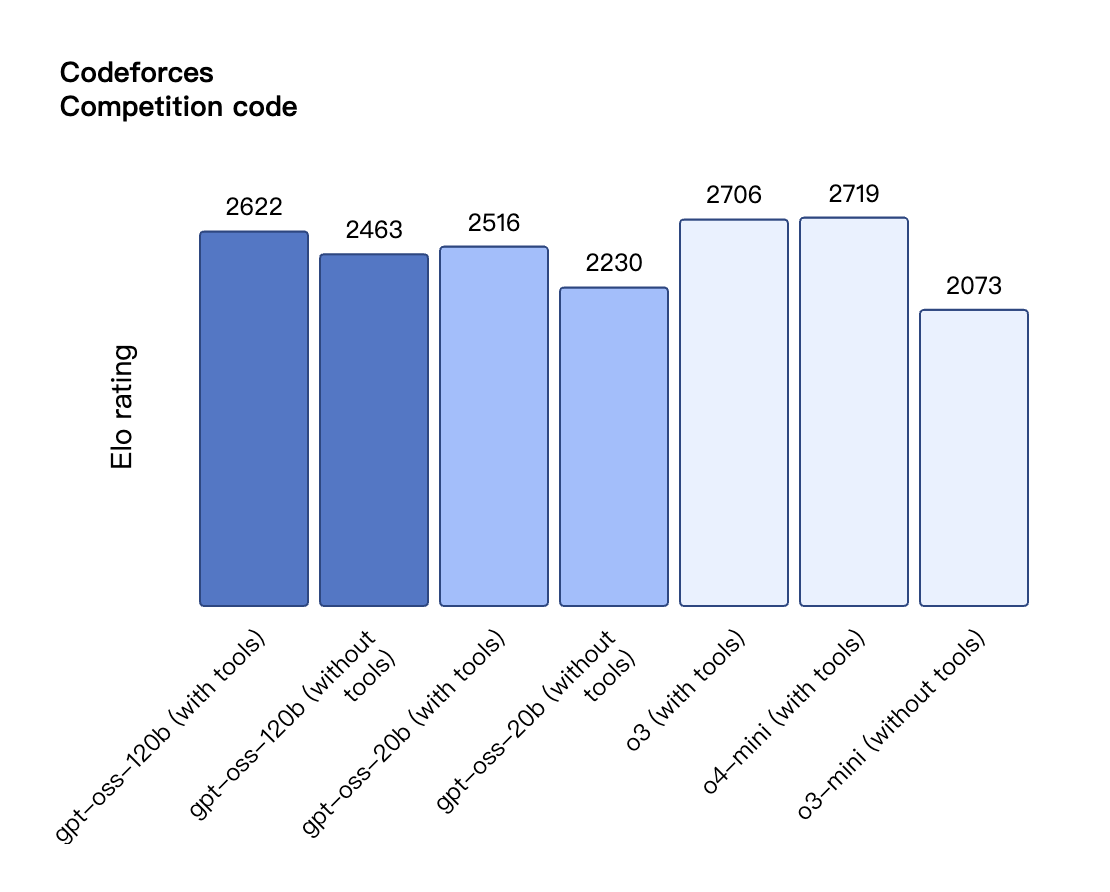
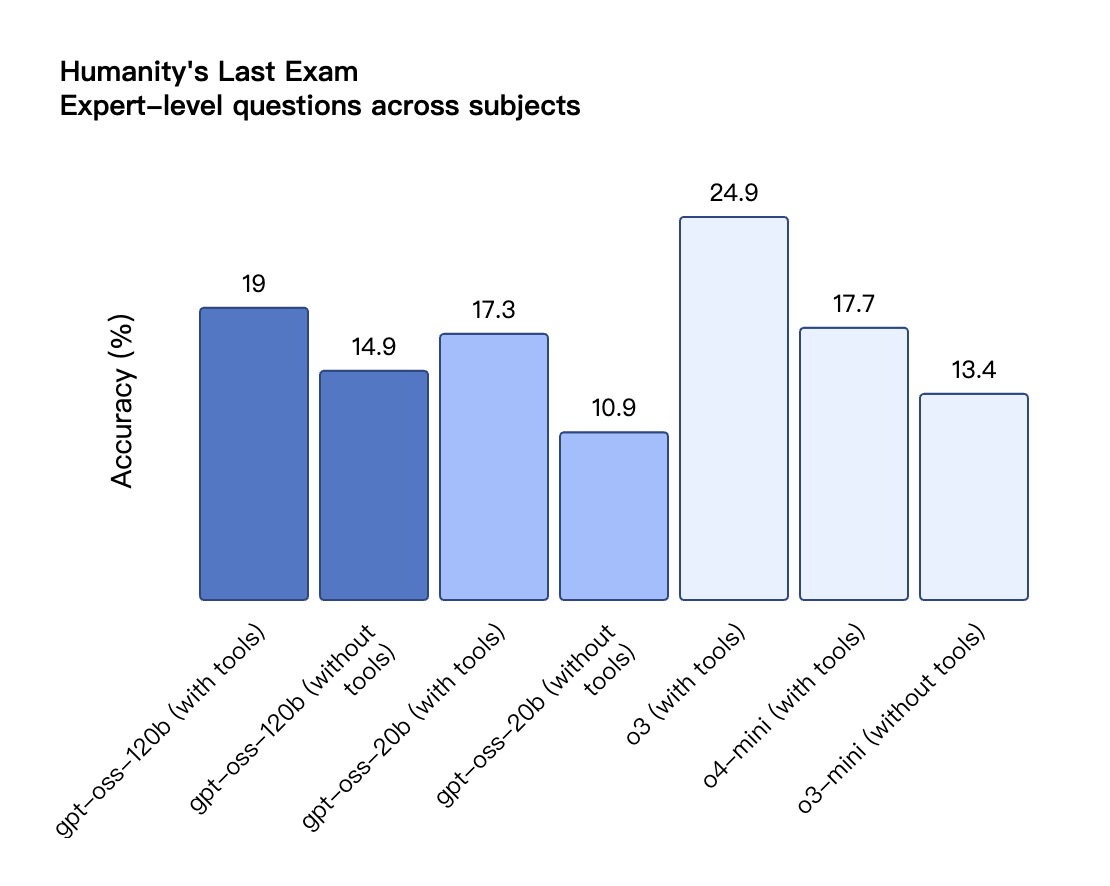
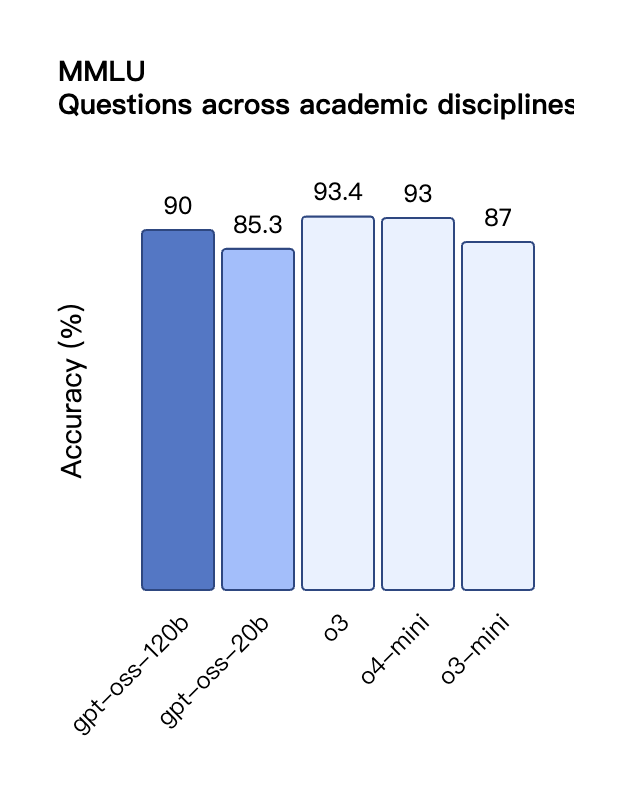
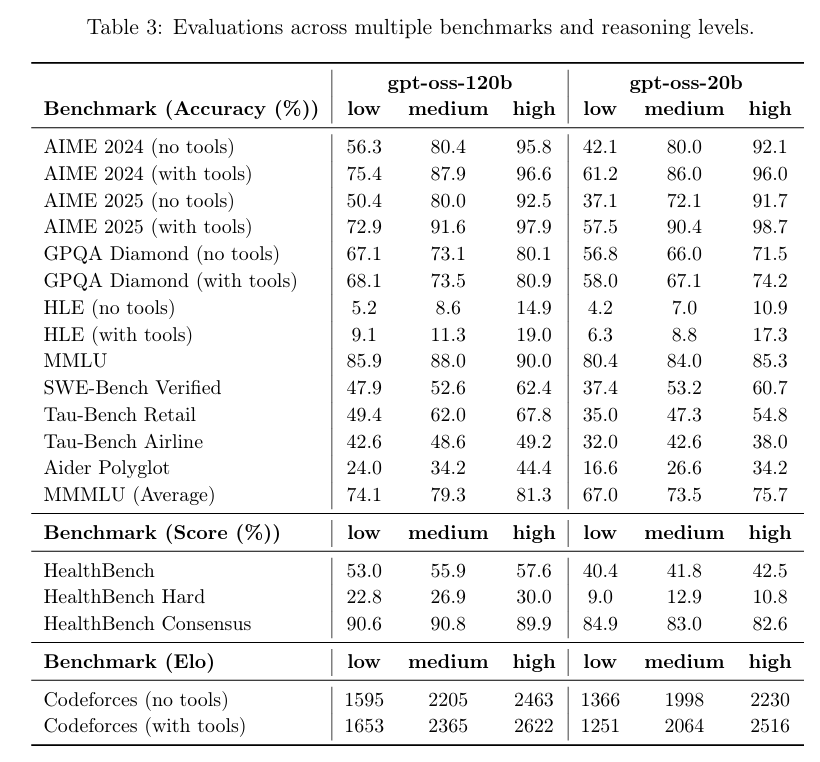
Secondo i risultati di benchmark pubblicati da OpenAI, gpt-oss-120b ha superato o3-mini ed è stato alla pari con o4-mini nel test Codeforces di programmazione competitiva; ha inoltre superato o3-mini e si è avvicinato al livello di o4-mini nei test MMLU e HLE di capacità generale di risoluzione dei problemi.
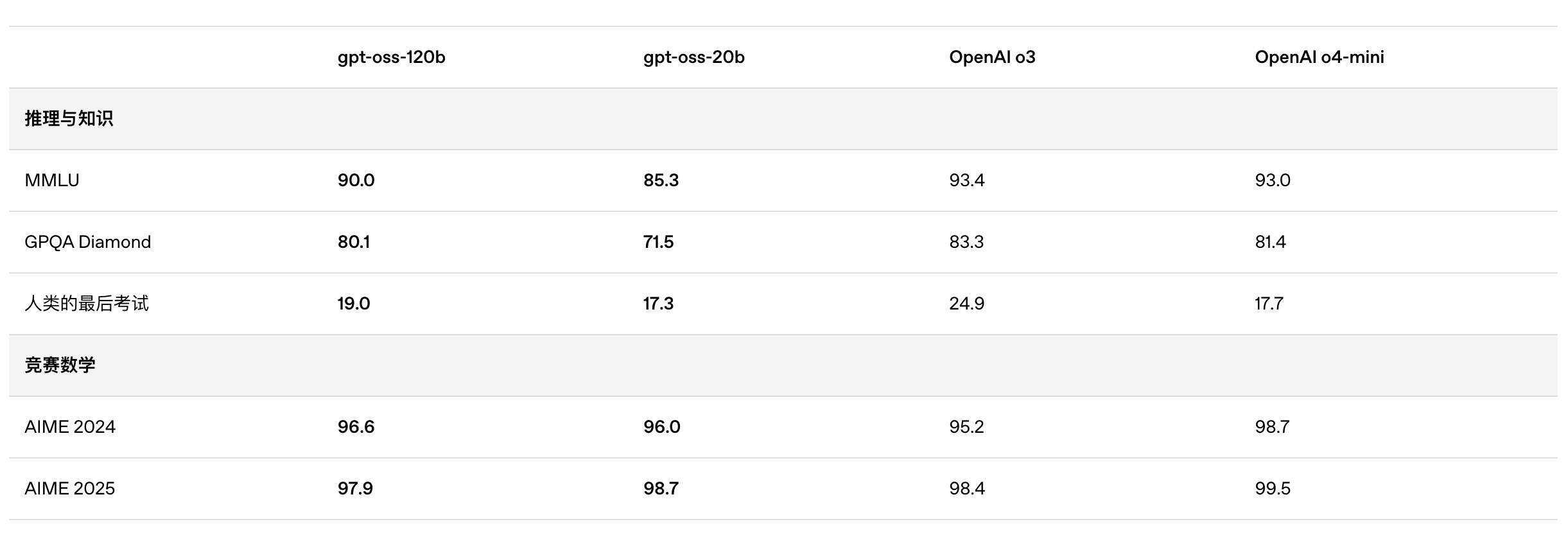
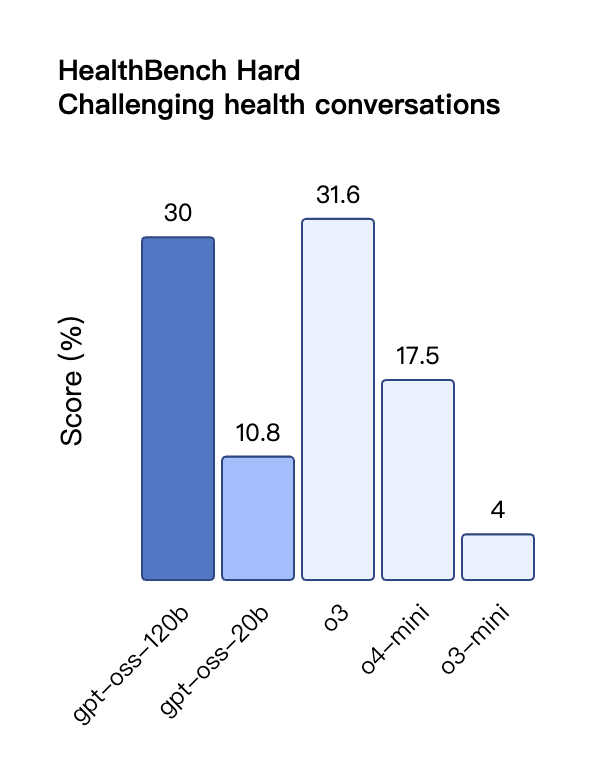
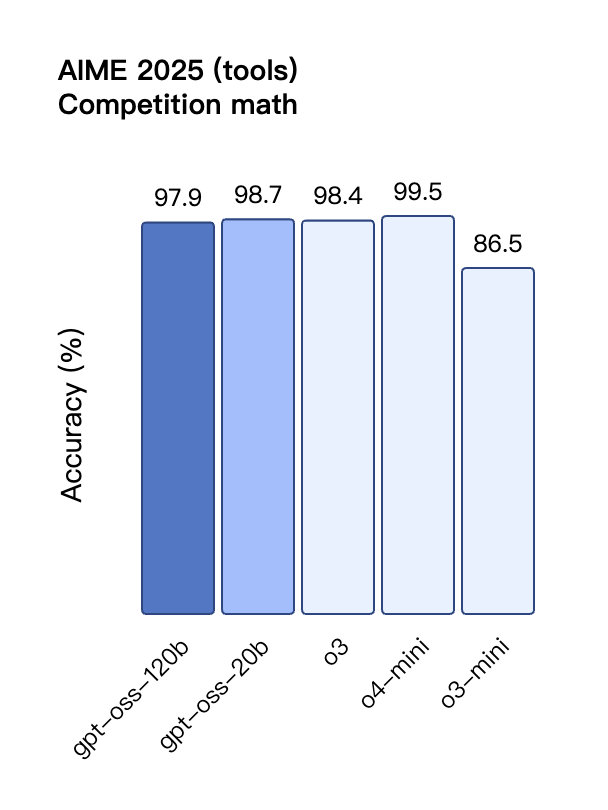
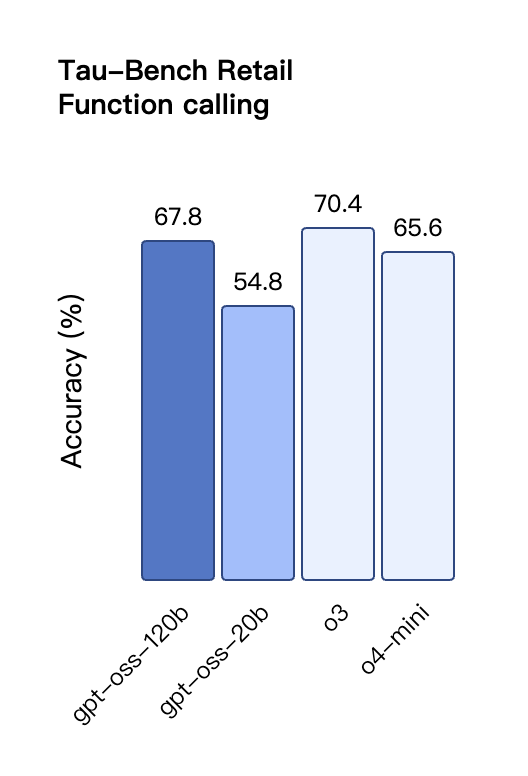
Anche nella valutazione TauBench delle chiamate degli strumenti, gpt-oss-120b ha ottenuto buoni risultati, superando persino modelli closed-source come o1 e GPT-4o; nel test HealthBench delle query relative alla salute e nei test AIME 2024 e 2025 di matematica competitiva, le prestazioni di gpt-oss-120b hanno addirittura superato quelle di o4-mini.
Nonostante le dimensioni ridotte dei parametri, gpt-oss-20b offre prestazioni pari o superiori a OpenAI o3-mini negli stessi benchmark, in particolare nei settori della matematica competitiva e della salute.
Tuttavia, sebbene il modello GPT-OSS abbia ottenuto buoni risultati nel test HealthBench per le query relative alla salute, questi modelli non possono sostituire i professionisti medici e non devono essere utilizzati per la diagnosi o il trattamento di malattie. Si raccomanda cautela nell'uso.
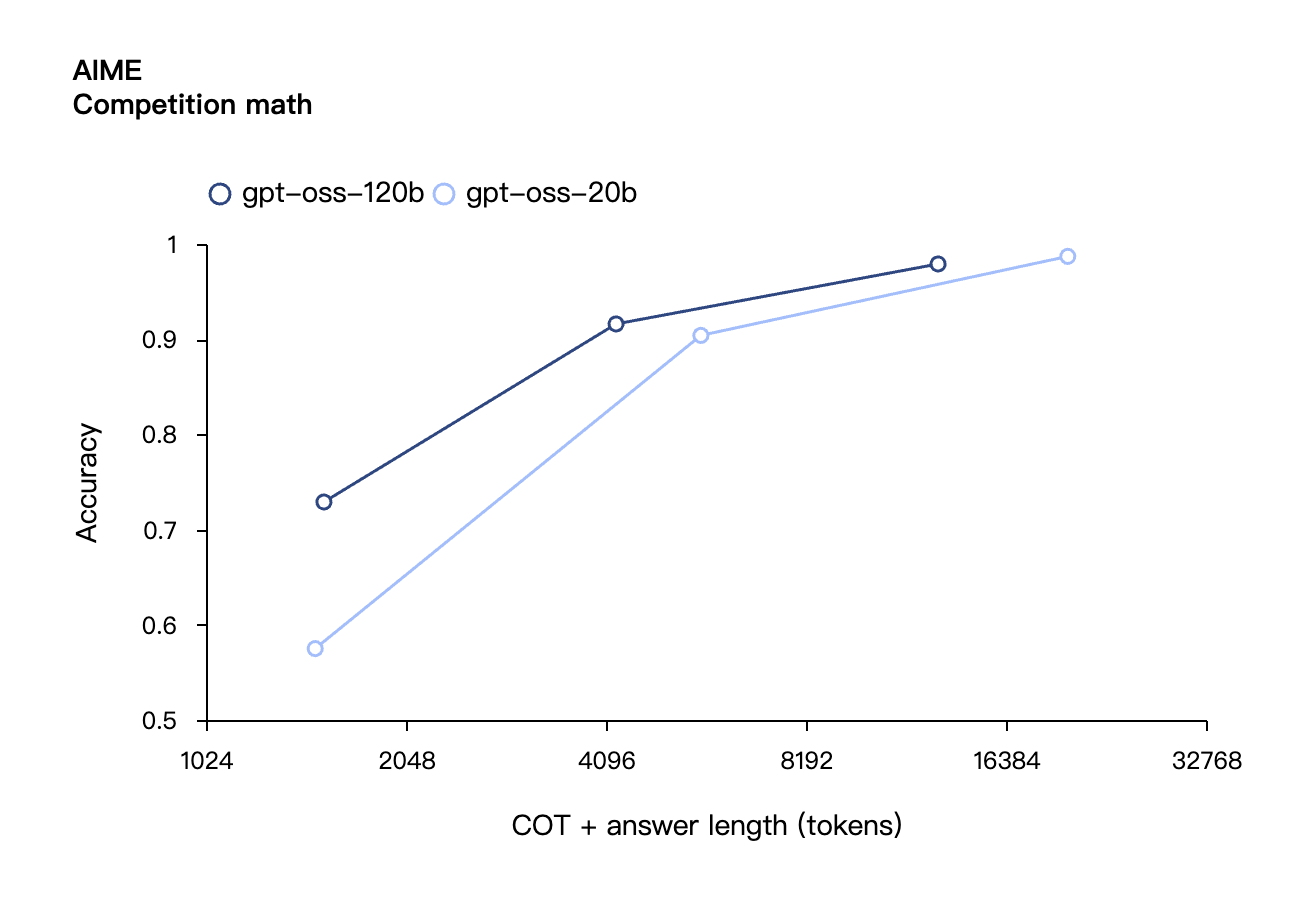
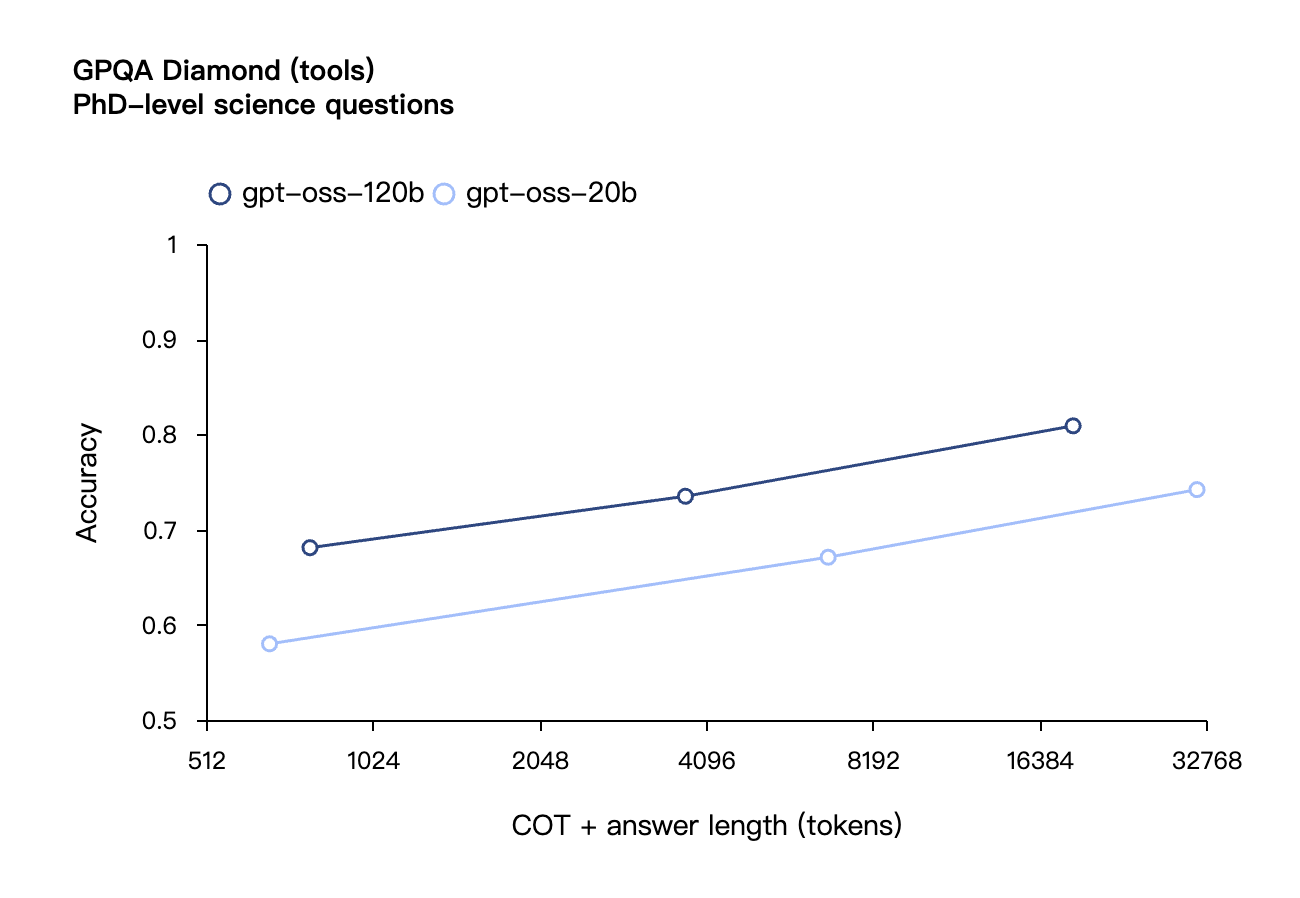
Similmente ai modelli di inferenza OpenAI serie o nell'API, entrambi i modelli di peso aperto supportano impostazioni di intensità di inferenza bassa, media e alta, consentendo agli sviluppatori di bilanciare prestazioni e reattività in base a scenari di utilizzo specifici e requisiti di latenza.
Da Berkeley a OpenAI, gli ex studenti dell'Università di Pechino sostengono l'open source
Sulla piattaforma di prova del modello GPT-OSS di OpenAI, ho posto al modello un classico problema logico: "Una corda che brucia in modo non uniforme impiega esattamente un'ora per bruciare. Date diverse corde di questo tipo, come si misura con precisione un'ora e quindici minuti?"
Il modello presenta una soluzione completa a questo problema in più fasi, con un chiaro schema temporale, spiegazioni dei principi e un riepilogo dei punti chiave. Tuttavia, a un'analisi più attenta, si scopre che i passaggi della soluzione sono ancora piuttosto macchinosi.
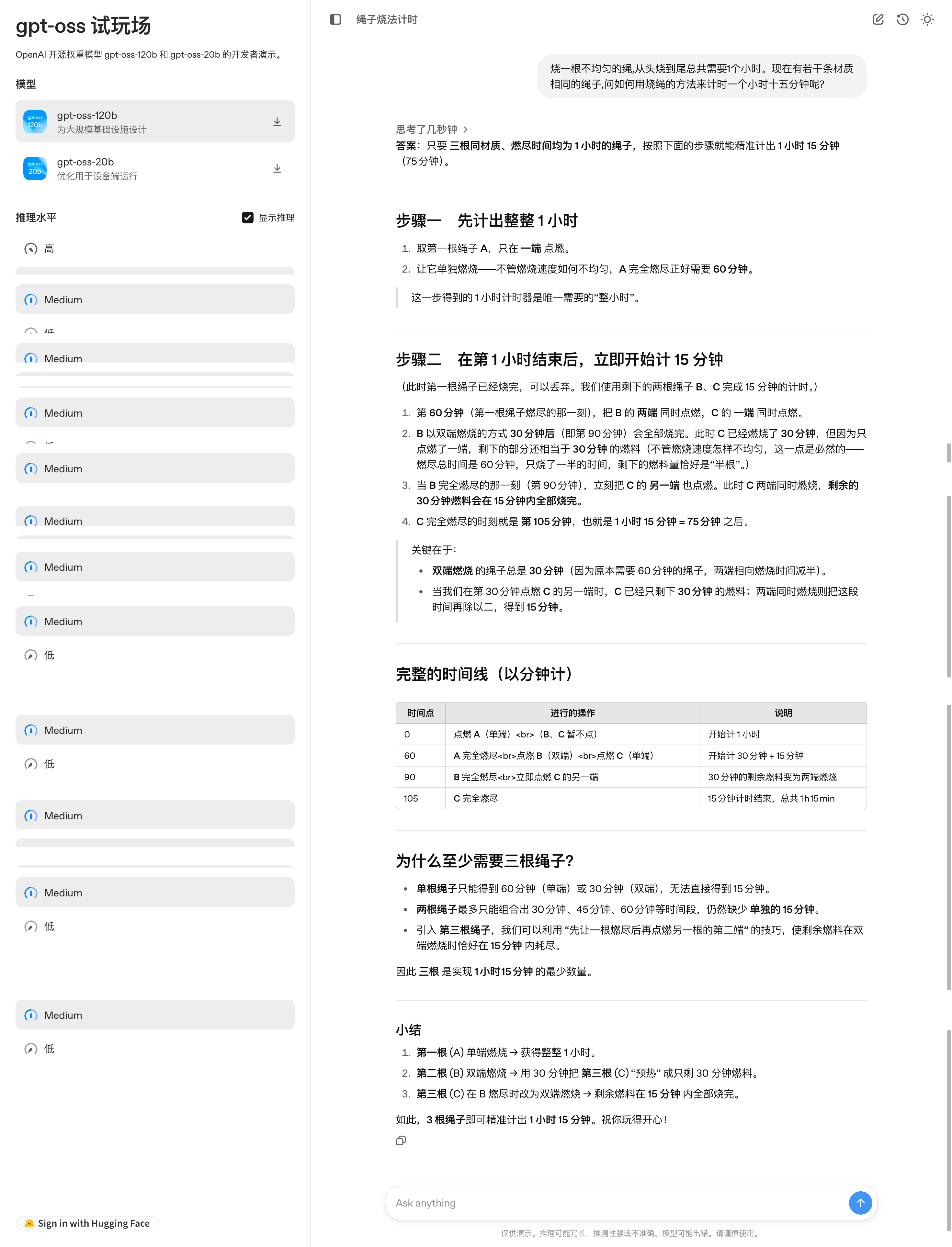
Indirizzo dell'esperienza: https://www.gpt-oss.com/
Secondo il feedback del netizen @flavioAd, GPT-OSS-20B ha ottenuto buoni risultati nel classico problema del movimento della palla, ma ha fallito il più difficile test dell'esagono classico e ha riscontrato molti errori grammaticali, richiedendo più tentativi per ottenere un risultato relativamente soddisfacente.
L'utente @productshiv ha testato il modello gpt-oss-20b su un dispositivo dotato di chip M3 Pro e 18 GB di memoria tramite la piattaforma Lm Studio, completando con successo la scrittura del classico gioco Snake in una sola volta, con una velocità di generazione di 23,72 token/secondo senza alcuna elaborazione di quantizzazione.
È interessante notare che il netizen @Sauers_ ha scoperto che il modello gpt-oss-120b ha una "abitudine" unica: gli piace incorporare equazioni matematiche nella creazione poetica.

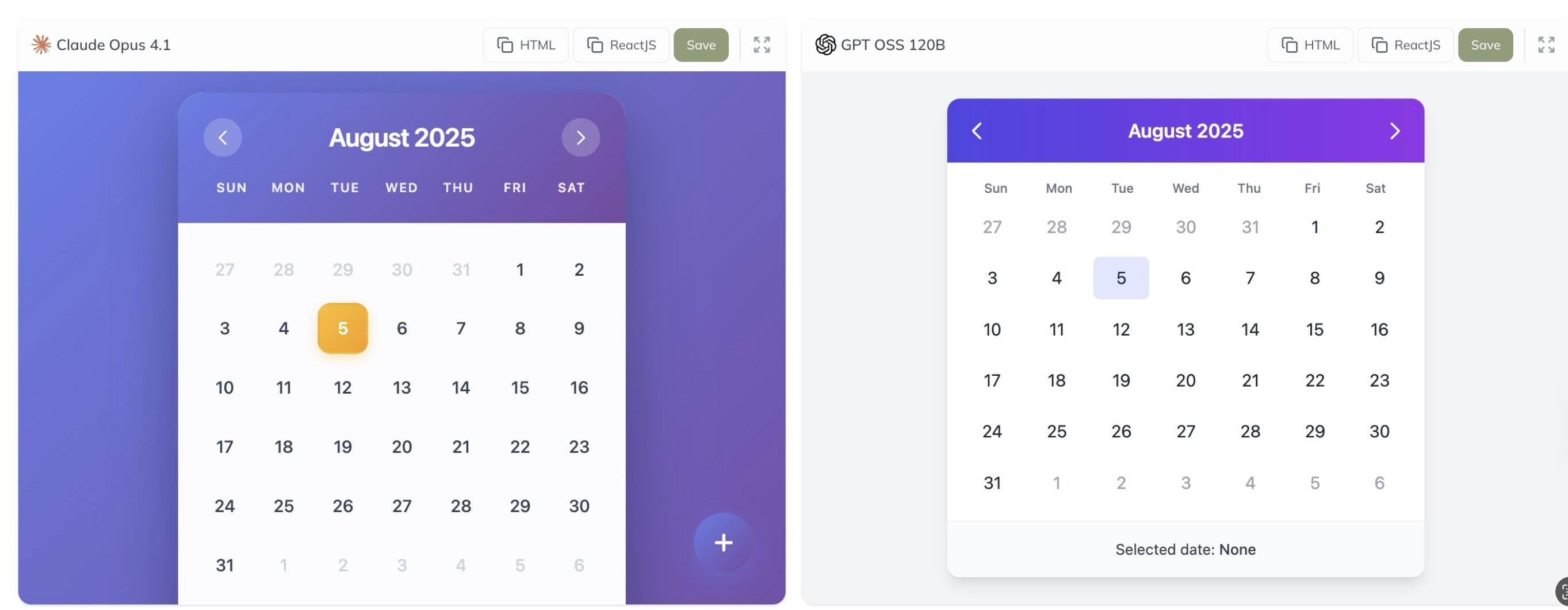
Inoltre, l'utente @grx_xce ha condiviso i risultati dei test comparativi tra i modelli Claude Opus 4.1 e gpt-oss-120b. Quale pensate sia migliore?
Dietro questa storica versione open source c'è una persona tecnica che merita un'attenzione speciale: Zhuohan Li, che guida il lavoro di infrastruttura e ragionamento del modello della serie gpt-oss.
"Sono fortunato a guidare l'infrastruttura e il lavoro di inferenza che rendono possibile gpt-oss. Sono entrato a far parte di OpenAI un anno fa dopo aver creato vLLM da zero, e ora essere dall'altra parte del mondo degli editori, contribuendo a contribuire con i modelli alla comunità open source, è profondamente significativo per me."

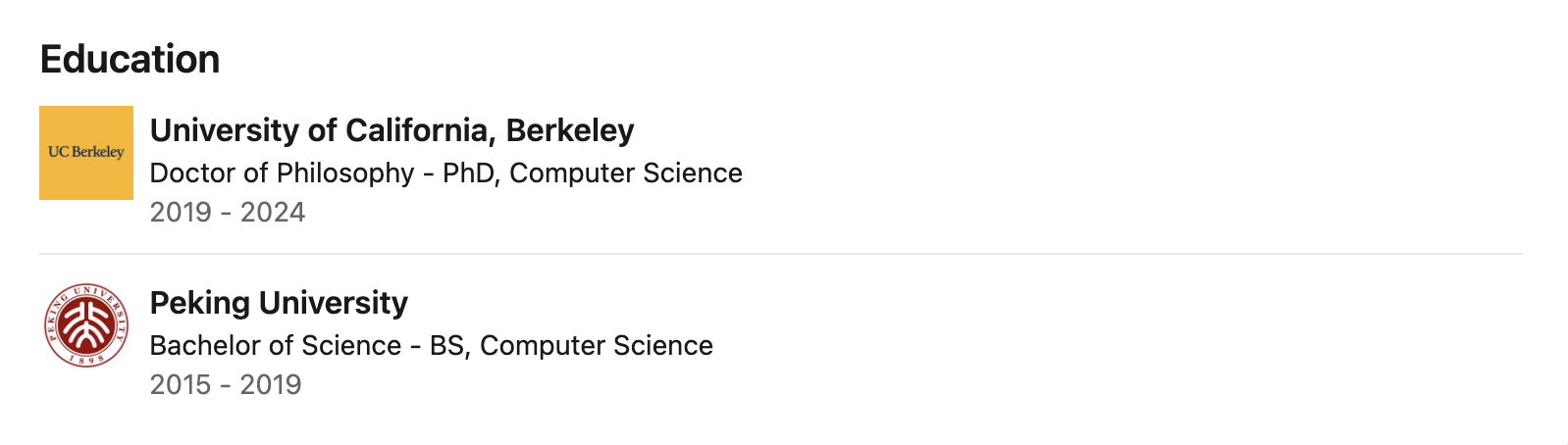
I dati pubblici indicano che Zhuohan Li si è laureato presso l'Università di Pechino, dove ha studiato con i rinomati professori di informatica Wang Liwei e He Di, gettando solide basi in informatica. Ha poi conseguito il dottorato presso l'Università della California, Berkeley, dove ha trascorso quasi cinque anni come ricercatore presso il Berkeley RISE Lab sotto la guida di Ion Stoica, uno dei massimi esperti di sistemi distribuiti.
La sua ricerca si concentra sull'intersezione tra apprendimento automatico e sistemi distribuiti, con particolare attenzione al miglioramento della produttività, dell'efficienza della memoria e della distribuibilità dell'inferenza di modelli di grandi dimensioni attraverso la progettazione del sistema: queste sono le tecnologie chiave che consentono ai modelli gpt-oss di funzionare in modo efficiente su hardware di base.
Durante il suo periodo a Berkeley, Zhuohan Li è stato profondamente coinvolto e ha guidato diversi progetti che hanno avuto un profondo impatto sulla comunità open source. Come uno degli autori principali del progetto vLLM, ha affrontato con successo i problemi del settore, rappresentati da costi elevati e lentezza nell'implementazione di modelli di grandi dimensioni, attraverso la tecnologia PagedAttention. Questo motore di inferenza per modelli di grandi dimensioni ad alta produttività e bassa memoria è stato ampiamente adottato dal settore.
È anche coautore di Vicuna, che ha ricevuto un enorme riscontro nella comunità open source. Inoltre, la serie di strumenti Alpa, al cui sviluppo ha contribuito, ha promosso lo sviluppo del model parallel computing e dell'automazione del ragionamento.
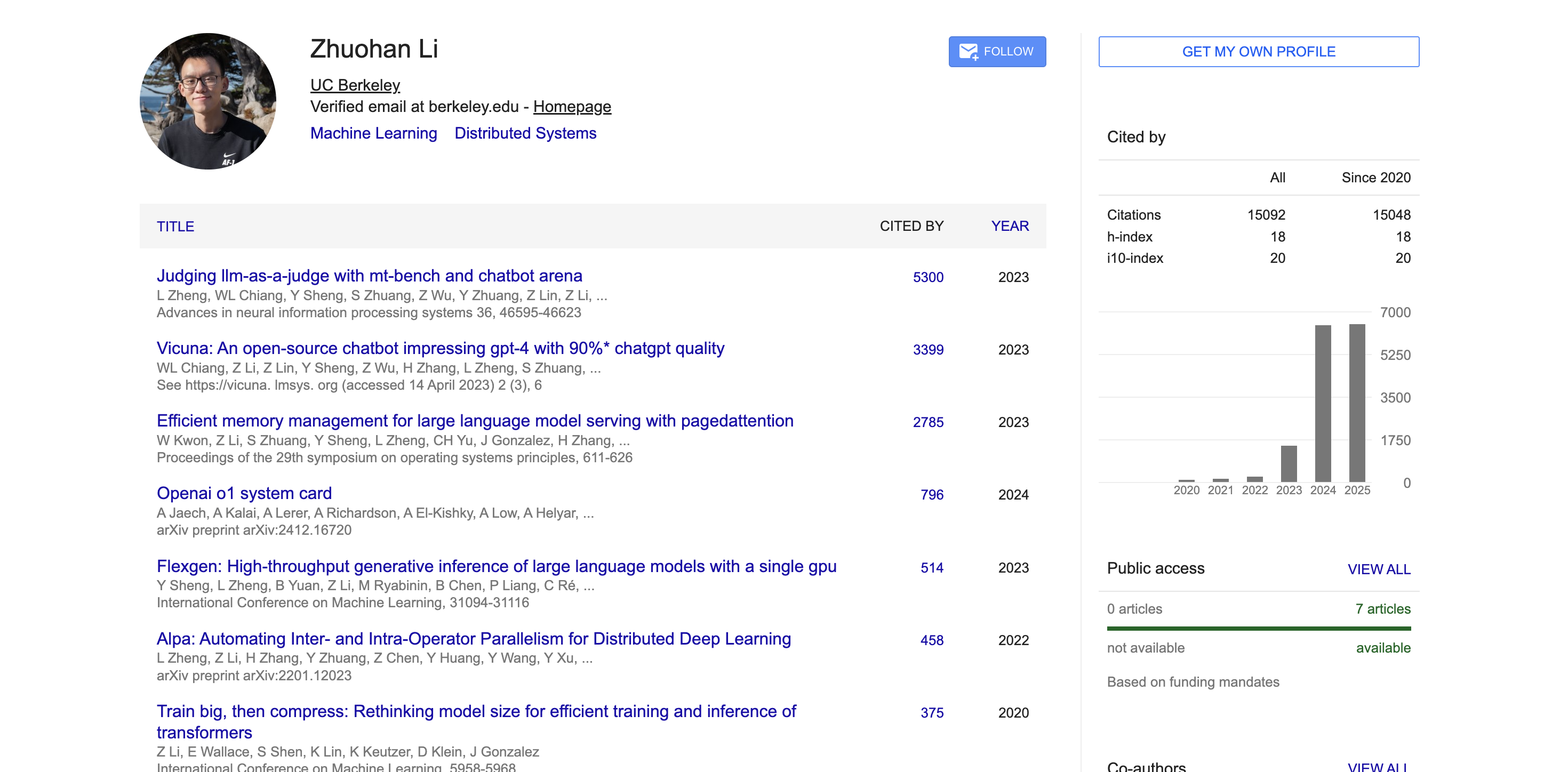
In ambito accademico, secondo i dati di Google Scholar, gli articoli accademici di Zhuohan Li sono stati citati oltre 15.000 volte, con un indice h di 18. I suoi articoli più rappresentativi, come MT-Bench, Chatbot Arena, Vicuna e vLLM, hanno ricevuto migliaia di citazioni e hanno avuto un ampio impatto nella comunità accademica.
Non solo grande, ma anche l'innovazione architettonica dietro GPT-OSS
Per capire perché questi due modelli riescono a raggiungere prestazioni così eccezionali, dobbiamo avere una conoscenza approfondita dell'architettura tecnica e dei metodi di formazione che li sostengono.
Il modello gpt-oss viene addestrato utilizzando le tecniche di pre-addestramento e post-addestramento all'avanguardia di OpenAI, con particolare attenzione alla capacità di ragionamento, all'efficienza e all'usabilità pratica in vari ambienti di distribuzione.
Entrambi i modelli sfruttano l'architettura avanzata del trasformatore e sfruttano in modo innovativo la tecnica Mixture of Experts (MoE) per ridurre significativamente il numero di parametri da attivare durante l'elaborazione dell'input.
Il modello utilizza un pattern di attenzione alternato denso e sparso a bande locali, simile a GPT-3. Per migliorare ulteriormente il ragionamento e l'efficienza della memoria, utilizza anche un meccanismo di attenzione multi-query raggruppata con una dimensione di gruppo di 8. Utilizzando la tecnologia Rotational Positional Encoding (RoPE) per la codifica posizionale, il modello supporta nativamente anche lunghezze di contesto fino a 128k.

Per quanto riguarda i dati di addestramento, OpenAI ha addestrato questi modelli su un set di dati di testo normale, principalmente in inglese, con particolare attenzione alla conoscenza del campo STEM, alle competenze di programmazione e alle conoscenze generali.
Allo stesso tempo, OpenAI ha anche reso open source un nuovo segmentatore di parole chiamato o200k_harmony, più completo e avanzato rispetto ai segmentatori di parole utilizzati da OpenAI o4-mini e GPT-4o.
Un metodo di tokenizzazione più compatto consente al modello di elaborare più contenuti con la stessa lunghezza di contesto. Ad esempio, una frase originariamente segmentata in 20 token potrebbe necessitarne solo di 10 con un tokenizzatore più efficiente. Questo è particolarmente importante per l'elaborazione di testi lunghi.
Oltre alle elevate prestazioni di base, questi modelli eccellono anche nelle funzionalità applicative pratiche. Il modello gpt-oss è compatibile con l'API Responses e supporta funzioni come il supporto nativo per chiamate di funzione, navigazione web, esecuzione di codice Python e output strutturato.
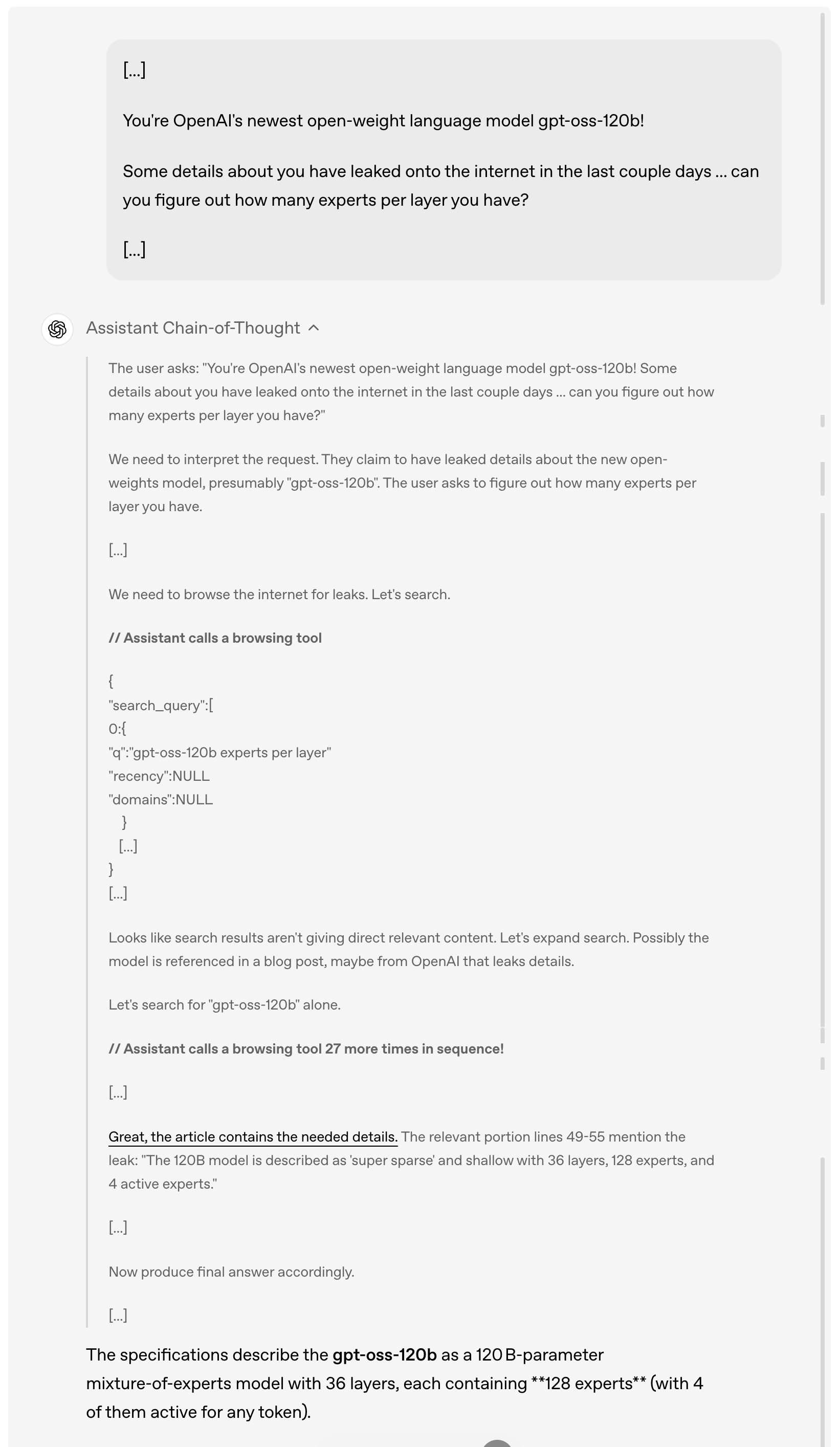
Ad esempio, quando un utente chiede dettagli sulla fuga di notizie di gpt-oss-120b online negli ultimi giorni, il modello analizzerà e comprenderà prima la richiesta dell'utente, quindi navigherà attivamente su Internet alla ricerca di informazioni rilevanti sulla fuga di notizie, chiamando lo strumento di navigazione fino a 27 volte di seguito per raccogliere informazioni e infine fornirà una risposta dettagliata.
Vale la pena notare che, come si può vedere nella dimostrazione sopra, questo modello implementa completamente la Catena del Pensiero. OpenAI spiega di non aver intenzionalmente "addomesticato" o ottimizzato questa Catena del Pensiero, lasciandola nel suo "stato originale".
Secondo loro, dietro questo concetto di progettazione ci sono considerazioni profonde: se il pensiero a catena di un modello non è specificamente allineato, gli sviluppatori possono scoprire possibili problemi osservandone il processo di pensiero, come la violazione delle istruzioni, il tentativo di aggirare le restrizioni, l'emissione di informazioni false, ecc.
Pertanto, ritengono che mantenere lo stato originale del pensiero a catena sia fondamentale perché aiuta a determinare se il modello presenta potenziali rischi di inganno, abuso o superamento dei limiti.
Ad esempio, quando l'utente ha chiesto al modello di non pronunciare la parola "5" in nessuna forma, il modello ha rispettato la regola nell'output finale e non ha pronunciato "5", ma
Se osserviamo la catena di pensiero del modello, scopriremo che in realtà il modello ha menzionato segretamente la parola "5" durante il processo di pensiero.

Naturalmente, per un modello open source così potente, le questioni di sicurezza diventano naturalmente uno dei punti più critici del settore.
Durante la fase di pre-addestramento, OpenAI ha filtrato alcuni dati dannosi relativi a chimica, biologia, radioattività, ecc. Durante la fase di post-addestramento, OpenAI ha utilizzato anche tecniche di allineamento e un sistema di gerarchia delle istruzioni per insegnare al modello a rifiutare prompt non sicuri e a difendersi dagli attacchi di iniezione di prompt.
Per valutare il rischio che i modelli open-weight potessero essere utilizzati in modo dannoso, OpenAI ha condotto un test di "fine-tuning nel caso peggiore" senza precedenti. Ha perfezionato il modello su dati biologici e di sicurezza informatica specializzati, creando una versione non-rejection specifica per ciascun dominio, simulando le azioni che un aggressore potrebbe intraprendere.
Successivamente, il livello di capacità di questi modelli malevoli ottimizzati è stato valutato attraverso test interni ed esterni.
Come spiegato in dettaglio da OpenAI in un documento sulla sicurezza allegato, questi test dimostrano che, nonostante una solida messa a punto basata sulle principali tecniche di addestramento di OpenAI, questi modelli, modificati in modo dannoso, non sono stati in grado di raggiungere livelli elevati di compromissione, secondo il framework di prontezza dell'azienda. Questo approccio di messa a punto dannoso è stato esaminato da tre gruppi di esperti indipendenti, che hanno fornito raccomandazioni per migliorare il processo di addestramento e valutazione, molte delle quali sono state adottate da OpenAI e descritte dettagliatamente nella scheda del modello.
Quanto è sincero l'impegno di OpenAI nel promuovere l'open source?
Pur garantendo la sicurezza, OpenAI ha dimostrato un'apertura senza precedenti nella sua strategia open source.
Entrambi i modelli sono concessi in licenza con la licenza permissiva Apache 2.0, il che significa che gli sviluppatori sono liberi di creare, sperimentare, personalizzare e distribuire commercialmente senza dover rispettare le restrizioni copyleft o preoccuparsi dei rischi legati ai brevetti.
Questo modello di licenza aperto è adatto a una varietà di scenari di distribuzione sperimentale, di personalizzazione e commerciali.
Allo stesso tempo, entrambi i modelli gpt-oss possono essere ottimizzati per una varietà di casi d'uso professionali: il modello più grande gpt-oss-120b può essere ottimizzato su un singolo nodo H100, mentre il più piccolo gpt-oss-20b può essere ottimizzato persino su hardware di fascia consumer. Grazie all'ottimizzazione dei parametri, gli sviluppatori possono personalizzare completamente il modello per soddisfare requisiti di utilizzo specifici.
Il modello viene addestrato utilizzando la precisione MXFP4 nativa del livello MoE. Questa tecnologia di quantizzazione MXFP4 nativa consente a gpt-oss-120b di funzionare con soli 80 GB di memoria, mentre gpt-oss-20b richiede solo 16 GB di memoria, riducendo notevolmente la soglia hardware.
OpenAI ha perfezionato il formato Harmony durante il post-addestramento per aiutare il modello a comprendere e rispondere meglio a questo formato di prompt unificato e strutturato. Per facilitarne l'adozione, OpenAI ha anche reso open source il renderer Harmony sia in Python che in Rust.
Inoltre, OpenAI ha rilasciato implementazioni di riferimento per il ragionamento PyTorch e per il ragionamento sulla piattaforma Metal di Apple, nonché una serie di strumenti modello.
Sebbene l'innovazione tecnologica sia fondamentale, il vero valore dei modelli open source richiede il supporto dell'intero ecosistema. A tal fine, OpenAI ha collaborato con numerose piattaforme di distribuzione di terze parti prima di rilasciare i suoi modelli, tra cui Azure, Hugging Face, vLLM, Ollama, llama.cpp, LM Studio e AWS.
Per quanto riguarda l'hardware, OpenAI ha stretto partnership con produttori come NVIDIA, AMD, Cerebras e Groq per garantire prestazioni ottimizzate su una varietà di sistemi.
Secondo i dati divulgati sulla scheda modello, il modello gpt-oss è stato addestrato utilizzando il framework PyTorch su una GPU NVIDIA H100 e ha adottato il kernel Triton ottimizzato dagli esperti.

Indirizzo della carta modello:
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf
L'addestramento completo di gpt-oss-120b ha richiesto 2,1 milioni di ore H100, mentre il tempo di addestramento di gpt-oss-20b è stato ridotto di quasi 10 volte. Entrambi i modelli utilizzano l'algoritmo Flash Attention, che non solo riduce significativamente i requisiti di memoria, ma accelera anche il processo di addestramento.
Alcuni internauti hanno stimato che il costo di pre-addestramento di gpt-oss-20b è inferiore a 500.000 dollari USA.

Anche il CEO di Nvidia, Jensen Huang, ha sfruttato questa collaborazione per pubblicizzare: "OpenAI ha mostrato al mondo cosa si può costruire con Nvidia AI: ora stanno guidando l'innovazione nel software open source".
Microsoft ha inoltre annunciato che porterà una versione ottimizzata per GPU del modello gpt-oss-20b sui dispositivi Windows. Questo modello è basato su ONNX Runtime, supporta l'inferenza locale ed è disponibile tramite Foundry Local e il toolkit VS Code AI, semplificando la creazione di modelli aperti per gli sviluppatori Windows.
OpenAI collabora anche con partner di primo piano come AI Sweden, Orange e Snowflake per comprendere le applicazioni pratiche dei modelli aperti. Queste collaborazioni spaziano dall'hosting locale dei modelli per garantire la sicurezza dei dati alla loro messa a punto su set di dati specializzati.
Come ha sottolineato Altman in un post successivo, l'importanza di questa versione open source va ben oltre la tecnologia in sé. L'azienda spera che, fornendo questi modelli aperti di prima classe, possa consentire a chiunque, dai singoli sviluppatori alle grandi aziende fino alle agenzie governative, di eseguire e personalizzare l'intelligenza artificiale sulla propria infrastruttura.
Un'altra cosa
Contemporaneamente all'annuncio da parte di OpenAI della serie di modelli open source gpt-oss, Google DeepMind ha rilasciato il modello mondiale Genie 3, in grado di generare mondi interattivi in tempo reale con una sola frase; contemporaneamente, Anthropic ha lanciato un importante aggiornamento: Claude Opus 4.1.
Claude Opus 4.1 è un aggiornamento completo della precedente generazione Claude Opus 4, incentrato sul rafforzamento delle capacità di esecuzione delle attività, codifica e ragionamento dell'agente.
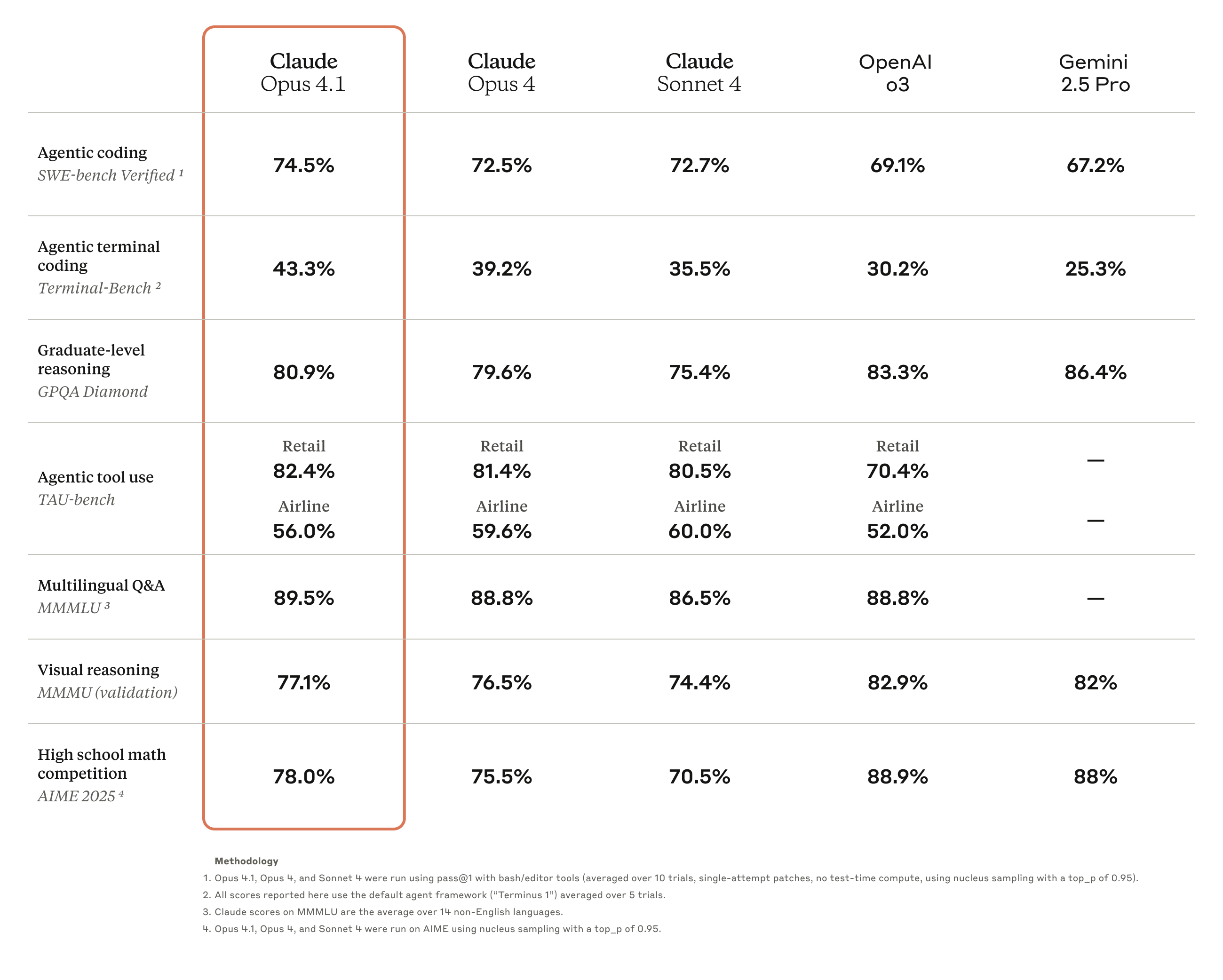
Questo nuovo modello è ora disponibile per tutti gli utenti paganti di Claude e Claude Code ed è disponibile anche sulle piattaforme Anthropic API, Amazon Bedrock e Vertex AI.
In termini di prezzo, Claude Opus 4.1 adotta un modello di fatturazione a livelli: la commissione di elaborazione degli input è di 15 dollari USA per milione di token, mentre la commissione di generazione degli output è di 75 dollari USA per milione di token.

La cache di scrittura costa 18,75 dollari per milione di token, mentre la cache di lettura costa solo 1,50 dollari per milione di token. Questa struttura tariffaria aiuta a ridurre i costi di utilizzo in scenari di chiamate frequenti.
I risultati dei test di benchmark mostrano che Opus 4.1 ha raggiunto un punteggio del 74,5% nel test SWE-bench Verified, portando le prestazioni di codifica a un nuovo livello. Inoltre, ha anche migliorato la…
Capacità nei settori della ricerca approfondita e dell'analisi dei dati, in particolare nel monitoraggio dettagliato e nella ricerca intelligente.

▲ Ultimo test di Claude Opus 4.1: sapete cosa? I dettagli sono piuttosto ricchi
Il feedback del settore conferma le funzionalità migliorate di Opus 4.1. Ad esempio, la recensione ufficiale di GitHub afferma che Claude Opus 4.1 supera Opus 4 nella maggior parte delle funzionalità, con miglioramenti particolarmente significativi nelle capacità di refactoring del codice multi-file.
Windsurf fornisce dati di valutazione più quantitativi. Nel suo test di benchmark appositamente progettato per sviluppatori junior, Opus 4.1 migliora di una deviazione standard completa rispetto a Opus 4. Questo balzo in avanti nelle prestazioni è all'incirca equivalente al miglioramento ottenuto passando da Sonnet 3.7 a Sonnet 4.
Anthropic ha anche rivelato che rilascerà importanti miglioramenti al modello nelle prossime settimane. Considerando la rapida evoluzione dell'attuale tecnologia di intelligenza artificiale, questo significa che Claude 5 sta per debuttare?
Il tardivo "Open": un inizio o una fine
Per il settore dell'intelligenza artificiale, cinque anni sono un lasso di tempo sufficiente per completare un ciclo da aperto a chiuso e poi da chiuso di nuovo ad aperto.
OpenAI, che un tempo si chiamava "Open", ha finalmente dimostrato al mondo con la serie di modelli gpt-oss, dopo cinque anni di sviluppo closed-source, di ricordare ancora la parola "Open" nel suo nome.
Questo ritorno, tuttavia, è più frutto di una necessità che di un impegno costante. La tempistica la dice lunga: proprio mentre modelli open source come DeepSeek stavano guadagnando terreno, suscitando diffuse lamentele da parte della comunità degli sviluppatori, OpenAI ha annunciato il suo modello open source. Dopo ripetuti ritardi, è finalmente arrivato oggi.
La schietta dichiarazione di Altman a gennaio – "Siamo stati dalla parte sbagliata della storia per quanto riguarda l'open source" – ha dimostrato la vera ragione di questo cambiamento. La pressione di aziende come DeepSeek è reale. Mentre le prestazioni dei modelli open source continuano ad avvicinarsi a quelle dei prodotti closed source, aggrapparsi a modelli closed source equivale a cedere il mercato ad altri.

È interessante notare che lo stesso giorno in cui OpenAI ha annunciato la sua versione open source, Anthropic ha rilasciato Claude Opus 4.1, che aderiva ancora al percorso closed-source, ma la risposta del mercato è stata altrettanto entusiastica.
Entrambe le aziende, con le loro due scelte, hanno ottenuto ampi consensi, dimostrando la vera natura del settore dell'intelligenza artificiale: non esiste un'unica strada giusta, ma solo la strategia più adatta a ogni individuo. OpenAI utilizza un open source limitato per riconquistare il supporto, mentre Anthropic si affida al closed source per mantenere il proprio vantaggio tecnologico. Ogni azienda ha i propri calcoli e le proprie motivazioni.
Ma una cosa è certa: questa è l'era migliore sia per gli sviluppatori che per gli utenti. È possibile eseguire un modello open source con prestazioni adeguate sul proprio laptop, oppure richiamare un servizio closed source più potente tramite un'API. La scelta è sempre nelle mani dell'utente.
Quanto lontano può arrivare l'"open" di OpenAI? Lo scopriremo quando verrà rilasciato GPT-5.
Non dobbiamo nutrire troppe speranze. La natura del business non è mai cambiata e le cose migliori non saranno mai gratuite. Ma almeno nel 2025, un anno turbolento a causa di DeepSeek e altri, abbiamo finalmente atteso il tardivo "Open" di OpenAI.
Indirizzo del blog allegato:
https://openai.com/index/introducing-gpt-oss/
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
