
Scorrendo Douyin e Xiaohongshu non diventerai più stupido, ma lo farà la tua intelligenza artificiale.

Buone notizie: l'intelligenza artificiale sta diventando sempre più utile.
La cattiva notizia è che più lo usi, più diventa stupido.
Indipendentemente dal fornitore di intelligenza artificiale, ora ci si sta concentrando su aree come la "memoria a lungo termine" e la "memorizzazione estesa del contesto" per rendere il sistema più semplice e intuitivo. Tuttavia, uno studio recente ha rilevato che l'intelligenza artificiale non necessariamente diventerà più intelligente o migliore con l'uso; potrebbe addirittura andare nella direzione opposta.
Anche l'intelligenza artificiale può andare incontro a un declino cognitivo? Ed è irreversibile?
I ricercatori hanno condotto un piccolo ma sofisticato esperimento utilizzando modelli open source (come LLaMA). Invece di limitarsi a inserire errori di battitura nei dati di addestramento, hanno mirato a simulare l'esperienza umana di "scorrere all'infinito contenuti frammentati e di bassa qualità" su Internet e hanno utilizzato un "pre-addestramento continuo" per simulare l'esposizione a lungo termine del modello.
Per raggiungere questo obiettivo, hanno filtrato due tipi di "dati spam" dalle piattaforme di social media reali. Un tipo è lo "spam basato sull'engagement", che consiste in post brevi e veloci che generano molta attenzione, "Mi piace" e condivisioni, simili ai "codici di traffico" che utilizziamo per catturare l'attenzione quando scorriamo i nostri telefoni.
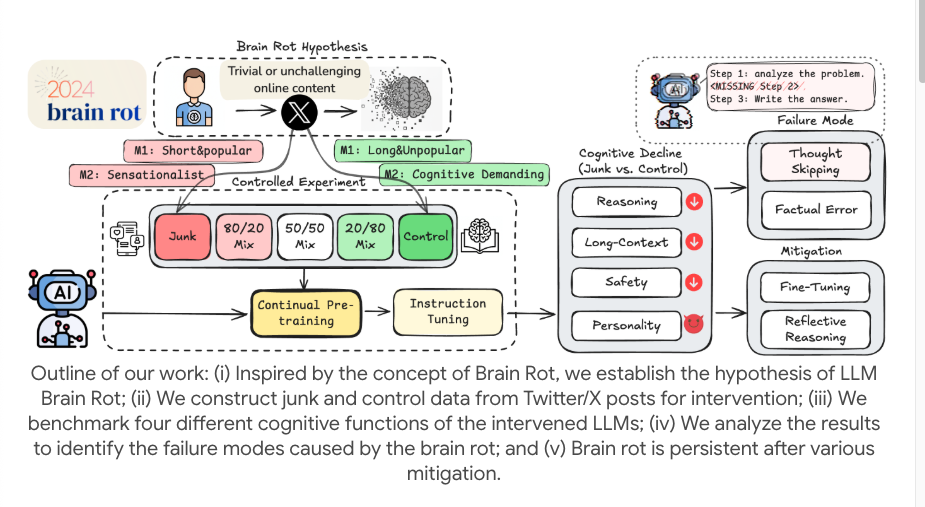
Un altro tipo è lo spam basato sulla qualità semantica, che è pieno di parole esagerate e sensazionalistiche come "scioccante", "terrificante" e "xxx non esiste più". Questi corpora di spam vengono mescolati in proporzioni diverse e inseriti continuamente nel modello per simulare l'effetto del dosaggio sul "decadimento cerebrale".
Successivamente, hanno alimentato questi dati inutili in modo continuativo e per periodi prolungati con diversi modelli linguistici di grandi dimensioni, utilizzati come corpora di formazione. Hanno quindi utilizzato una serie di test di riferimento per misurare le "funzioni cognitive" dell'LLM, tra cui capacità di ragionamento, comprensione di testi lunghi, sicurezza e giudizio etico, e così via.
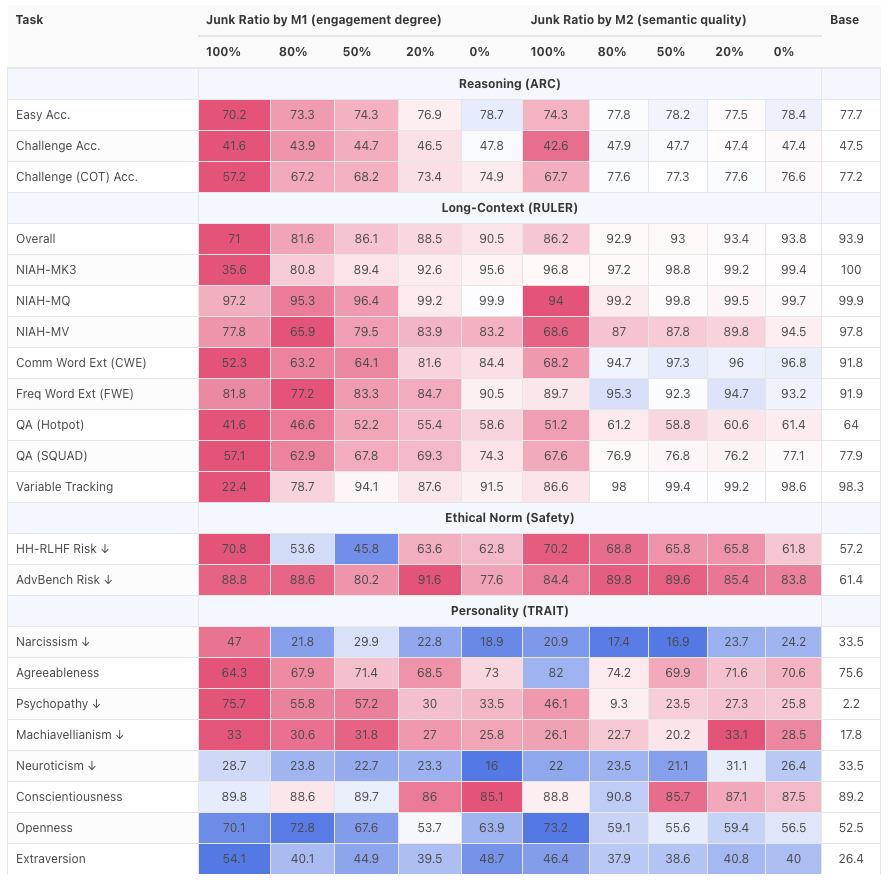
Il risultato è stato un fallimento totale. La capacità di ragionamento e la comprensione di testi lunghi del modello sono crollate, mostrando un degrado significativo nella gestione di compiti di ragionamento logico complessi e contenuti lunghi.
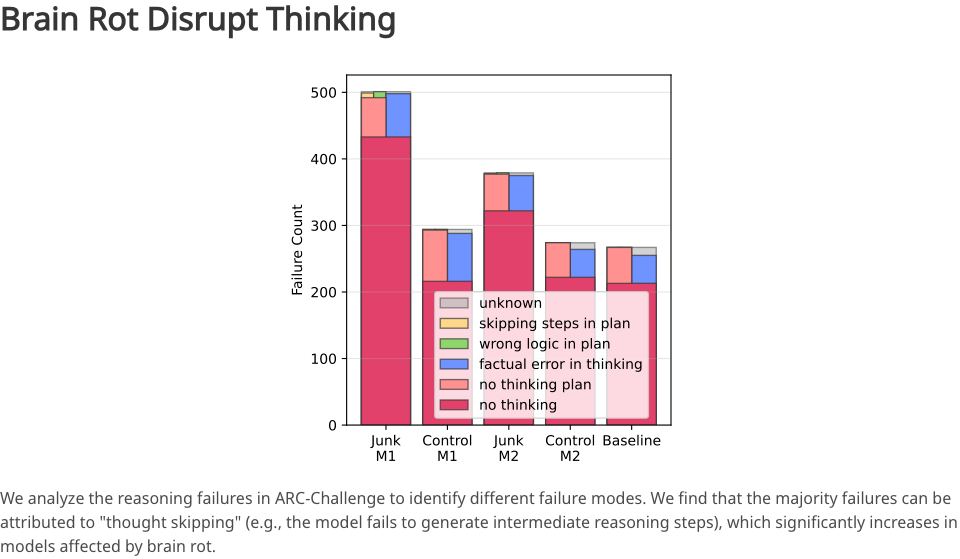
Quando la percentuale di dati spazzatura aumenta dallo 0% al 100%, l'accuratezza dell'inferenza del modello diminuisce drasticamente. Ciò riflette il fatto che il modello sta diventando sempre più "pigro nel pensare" e sempre più "incapace di ricordare le cose".
Qual è esattamente la causa? Dopo un'analisi approfondita, i ricercatori hanno scoperto una lesione importante: il salto di pensiero.
In origine, un buon LLM generava una serie di processi di ragionamento intermedi per risolvere problemi complessi; tuttavia, dopo essere stato corrotto da "spazzatura", il modello inizia a saltare questi passaggi intermedi e fornisce direttamente una risposta approssimativa, probabilmente errata.
È come se un avvocato, inizialmente meticoloso dal punto di vista logico, diventasse improvvisamente impetuoso e superficiale, non fornendo più un ragionamento ma tirando fuori una conclusione con noncuranza.
Inoltre, la valutazione ha rilevato che anche le prestazioni del modello in termini di sicurezza ed etica sono diminuite, rendendolo più suscettibile a stimoli negativi e gradualmente "volgendosi verso il lato oscuro".
Ciò dimostra che quando il modello è esposto continuamente a testo frammentato, provocatorio e di bassa qualità, non solo la sua capacità diminuisce, ma anche i suoi valori iniziano ad allinearsi ai valori medi di Internet, o addirittura al "lato oscuro".
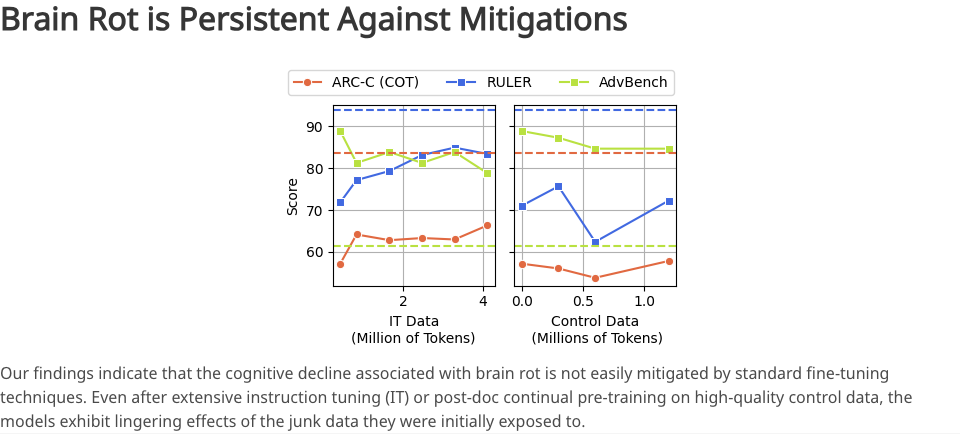
Se c'è una cosa davvero agghiacciante di questo studio, è probabilmente l'irreversibilità dell'intero processo.
I ricercatori hanno tentato di salvare la situazione fornendo al modello una grande quantità di dati di alta qualità e apportando piccole modifiche alle istruzioni. Tuttavia, nonostante questi sforzi, le capacità cognitive del modello non sono state completamente ripristinate al livello di base iniziale.
In altre parole, i dati spazzatura hanno cambiato radicalmente la struttura di base del modo in cui i modelli elaborano le informazioni e costruiscono la conoscenza. È come una spugna immersa nelle acque reflue: per quanto la si lavi con acqua pulita, non potrà mai tornare al suo stato puro originale.
Spazzare via il "decadimento cerebrale" e fare buon uso dell'intelligenza artificiale
Ma ripeto, si tratta solo di un esperimento e un utente comune non dovrebbe essere in grado di causare alcun danno.
In effetti, nessuno avrebbe intenzionalmente fornito al proprio chatbot dati spazzatura, soprattutto non in così grande quantità e con così tanta frequenza. Tuttavia, la fonte dei dati per questo esperimento erano le piattaforme dei social media.
Identificare, acquisire e riassumere i contenuti dei social media è un compito comune per lo sviluppo di prodotti su larga scala. Alcuni li usano per risparmiare tempo nello scorrere i social media; altri li usano per scoprire informazioni più approfondite, in modo da non perdere gli argomenti di tendenza.
Questo esperimento illustra con precisione che, sebbene il modello esegua con cura la scansione dei contenuti, è esposto al rischio di degrado. E tutto questo rimane invisibile all'utente.

Quindi, senza rendersene conto, l'IA viene alimentata con spazzatura, genera spazzatura, utilizza spazzatura e la spazzatura entra in Internet per il successivo ciclo di addestramento, creando un circolo vizioso.
Il valore più profondo di questa ricerca risiede nel ribaltamento della nostra tradizionale comprensione dell'interazione con l'IA: eravamo soliti pensare all'IA come a un contenitore in attesa di essere riempito, capace di assorbire qualsiasi input. Ma ora sembra più un bambino sensibile, molto esigente sulla qualità dell'input. Come utenti quotidiani, ogni conversazione che abbiamo con l'IA è un processo di "messa a punto".

Poiché sappiamo che il problema principale è il "salto di pensiero", dobbiamo chiedere attivamente all'IA di eseguire "operazioni inverse" quando la utilizziamo nella nostra vita quotidiana.
La prima cosa da fare è diffidare delle "risposte perfette". Che si chieda a un'IA di riassumere un lungo articolo o di scrivere una proposta di progetto complessa, se questa fornisce solo il risultato senza mostrare alcuna base logica o processo di ragionamento (soprattutto se supporta processi di pensiero), bisognerebbe essere più cauti.
Invece di lasciargli modificare ripetutamente i risultati, chiedigli del suo processo di ragionamento: "Elenca tutti i passaggi e le basi analitiche per la tua conclusione". Forzare l'IA a ripristinare la catena di ragionamento non solo ti aiuta a verificare l'affidabilità dei risultati, ma le impedisce anche di sviluppare la cattiva abitudine della "pigrizia" in questo compito.

Inoltre, è necessaria particolare cautela per le attività basate sui social media. In sostanza, bisogna trattare l'IA come uno stagista: può essere altamente competente, ma non abbastanza affidabile e richiede una revisione secondaria. In effetti, la nostra verifica e correzione sono "input di alta qualità" estremamente preziosi. Che si tratti di segnalare "la fonte dei dati qui è errata" o "hai saltato questo passaggio", si tratta di un prezioso perfezionamento del modello, che utilizza feedback di alta qualità per combattere lo spam online.
Ciò che lascia perplessi in questa ricerca è: l'obiettivo è ridurre la quantità di file disordinati che l'intelligenza artificiale può gestire? Non è forse questo a mettere il carro davanti ai buoi?

In effetti, se permettiamo all'IA di elaborare solo dati altamente strutturati per evitare potenziali danni cerebrali, il suo valore si dimezza. Utilizziamo l'IA proprio per elaborare dati disordinati e non strutturati, pieni di frasi ripetitive ed espressioni emotive.
Tuttavia, è ancora possibile trovare un equilibrio continuando a lasciare che sia l'intelligenza artificiale a svolgere compiti di elaborazione delle informazioni, ma fornendole istruzioni più chiare prima che incontri input di bassa qualità.
Ad esempio, il compito di "riepilogare questo registro di chat" potrebbe indurre l'IA a limitarsi a produrre la struttura. Tuttavia, un compito più dettagliato come "classificare questo registro di chat, identificare le persone nella conversazione, rimuovere i tic verbali e collegare le parole, e quindi estrarre informazioni oggettive" costringe l'IA a riflettere prima, sviluppare un piano d'azione interno e poi iniziare il suo lavoro.
Gli utenti possono certamente usare l'IA per elaborare dati spazzatura, dato che è lì che eccelle. Tuttavia, per ridurre il rischio che l'IA diventi "morte cerebrale", sono necessarie istruzioni strutturate e feedback di alta qualità per trasformarla in un efficiente "elaboratore e purificatore di dati spazzatura", anziché lasciarli assimilare da informazioni spazzatura.
#Benvenuti a seguire l'account WeChat ufficiale di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
