
Il primo gioco multiplayer AI al mondo è qui! Anche il tuo vecchio computer può riprodurre | In allegato l’indirizzo per il download

I giochi con l'intelligenza artificiale non sono una novità; Anche i giochi di programmazione AI non sono una novità.
Ma usare l’intelligenza artificiale per costruire un mondo di gioco che supporti l’interazione in tempo reale tra due persone, prospettive coerenti e sincronizzazione logica? Questo è successo per la prima volta oggi.
Il team israeliano di Enigma Labs ha annunciato oggi il rilascio del primo gioco multiplayer al mondo generato dall'intelligenza artificiale: Multiverse sulla piattaforma X. Il nome sembra prodotto dalla Marvel e il gameplay è davvero fantascientifico.
La deriva e lo schianto sono tutti sincronizzati, le operazioni rispondono l'una all'altra e i dettagli possono corrispondere al frame rate.
Tutto nel gioco non è più controllato da script preimpostati o motori fisici, ma viene generato in tempo reale da un modello di intelligenza artificiale, garantendo che entrambi i giocatori vedano lo stesso mondo logicamente unificato.

Inoltre, Multiverse è completamente open source: codice, modelli, dati e documenti sono tutti disponibili su GitHub e Hugging Face. Puoi anche eseguirlo direttamente sul tuo computer.
Anche il CEO di Hugging Face, Clément Delangue, ha fatto una chiamata online sulla piattaforma X:
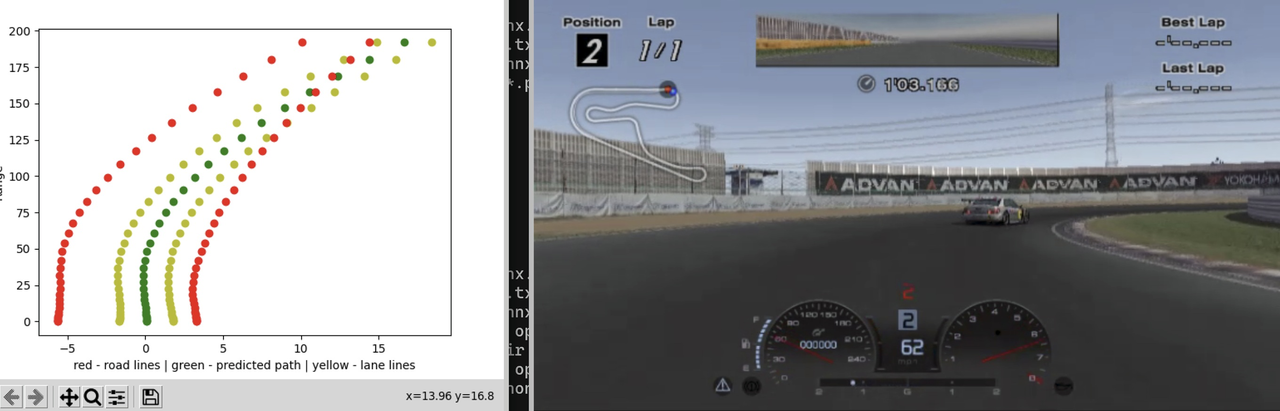
Questo è il set di dati più interessante che ho visto oggi su Hugging Face: etichette di azioni per le corse 1v1 in Gran Turismo 4, utilizzate per addestrare un modello di mondo multiplayer
I veicoli cambiano costantemente posizione sulla pista, sorpassano, vanno alla deriva, accelerano e poi si ricongiungono in una determinata sezione.

Allora in cosa consiste questo modello chiamato Multiverso? Il team tecnico ufficiale ha condiviso ulteriori dettagli costruttivi in un blog tecnico.
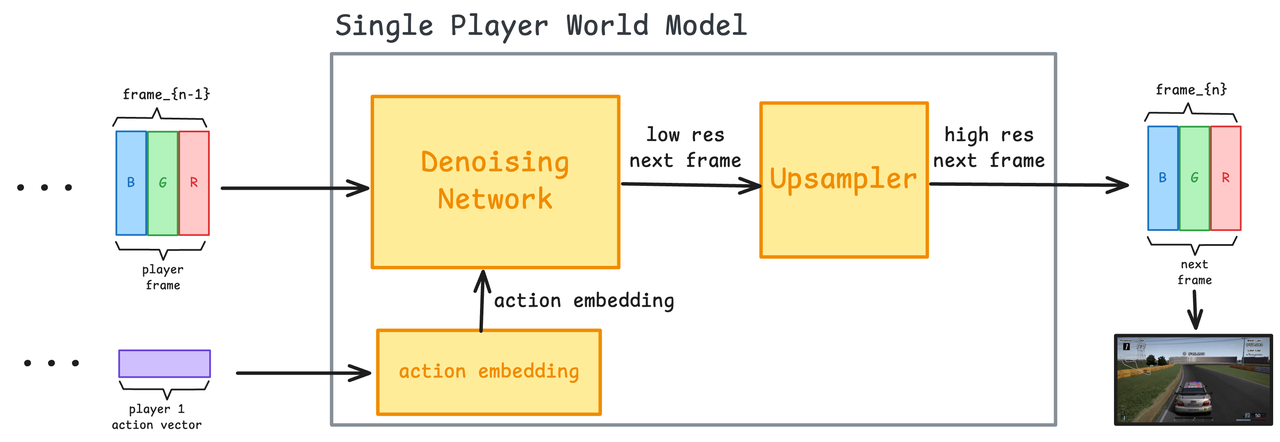
Prima di ciò, dobbiamo introdurre il tradizionale modello mondiale dell’intelligenza artificiale: tu lo gestisci e lui prevede come l’immagine deve essere generata. Il modello esamina le tue operazioni, esamina i frame precedenti e quindi genera il frame successivo. Il principio non è difficile da capire:
- Incorporamento di azioni: converte le operazioni del giocatore (come il tasto premuto) in vettori di incorporamento
- Rete di denoising: utilizza un modello di diffusione per prevedere il fotogramma successivo combinando operazioni e fotogrammi precedenti.
- Upsampler (opzionale): migliora la risoluzione e il dettaglio delle immagini generate
Ma una volta introdotto il secondo giocatore, il problema si complica.
Il bug più tipico è che l'auto dalla tua parte ha appena colpito il guardrail, ma quella dell'avversario sta ancora accelerando; ti butti fuori pista, ma l'avversario non vede nemmeno dove sei. L'intera esperienza di gioco è come due fotogrammi bloccati e non sincronizzati.
Multiverse è il primo modello mondiale di intelligenza artificiale in grado di sincronizzare le prospettive di due giocatori. Qualunque cosa accada a uno dei giocatori, l'altra persona può vederlo sul proprio schermo in tempo reale, senza ritardi o conflitti logici.
Anche questo è qualcosa che in passato era difficile da ottenere nelle simulazioni IA: la coerenza multi-vista.
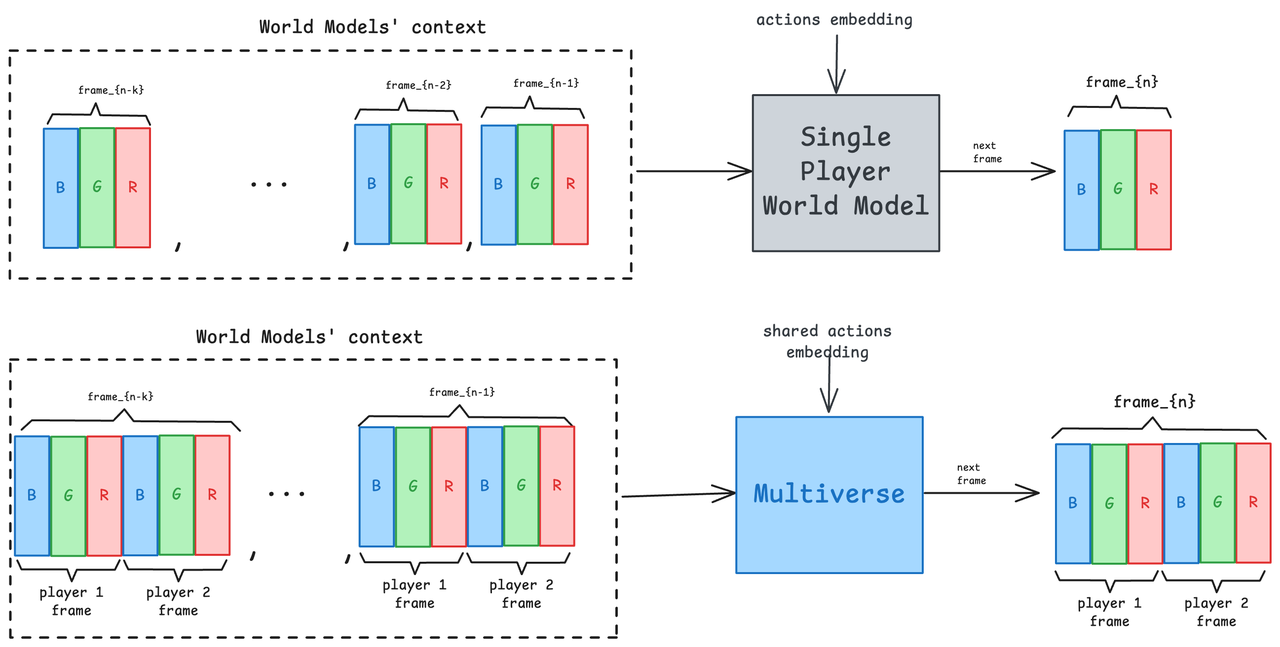
Per risolvere questo problema e costruire un modello mondiale multiplayer veramente collaborativo, il team Multiverse ha trovato una soluzione molto intelligente. Hanno mantenuto i componenti fondamentali e allo stesso tempo hanno completamente frantumato e ricostruito l'idea originale della "previsione per una sola persona":
- Incorporamento di azioni: riceve le azioni di due giocatori e genera un vettore di incorporamento che integra le operazioni di entrambe le parti;
- Rete di denoising: rete di diffusione, che genera immagini di due giocatori contemporaneamente per garantire che siano coerenti nel loro insieme;
- Upsampler: simile alla modalità a giocatore singolo, ma elabora e migliora il filmato per entrambi i giocatori contemporaneamente.
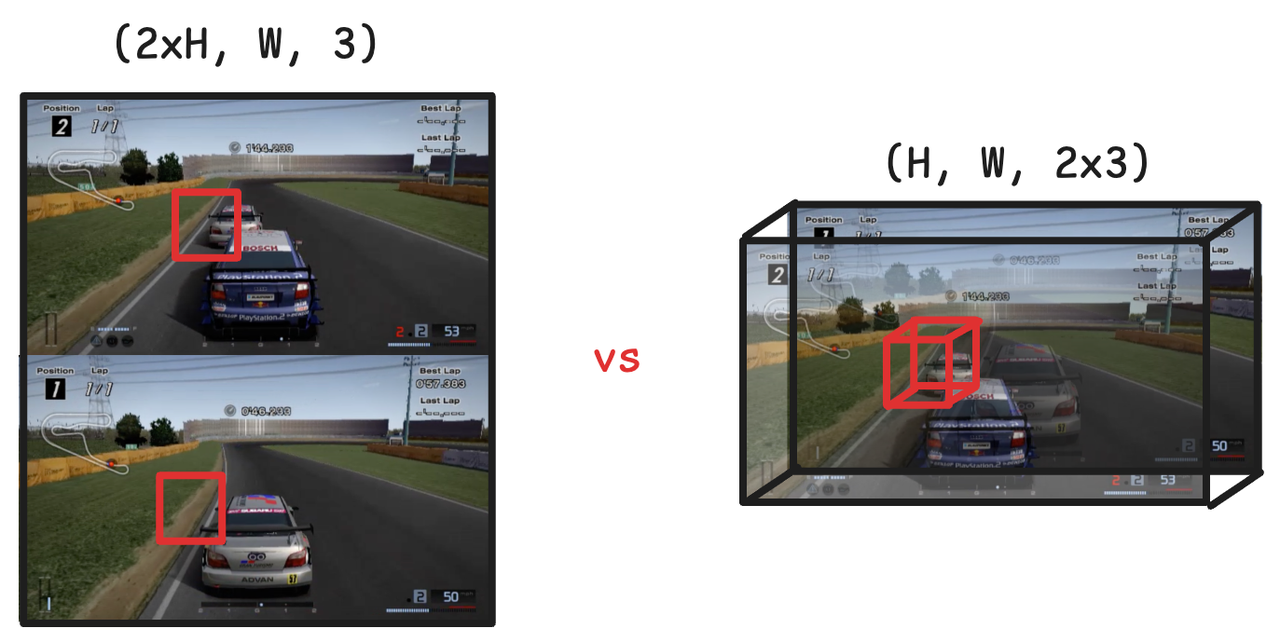
Originariamente, quando si trattava di un'immagine a due persone, la prima reazione di molte persone era quella di dividere lo schermo: separare le due immagini e generarle separatamente.
Questa idea è semplice e rozza, ma è difficile da sincronizzare, consuma risorse e ha scarsi effetti. Tuttavia, hanno pensato di "cucire" le prospettive dei due giocatori in un'unica immagine, unendo i loro input in un vettore d'azione unificato e trattando il tutto come una "scena unificata".
Il metodo specifico è l'impilamento dell'asse dei canali: trattare le due immagini come un'unica immagine con il doppio dei canali di colore.
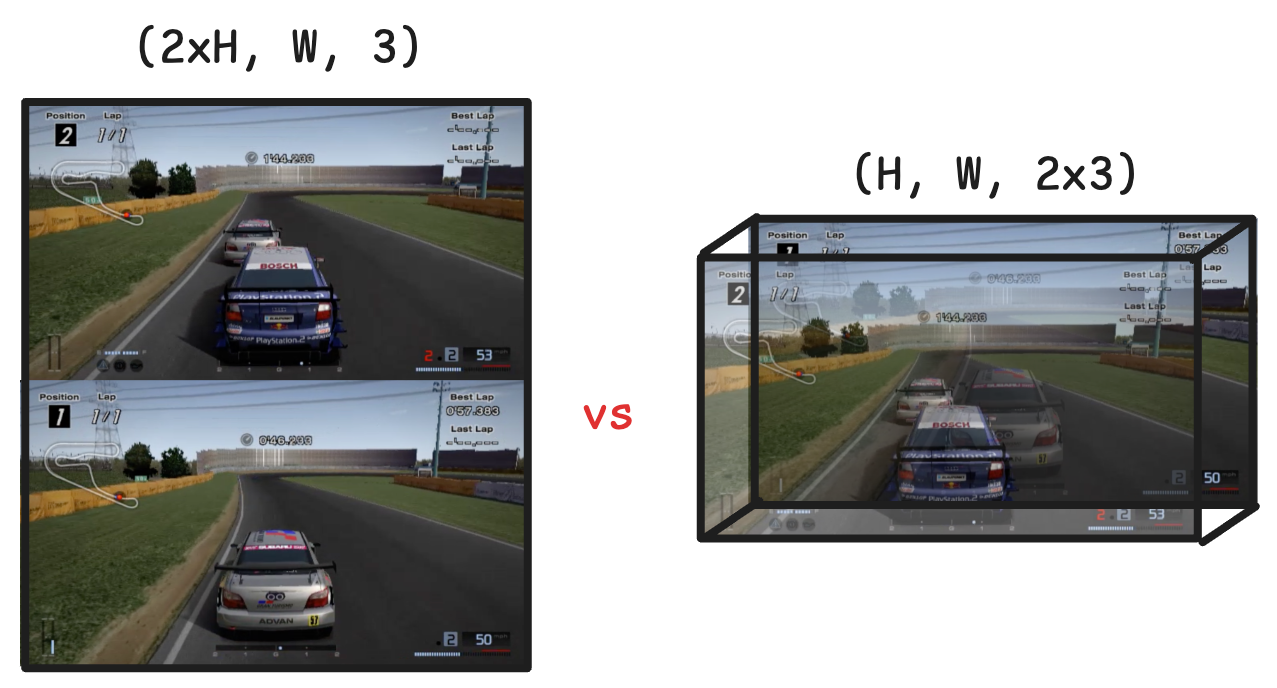
Questa cosa sembra piccola, ma in realtà è molto intelligente tecnicamente. Poiché il modello di diffusione utilizza l'architettura U-Net, il nucleo è costituito da convoluzione e deconvoluzione e la rete neurale convoluzionale ha una forte consapevolezza strutturale della dimensione del canale.
In altre parole, non si tratta di incollare due mondi insieme, ma di consentire al modello di sapere dallo “strato inferiore del neurone” che le due immagini sono correlate e devono essere generate in modo collaborativo. L'immagine finale non necessita di essere allineata manualmente, è naturalmente sincronizzata.
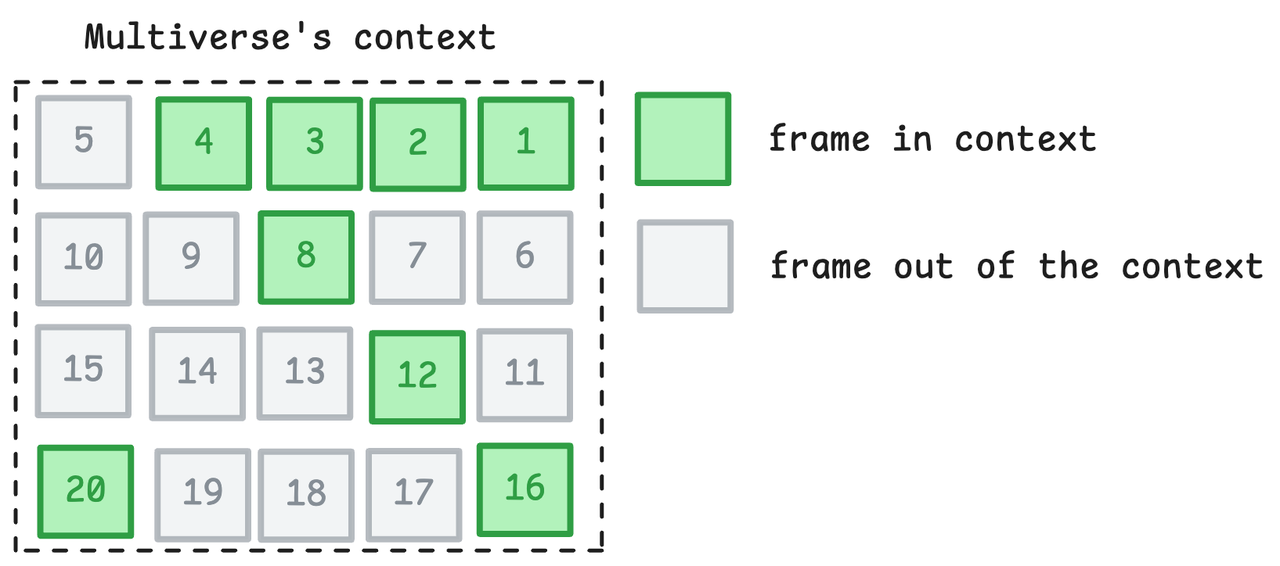
Ma affinché il modello possa prevedere con precisione il fotogramma successivo, è necessario comprendere una cosa: la velocità del veicolo e la posizione relativa sono dinamiche e devono essere disponibili informazioni sufficienti per una previsione accurata. Hanno scoperto che 8 fotogrammi (a 30 fps) sono sufficienti per apprendere funzionalità cinematiche come accelerazione, frenata e sterzata.
Ma il problema è che la velocità relativa, ad esempio in caso di sorpasso, è molto più lenta della velocità assoluta (circa 100 km/h contro 5 km/h). Se il numero di telaio è troppo vicino, il modello non percepisce affatto il cambiamento.
Quindi hanno progettato una soluzione di compromesso: campionamento sparso:
- Fornisce gli ultimi 4 frame consecutivi (garantendo una risposta immediata);
- Fornisce ulteriori 4 fotogrammi di immagini storiche "campionate ogni 4 fotogrammi";
- Il primo fotogramma è a 20 fotogrammi di distanza dal fotogramma corrente, ovvero circa 0,666 secondi fa.
Per consentire al modello di comprendere veramente la “guida cooperativa”, non può fare affidamento esclusivamente su questi dati di input, ma richiede anche una formazione intensiva sui comportamenti interattivi.
Le tradizionali attività per giocatore singolo (come camminare, sparare) richiedono solo la previsione per un breve intervallo di tempo, ad esempio 0,25 secondi. Tuttavia, nell'interazione di più persone, un cambiamento così piccolo nel tempo è minimo e non riflette affatto il "senso del lavoro di squadra".
La soluzione di Multiverse è semplicemente lasciare che il modello preveda una sequenza comportamentale fino a 15 secondi per catturare la logica di interazione a lungo termine e multi-round.
Il metodo di allenamento non prevede solo 15 secondi alla volta, ma utilizza una strategia di "apprendimento curriculare": partire da 0,25 secondi di previsione, per poi estenderlo gradualmente fino a 15 secondi. In questo modo, il modello apprende prima caratteristiche di basso livello come la struttura dell'auto e la geometria della pista, per poi padroneggiare lentamente concetti di alto livello come le strategie dei giocatori e le dinamiche di gioco.
Dopo l'addestramento, le prestazioni del modello in termini di persistenza degli oggetti e coerenza tra frame sono state notevolmente migliorate. Insomma, l’auto non scomparirà all’improvviso, né crollerà la logica.
Prestazioni di allenamento così eccellenti sono attribuite al set di dati accuratamente selezionato alla base. Esatto, è il capolavoro di simulazione di corse per PS2 del 2004: Gran Turismo 4.
Naturalmente, per evitare responsabilità, il team Multiverse non ha dimenticato di scherzare sul fatto che sono fan sfegatati di Sony.
La scena del test era una gara uno contro uno sul circuito di Tsukuba, ma il problema è che GT4 non supporta nativamente il "replay prospettico 1v1". Quindi hanno effettuato il reverse engineering e trasformato il gioco in una vera modalità 1v1.
Poi:
- Registra ogni partita due volte, una volta per vedere te stesso e una volta per vedere il tuo avversario;
- Quindi, attraverso l'elaborazione della sincronizzazione, viene unito in un video completo, che mostra la battaglia in tempo reale tra le due parti.
E i dati chiave? Dopotutto, il gioco stesso non fornisce registri delle operazioni.
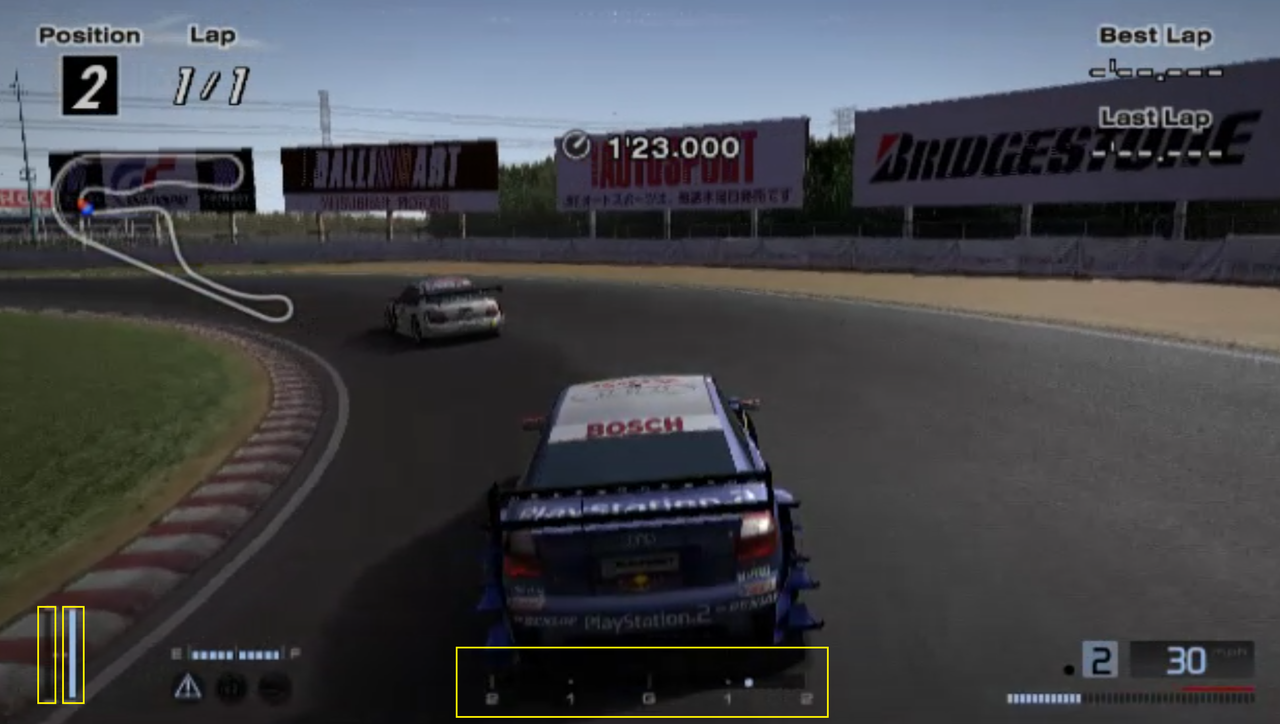
La risposta è che utilizzano le informazioni visualizzate dall'HUD del gioco (barre indicatrici dell'acceleratore, del freno e del volante), utilizzano la visione artificiale per estrarre le barre dell'acceleratore, del freno e della direzione visualizzate sullo schermo di gioco fotogramma per fotogramma e quindi derivano le istruzioni di controllo.
In altre parole, l'operazione può essere ripristinata esclusivamente basandosi sulle informazioni visualizzate sullo schermo, senza la necessità di file di registro aggiuntivi.
Naturalmente, questo processo è inefficiente ed è impossibile registrare manualmente ogni partita due volte.
Hanno scoperto che GT4 ha una funzionalità nascosta chiamata modalità B-Spec, che consente all'IA di guidare da sola. Quindi ho scritto uno script per inviare istruzioni casuali all'IA, permettendole di correre e bloccarsi da sola, generando così set di dati in batch.
A proposito, hanno anche provato a utilizzare il modello di guida autonoma di OpenPilot per controllare i personaggi del gioco. Sebbene l’effetto sia stato buono, in termini di efficienza e stabilità, B-Spec è più adatto per allenamenti su larga scala.
Ecco il punto chiave: parlare di effetti senza parlare di costi è naturalmente un teppismo.
Un modello di intelligenza artificiale in grado di eseguire mondi multi-vista, sincronizzare immagini e stabilizzare l’output, inclusi modello, training, dati e inferenza, costa solo 1.500 dollari, che equivale più o meno all’acquisto di una scheda grafica di fascia alta.

Il dipendente della Multiverse Jonathan Jacobi ha pubblicato su X:
Abbiamo costruito Multiverse con soli $ 1.500. La chiave non è la potenza di calcolo, ma l’innovazione tecnologica.
Ancora più importante, Jacobi ritiene che il modello mondiale multiplayer non sia solo un nuovo modo per l’intelligenza artificiale di giocare, ma anche il passo successivo nella tecnologia di simulazione. Sblocca un mondo completamente nuovo: un ambiente dinamico co-evoluto e co-modellato da giocatori, agenti e robot.
In futuro, il modello mondiale potrebbe essere come una versione virtuale della società reale: tu e l'intelligenza artificiale coesistete in esso, formando un "universo dinamico" altamente realistico che ha anche una logica di interazione complessa vicina alla società reale.
Allora, ti sembra un po' allegro?
In allegato l'indirizzo di riferimento:
GitHub: https://github.com/EnigmaLabsAI/multiverse
Set di dati di Hugging Face: https://huggingface.co/datasets/Enigma-AI/multiplayer-racing-low-res
Modello Hugging Face: https://huggingface.co/Enigma-AI/multiverse
Blog ufficiale: https://enigma-labs.io/blog
# Benvenuti a seguire l'account pubblico WeChat ufficiale di Aifaner: Aifaner (ID WeChat: ifanr). Contenuti più interessanti ti verranno forniti il prima possibile.
Ai Faner | Link originale · Visualizza commenti · Sina Weibo
