
Il punteggio cinese è al primo posto nel mondo ed è pari a GPT4o in più test alla cieca. Come mai questo grande modello domestico è diventato un cavallo oscuro nel mondo dell’intelligenza artificiale?

Tutto è come se avesse un motore V12.
Il 13 di questo mese, Kai-Fu Lee e Zero One Wish hanno rilasciato il loro secondo prodotto, il modello closed source Yi-Large. In meno di mezzo mese dalla sua uscita, Yi-Large è passato da una nuova generazione che non ha paura delle tigri a un gruppo potente che è in vantaggio sulle onde del fiume Yangtze.
La settimana scorsa, un modello misterioso chiamato "im-anche-un-buon-gpt2-chatbot" è apparso improvvisamente nella grande arena di modelli Chatbot Arena, classificandosi direttamente più in alto di GPT-4-Turbo, Gemini 1 .5 Pro, Claude 3 0pus, Llama-3-70b e altri modelli base popolari dei principali produttori internazionali.
Questo modello misterioso è la versione di prova di GPT-4o, anche il CEO di OpenAI Sam Altman ha ripubblicato e citato personalmente i risultati del test cieco dell'arena LMSYS dopo il rilascio di GPT-4o.
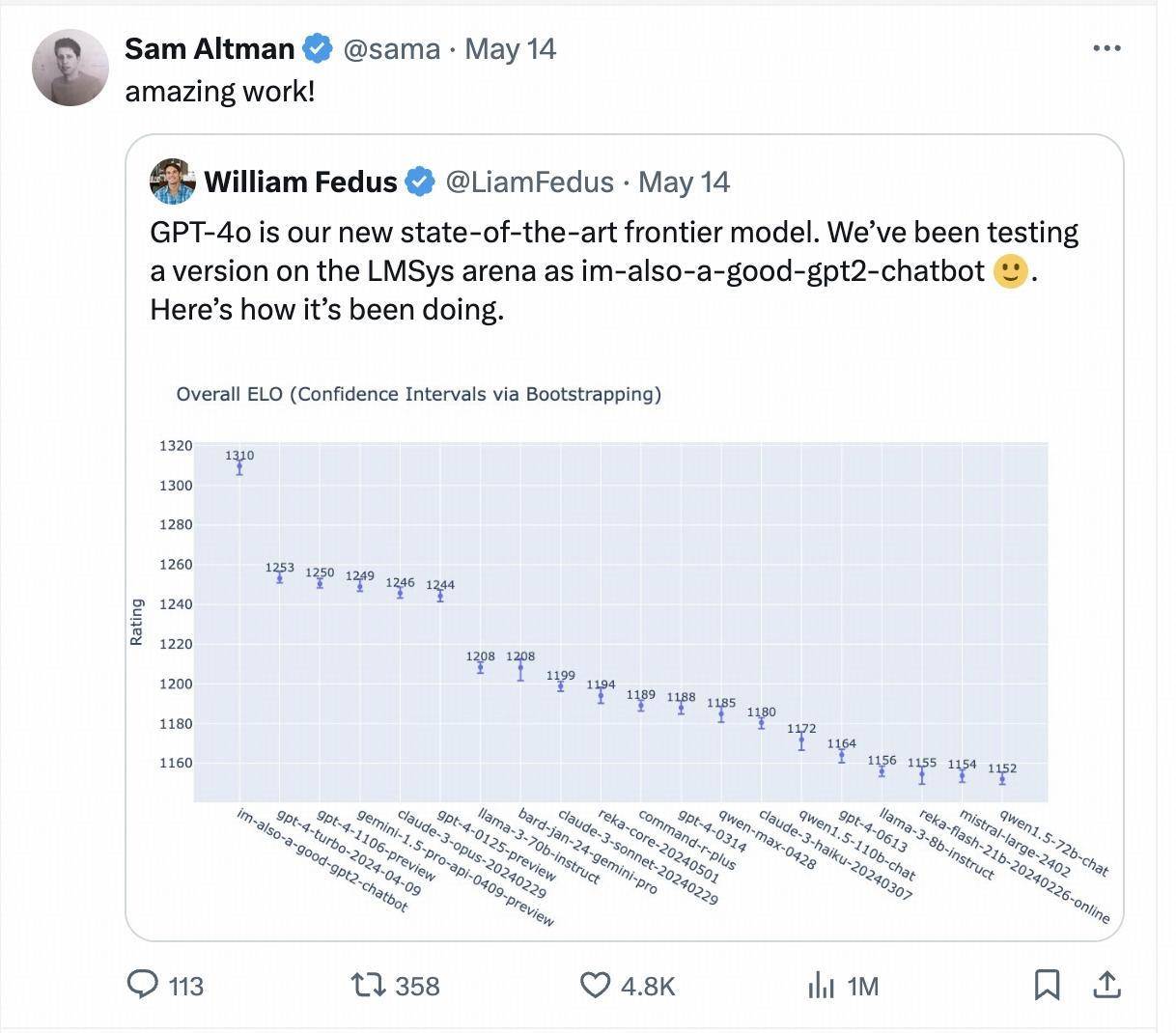
Una settimana dopo, nell'ultima classifica aggiornata, è stata messa in scena ancora una volta la storia del cavallo oscuro di "sono anche un bravo chatbot gpt2". Questa volta il modello che è salito rapidamente nella classifica è stato presentato dal grande cinese società modello Zero One Wan. Il grande modello closed-source "Yi-Large" con centinaia di miliardi di parametri.
Nell'ultima classifica della LMSYS Blind Test Arena, Yi-Large, l'ultimo modello da 100 miliardi di parametri di Yi-Large, si colloca al 7° posto nel mondo e al 1° tra i modelli di grandi dimensioni in Cina, superando Llama-3-70B e Claude 3 Sonnet. La sua classifica cinese è alla pari con GPT4o per il primo posto nel mondo.
Chatbot Arena, lanciata dall'organizzazione di ricerca aperta LMSYS Org (Large Model Systems Organization), è diventata una competizione testa a testa per grandi aziende internazionali come OpenAI, Anthropic, Google e Meta, e ha anche aperto una funzione di voto di massa .
Lingyiwuwu è così diventata l'unica grande azienda di modelli cinese con i propri modelli nella top ten della classifica generale.
Nell'elenco generale, la serie GPT rappresenta 4 delle prime 10. Ordinata per istituzione, 01W01.AI è seconda solo a OpenAI, Google e Anthropic ed è ufficialmente entrata nel campo dei grandi modelli aziendali più importante al mondo.
Ora sembra che lo slogan "Diventa il numero 1 al mondo" non sia solo uno slogan, ma lo stia diventando.
Il punteggio cinese è al primo posto nel mondo e il test cieco "bruciacervelli" è al secondo posto nel mondo.
I risultati del blind test di LMSYS Chatboat Arena, appena aggiornati il 20 maggio 2024, ora degli Stati Uniti, provengono dai voti reali di oltre 11,7 milioni di utenti globali accumulati finora.
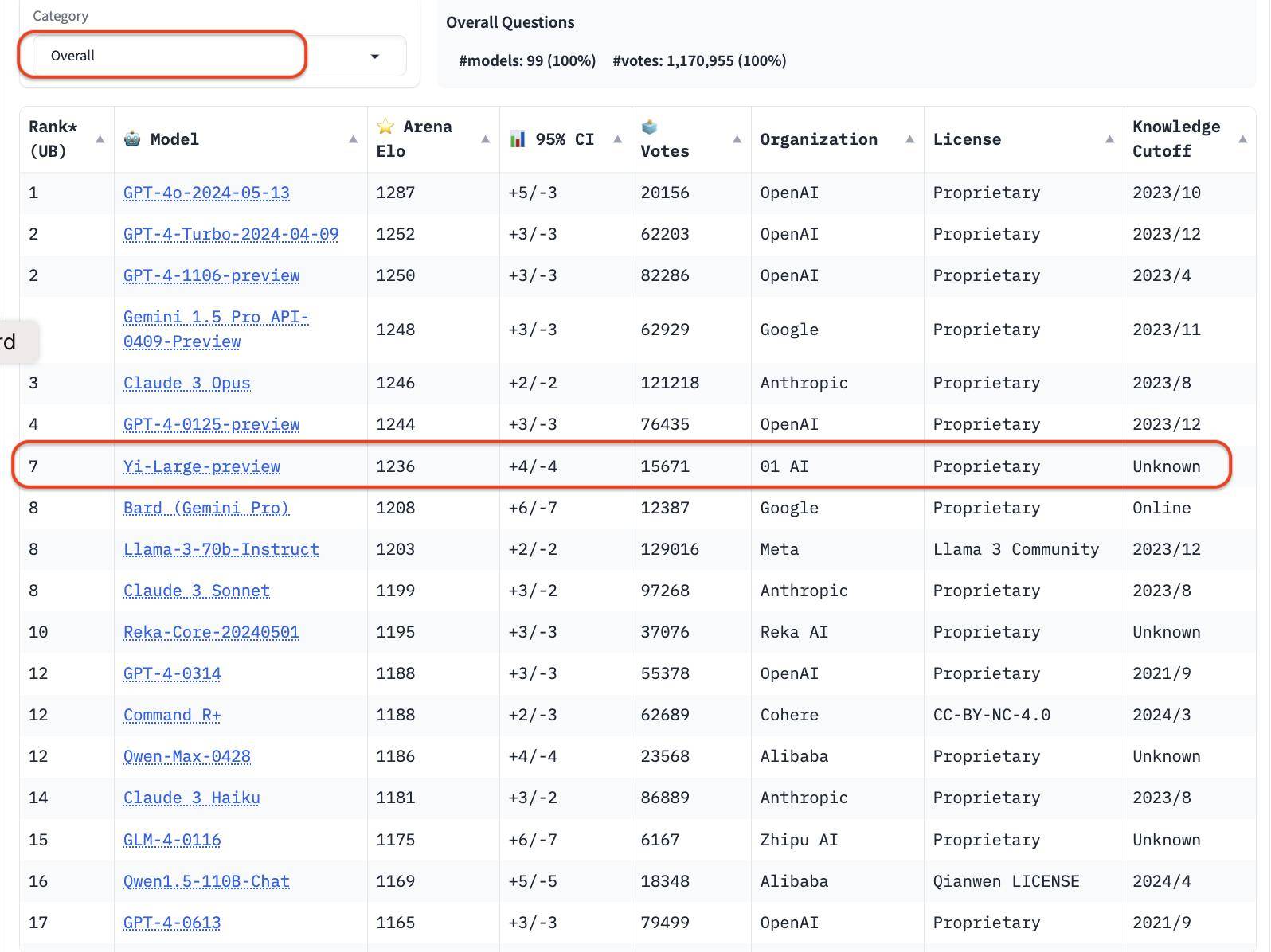
Vale la pena ricordare che, al fine di migliorare la qualità complessiva delle query di Chatbot Arena, LMSYS ha anche implementato un meccanismo di deduplicazione e ha pubblicato un elenco dopo aver rimosso le query ridondanti.
Questo nuovo meccanismo è progettato per eliminare richieste utente eccessivamente ridondanti, come "Ciao" eccessivamente ripetitivo, che potrebbero influire sulla precisione delle classifiche.
LMSYS ha dichiarato pubblicamente che l'elenco dopo aver rimosso le query ridondanti diventerà l'elenco predefinito in futuro.
Nell'elenco generale, dopo aver rimosso le query ridondanti, il punteggio Elo di Yi-Large è andato ancora oltre, classificandosi al quarto posto con Claude 3 Opus e GPT-4-0125-preview.
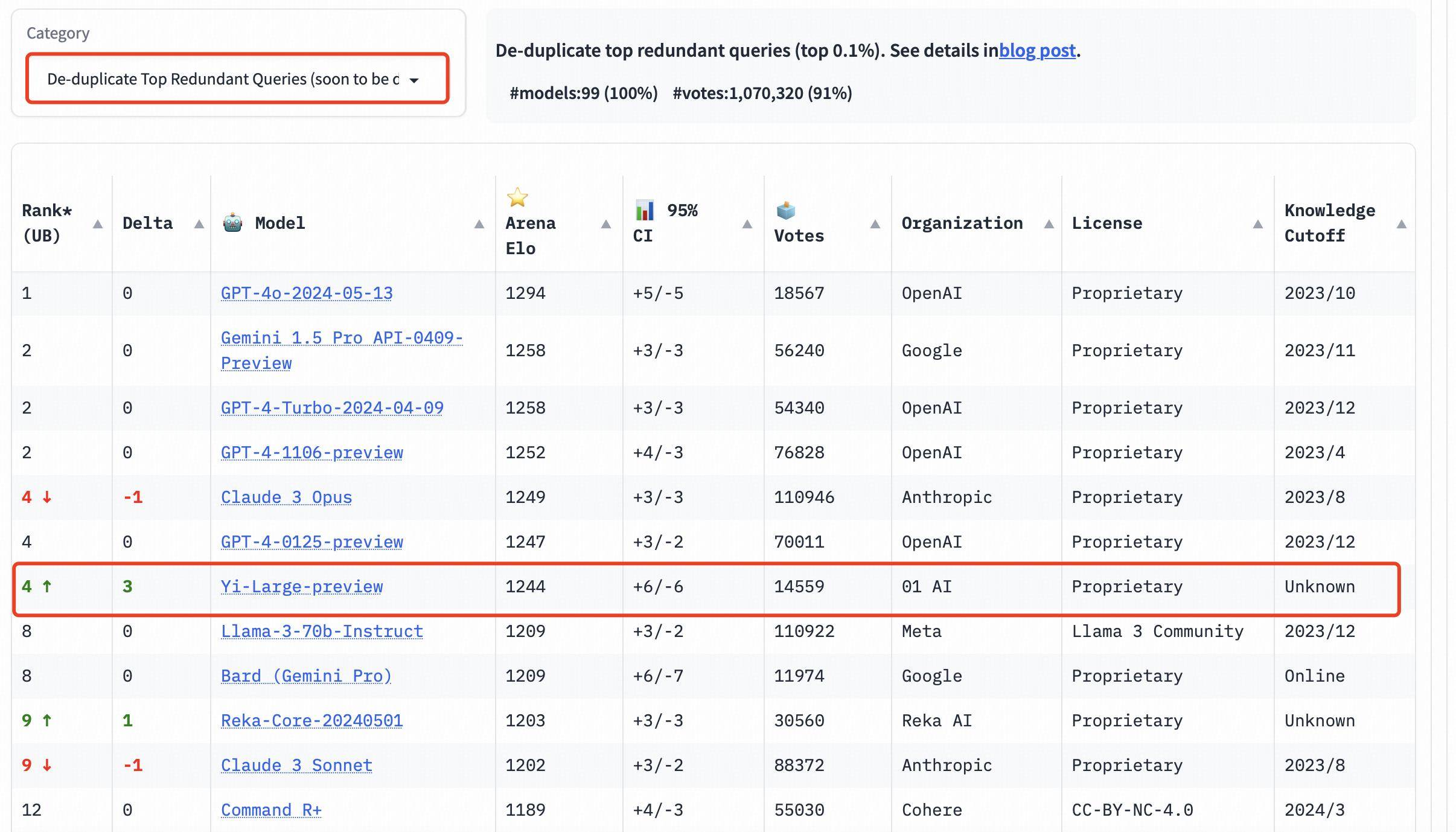
Oltre all'elenco generale, LMSYS ha aggiunto tre nuove valutazioni linguistiche in inglese, cinese e francese e ha iniziato a concentrarsi sulla diversità dei grandi modelli globali. Yi-Large è in cima alla lista delle lingue cinesi, a pari merito con GPT4o e Qwen-Max e GLM-4 si sono comportati bene anche nella lista delle lingue cinesi.
Tra i grandi produttori di modelli nazionali, Qwen-Max di Alibaba e GLM-4 di Zhipu si sono comportati entrambi eccezionalmente bene.
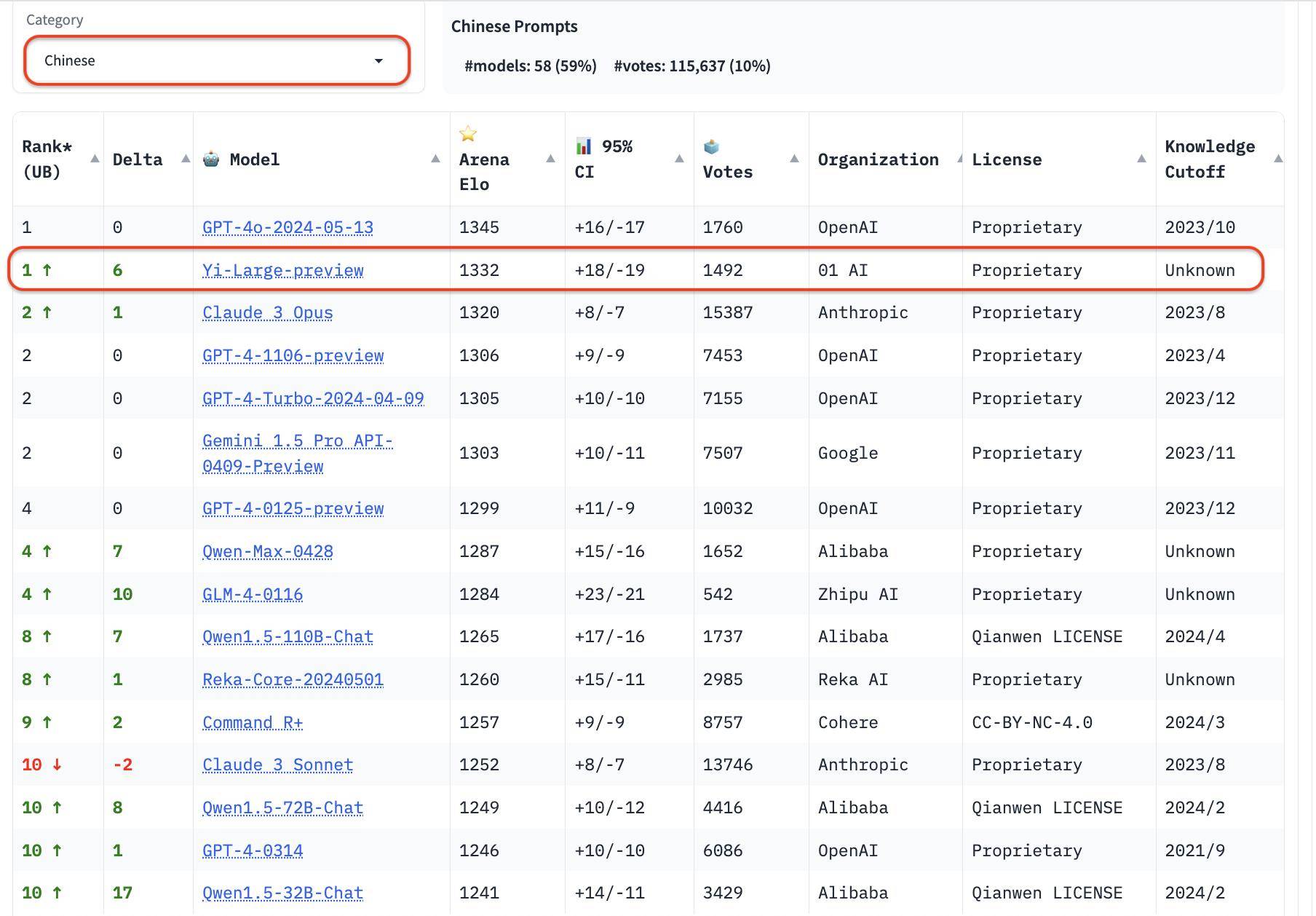
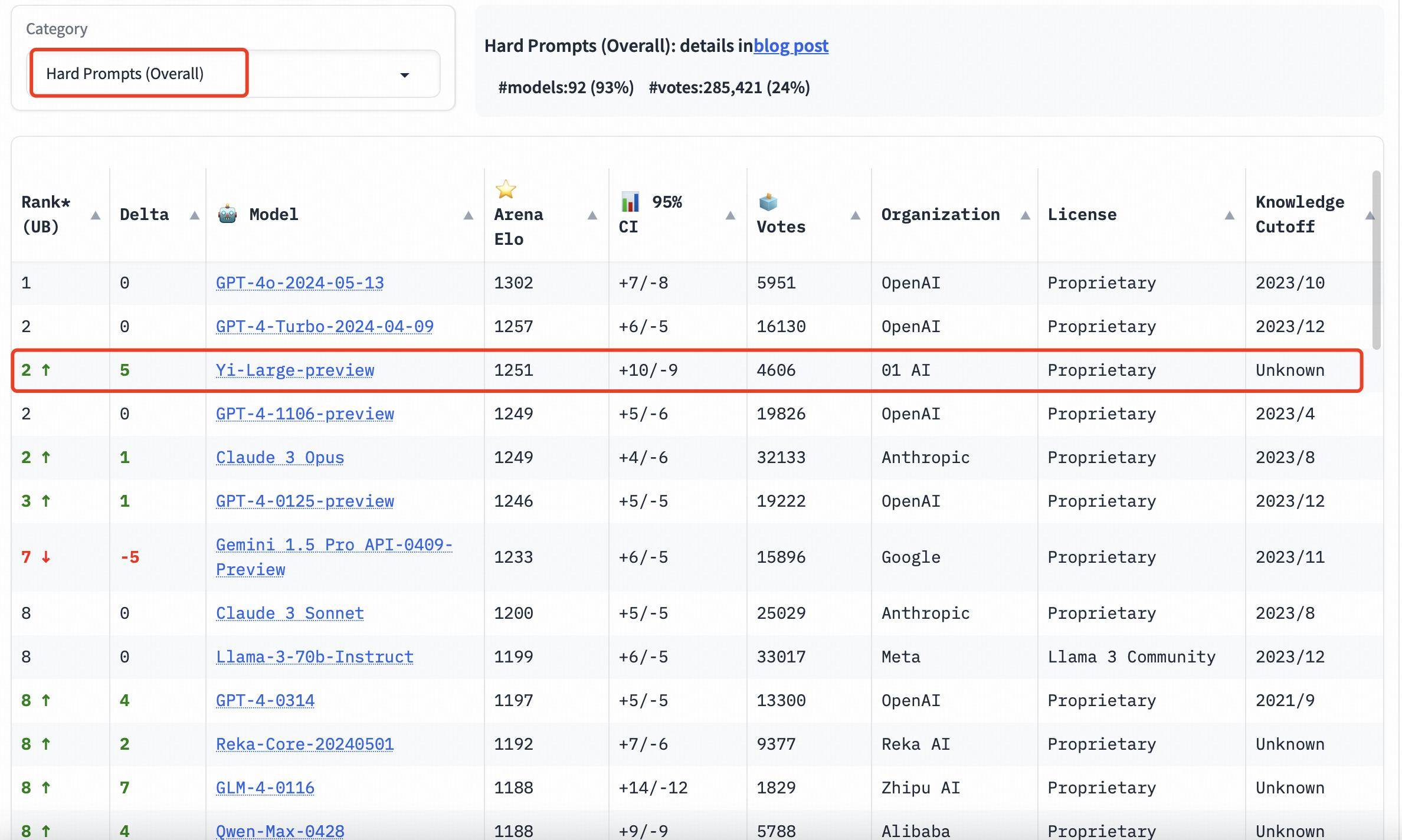
Nella classifica di categoria, anche Yi-Large si comporta bene. Le tre valutazioni di capacità di programmazione, domande lunghe e le ultime "parole difficili" sono elenchi mirati forniti da LMSYS. Sono famosi per la loro professionalità e l'elevata difficoltà. Possono essere definiti la cecità pubblica "più bruciante" dei grandi modelli Misurazione.
Le tre valutazioni dell'abilità di programmazione, le domande lunghe e le ultime "parole difficili" sono professionali e difficili. È anche noto come il test cieco pubblico "più bruciante" nell'elenco LMSYS.
Nelle classifiche delle capacità di programmazione (codifica), il punteggio Elo di Yi-Large supera quello di Claude 3 Opus di Anthropic, è inferiore solo a GPT-4o e si colloca al secondo posto con GPT-4-Turbo e GPT-4;
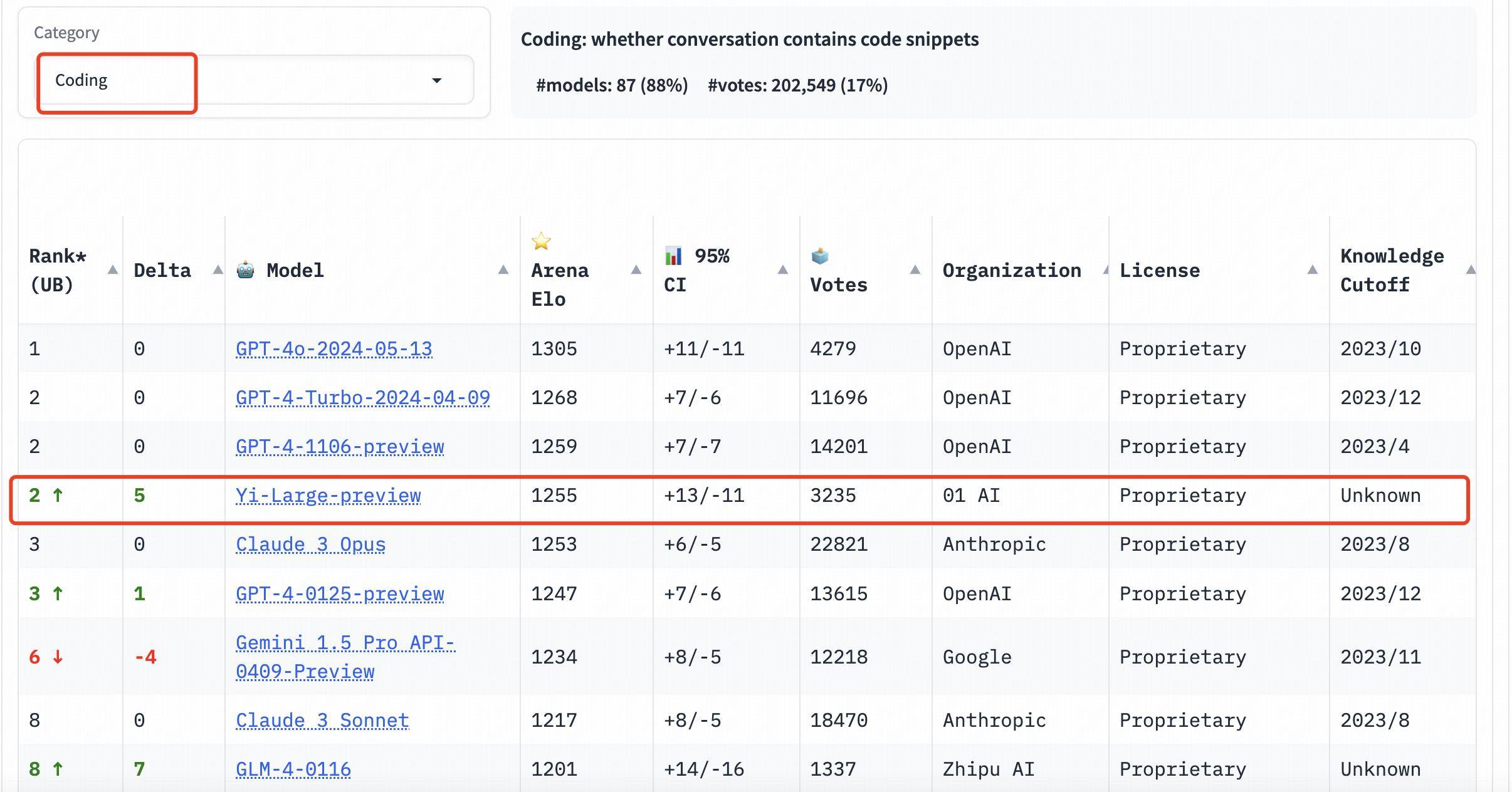
Nell'elenco delle query più lunghe, Yi-Large è anche al secondo posto nel mondo, a pari merito con GPT-4-Turbo, GPT-4 e Claude 3 Opus;

Nell'elenco dei suggerimenti difficili, Yi-Large è al secondo posto a pari merito con GPT-4-Turbo, GPT-4 e Claude 3 Opus.
Utilizzare metodi scientifici per ottenere risultati oggettivi
Come fornire una valutazione obiettiva ed equa di modelli di grandi dimensioni è sempre stato un argomento di diffusa preoccupazione nel settore.
In precedenza, nel settore sono esistiti vari metodi per "scansionare le classifiche", ma non sono sempre stati in grado di riflettere le reali capacità dei grandi modelli, lasciando nella nebbia le persone che vogliono capire e gli investitori nei settori correlati a grattarsi la testa. .
La Chatbot Arena rilasciata da LMSYS Org inizia a rompere questo caos.
Con il suo nuovo formato "arena" e il rigore del team di test, è diventato un punto di riferimento riconosciuto dall'industria globale. Anche OpenAI è stato pre-rilasciato e pre-testato in modo anonimo su LMSYS prima del rilascio ufficiale di GPT-4o.
Andrej Karpathy, membro fondatore del team OpenAI, ha dichiarato pubblicamente:
Chatbot Arena è fantastica.
Dal punto di vista formale, Chatbot Arena si ispira alle idee di valutazione comparativa orizzontale dell’era dei motori di ricerca:
- Innanzitutto, tutti i modelli "di ingresso" caricati per la valutazione vengono abbinati casualmente a coppie e presentati agli utenti sotto forma di modelli anonimi;
- Quindi gli utenti reali vengono invitati a inserire le proprie parole rapide e gli utenti reali valuteranno le risposte ai due prodotti modello senza conoscere il nome del modello;
- Quindi, sulla piattaforma di blind test https://arena.lmsys.org/, i modelli di grandi dimensioni vengono confrontati a coppie e l'utente inserisce in modo indipendente domande sui modelli di grandi dimensioni;
- Il modello A e il modello B generano rispettivamente i risultati reali di due modelli PK su entrambi i lati. Gli utenti possono votare sotto i risultati per sceglierne uno tra quattro: il modello A è migliore/il modello B è migliore/entrambi sono in parità/entrambi non sono buoni;
- Dopo l'invio, è possibile condurre il turno successivo di PK.
Attraverso il crowdfunding di utenti reali per condurre test online in tempo reale e votazioni anonime, Chatbot Arena da un lato riduce l'impatto dei bias, dall'altro massimizza anche la possibilità di evitare classifiche basate sul test set, aumentando così l'obiettività dei risultati finali.
Chatbot Arena rende inoltre pubblici tutti i dati di voto degli utenti dopo che sono stati puliti e resi anonimi.
Dopo aver raccolto i dati di voto degli utenti reali, LMSYS Chatbot Arena utilizzerà anche il sistema di punteggio Elo per quantificare le prestazioni del modello, ottimizzare ulteriormente il meccanismo di punteggio e sforzarsi di riflettere equamente la forza dei partecipanti.
Nel sistema di punteggio Elo, ogni partecipante riceve un punteggio di base e, dopo ogni partita, il punteggio del partecipante viene modificato in base ai risultati della partita.
Il sistema calcolerà la probabilità di vincere la partita in base alla valutazione del partecipante. Una volta che un giocatore con il punteggio basso sconfigge un giocatore con il punteggio alto, il giocatore con il punteggio basso otterrà più punti e viceversa.
Introducendo il sistema di punteggio Elo, LMSYS Chatbot Arena garantisce in larga misura l'obiettività e l'equità della classifica.
Usa poco per vincere alla grande
Questa volta alla Chatbot Arena hanno partecipato 44 modelli in totale, tra cui sia il modello open source Llama3-70B sia i modelli closed source dei principali produttori.
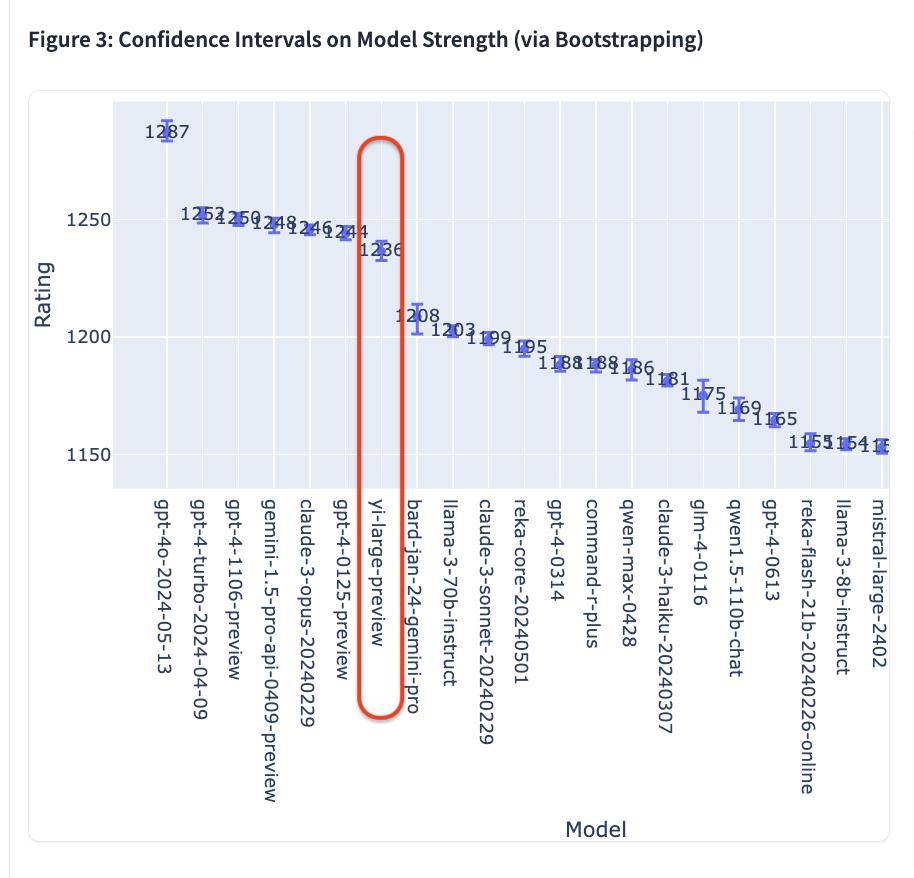
- A giudicare dall’ultimo punteggio Elo, GPT-4o è in cima alla lista con un punteggio di 1287;
- GPT-4-Turbo, Gemini 1 5 Pro, Claude 3 0pus, Yi-Large e altri modelli sono nella seconda fascia con punteggi intorno a 1240;
- Successivamente, i punteggi di Bard (Gemini Pro), Llama-3-70b-Instruct e Claude 3 sonetto sono scesi da un dirupo a circa 1200 punti.
Vale la pena ricordare che i primi 6 modelli appartengono rispettivamente ai giganti d'oltremare OpenAI, Google e Anthropic, al quarto posto nel mondo, e modelli come GPT-4 e Gemini 1.5 Pro hanno tutti parametri di livello It è il modello di punta in scala, e anche altri modelli sono a livello di parametri di centinaia di miliardi.
Yi-Large "prende il piccolo per vincere alla grande", segue da vicino con un livello di parametro di soli 100 miliardi.

Lo sviluppo competitivo dei grandi modelli di intelligenza artificiale è ancora in una fase feroce e la "battaglia di centinaia di modelli" dell'intelligenza artificiale continuerà ad essere messa in scena in questo campo in cui le "settimane" o addirittura i "giorni" vengono utilizzati come unità di iterazione. esiste un sistema di valutazione relativamente giusto e obiettivo. Diventa particolarmente importante.
Una piattaforma di valutazione che aggiorna continuamente il sistema di punteggio può non solo consentire agli investitori del settore di vedere il vero stato dello sviluppo tecnologico, ma anche consentire agli utenti di avere il diritto di scegliere modelli avanzati e può anche promuovere il sano sviluppo dell'intero settore dei grandi modelli .
Che si tratti dell'iterazione delle capacità dei propri modelli o dal punto di vista della reputazione a lungo termine, i grandi produttori di modelli dovrebbero partecipare attivamente a piattaforme di valutazione autorevoli come Chatbot Arena per dimostrare i propri prodotti attraverso il feedback effettivo degli utenti e meccanismi di valutazione professionale.
Al contrario, se ci si preoccupa solo dei risultati delle classifiche e si ignora l’effettivo effetto applicativo del modello, il divario tra le capacità del modello e la domanda del mercato diventerà più evidente, e alla fine sarà difficile prendere piede nella feroce intelligenza artificiale. concorrenza di mercato.
Nell'onda dell'era dell'intelligenza artificiale, se i principali produttori di modelli vogliono essere eccellenti o addirittura di prim'ordine, hanno bisogno di almeno due qualità:
- Devo esaminarmi tre volte al giorno: acquisire esperienza attraverso il progresso e ottenere risposte attraverso la competizione;
- Il vero oro non ha paura del fuoco: piuttosto che essere il primo nella "lista selvaggia", è meglio guardarsi dentro e migliorare le proprie vere capacità.
Ciò che vale la pena aspettarsi è che ora esiste un gruppo di eccellenti produttori nazionali di modelli su larga scala che sono con i piedi per terra, innovano nella ricerca e nello sviluppo e possono persino competere con i giganti del settore sulla scena internazionale.
Indirizzo di votazione pubblica della LMSYS Chatbot Arena Blind Test Arena: https://arena.lmsys.org/
Classifica di valutazione della classifica LMSYS Chatbot Leaderboard (aggiornamento progressivo): https://chat.lmsys.org/?leaderboard
# Benvenuto per seguire l'account pubblico WeChat ufficiale di Aifaner: Aifaner (ID WeChat: ifanr) Ti verranno forniti contenuti più interessanti il prima possibile.
Ai Faner |. Link originale · Visualizza commenti · Sina Weibo
