
In questa lista di soluzioni open source “da popolari a poco quotate”, finalmente capisco perché l’intelligenza artificiale cinese è riuscita a tornare in auge.
Negli ultimi giorni è stato ampiamente diffuso su X un elenco di livelli per un modello open source.

▲ Fonte dell'immagine: https://www.interconnects.ai/p/2025-open-models-year-in-review
Dall'alto verso il basso, i modelli open source sviluppati a livello nazionale si classificano tra i migliori, con DeepSeek, Qwen, Kimi, Zhipu e MiniMax tra i primi cinque modelli open source globali. OpenAI, invece, si classifica al quarto posto. Meta e Llama di Zuckerberg, che ha cercato di costruire rubando metà dei talenti della Silicon Valley, hanno ricevuto solo una nomination onoraria.
Questa classifica non è il risultato di pubblicità a pagamento da parte di modelli sviluppati a livello nazionale, né di autopromozione cinese. Un articolo pubblicato su Interconnectai dal rinomato ricercatore di intelligenza artificiale Nathan Lambert e da Florian Brand, dottorando presso il Centro di ricerca tedesco per l'intelligenza artificiale, fornisce una classifica completa dei modelli open source a livello mondiale.

▲Nathan Lambert ha lavorato presso Meta, DeepMind e Hugging Face.
L'articolo fornisce una panoramica dettagliata dello sviluppo dei modelli open source globali nell'ultimo anno, evidenziando come i modelli open source nazionali, principalmente DeepSeek e Qwen, stiano cambiando le regole operative dell'intero settore dell'intelligenza artificiale attraverso l'open source .
In effetti, il 2024 potrebbe ancora essere l'anno dell'open source globale secondo Llama. Quest'anno, tuttavia, l'open source sviluppato a livello nazionale ha avuto un impatto significativo, ridefinendo continuamente le opzioni predefinite nei modelli open source globali.
Prestazioni, prezzo, ecosistema, usabilità… si sta rapidamente avvicinando ai giganti closed-source in ogni dimensione e li ha persino superati in alcuni aspetti.

▲Cronologia delle versioni del modello open source USA-Cina, gennaio 2024 – novembre 2025. Fonte dell'immagine: https://www.atomproject.ai/
Mentre ci chiediamo ancora quando i modelli nazionali riusciranno a raggiungere ChatGPT e Gemini, un'altra domanda ha iniziato a farsi strada nella corsa agli armamenti dell'intelligenza artificiale: perché gli sviluppatori di tutto il mondo utilizzano modelli open source nazionali?
Modello open source, a cui partecipano sia attori affermati che emergenti.
Negli ultimi mesi, il ritmo degli aggiornamenti dei modelli open source sviluppati a livello nazionale è stato pressoché incessante. E non si tratta solo della svolta di una singola azienda produttrice di modelli, ma dell'intero ecosistema open source nazionale, che continua a spingere i limiti come una curva in rapida ascesa, superando costantemente i colli di bottiglia.
A novembre, Kimi ha rilasciato Kimi K2 Thinking, un modello esperto ibrido con migliaia di miliardi di parametri, che ha immediatamente raggiunto la vetta di numerose classifiche, superando persino GPT-5 di OpenAI e Claude 4.5 di Anthropic.
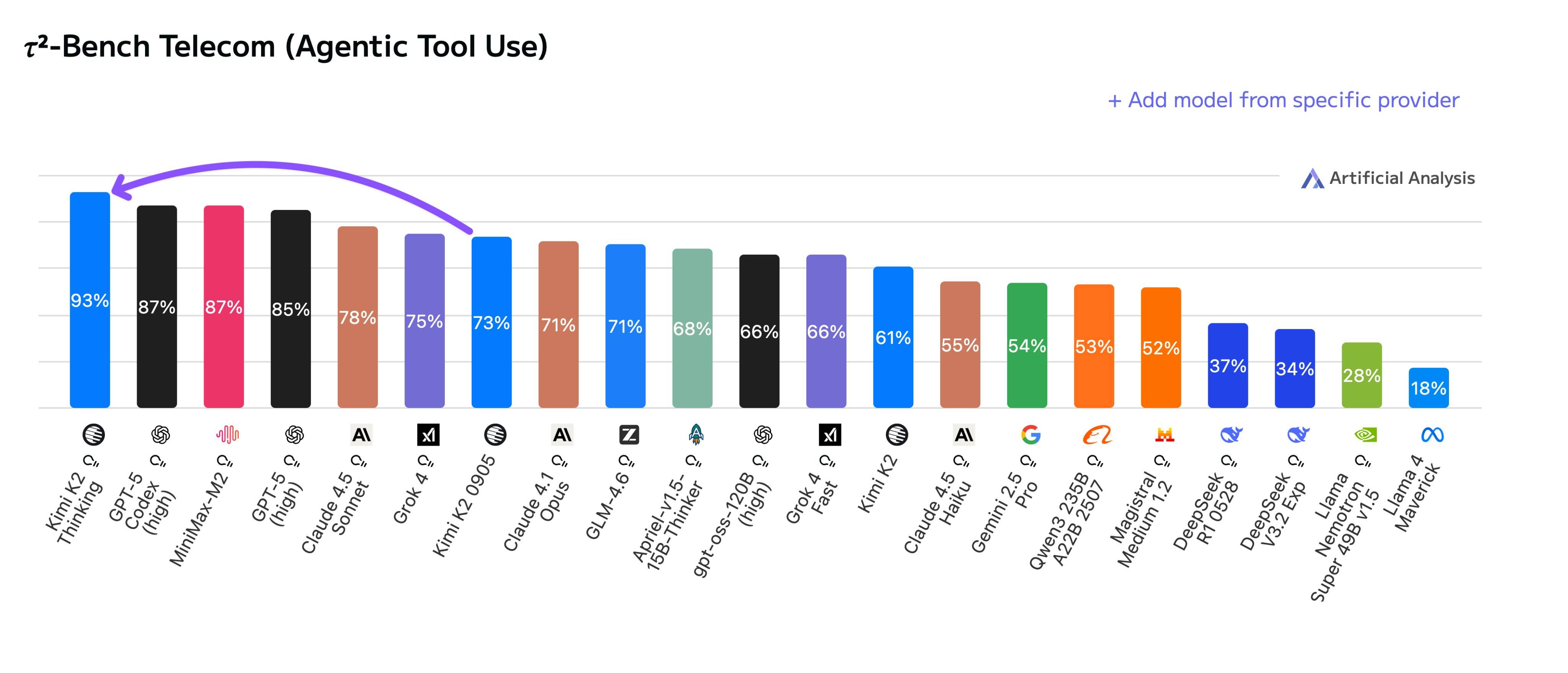
A fine ottobre, MiniMax ha ufficialmente rilasciato il modello ibrido esperto MiniMax M2, MoE. Come Kimi, rimane open source. In termini di prestazioni complessive, il MiniMax M2 si è classificato al quinto posto, superando Gemini 2.5 Pro e Claude Opus 4.1.
A settembre, alla conferenza Yunqi, Alibaba ha lanciato una serie di sette modelli, raggiungendo l'eccellenza in molteplici campi quali la visione, la parola, il ragionamento e la programmazione.
Sui social media esteri, il riconoscimento dei modelli open source cinesi è stato costante fin dalla nascita di DeepSeek. "Facile da usare, economico, la prima scelta per lo sviluppo delle piccole aziende, i miei progetti paralleli utilizzano modelli open source cinesi…" Questi commenti sono ovunque su X.
Ad esempio, gli internauti hanno elogiato lo stile di scrittura di Kimi K2 Thinking e il suo utilizzo di token per scambiare profondità di pensiero.
Alcuni utenti hanno anche paragonato Minimax M2 a Claude Sonnet 4, affermando che M2 può generare un sito web completamente funzionante con un solo utilizzo, mentre Sonnet 4 fallirà.

Ci sono ancora più post su Qwen. Dalla versione 2.5 all'attuale 3.0, da un modello di grandi dimensioni con 480 miliardi di parametri a un modello di piccole dimensioni con soli 600 milioni di parametri, dal linguaggio visuale Qwen 3 VL alla programmazione Qwen 3 Coder, Qwen è presente in quasi tutto il mercato open source.
In un'intervista, il CEO di Airbnb ha addirittura dichiarato apertamente che, sebbene OpenAI sia valido, non è adatto a loro; mentre il modello open source Qwen dalla Cina è eccellente, praticamente applicabile al loro lavoro, migliore e più economico di OpenAI.
Nel campo dell'open source, è inesatto affermare che il modello open source nazionale sia ancora in fase di recupero; è già diventato la scelta open source accettata a livello globale.
MiniMax M2, un agente intelligente open source che può essere implementato in applicazioni reali.
Se vogliamo utilizzare esempi specifici per illustrare i vantaggi del modello open source nazionale, le esperienze di test nel mondo reale di diversi strumenti open source che abbiamo condiviso in passato forniscono già la risposta.
L'ultimo arrivato è Kimi K2 Thinking, che presenta una catena di pensiero ultra-lunga in grado di eseguire 300 chiamate di strumenti in una singola esecuzione; c'è anche Zhipu AutoGLM 2.0, un agente universale progettato per i telefoni cellulari; e la famiglia di modelli Alibaba Tongyi per Android nell'era dell'intelligenza artificiale.

▲Statistiche di analisi artificiale sui principali produttori nazionali di modelli di intelligenza artificiale e startup nel primo trimestre del 2025
Sebbene tutti questi modelli siano open source, ognuno di essi presenta caratteristiche tecniche peculiari, con l'obiettivo di rendere la mappa dei modelli open source nazionali più completa e ricca.
K2 Thinking si concentra su un modello di grandi dimensioni con migliaia di miliardi di parametri e ha il suo meccanismo KDA (Kimi Delta Attention); DeepSeek si concentra sull'attenzione ibrida, che riduce significativamente i costi; Minimax M2, in questo aggiornamento, ha cambiato il suo approccio e ha utilizzato l'attenzione completa, con solo 230 miliardi di parametri del modello.
Per verificare se l'M2 è valido, abbiamo effettuato un semplice test, attenendoci al principio di provarlo ogni volta che è possibile.
Il nostro primo compito è stato quello di fargli elaborare i dati da un foglio di calcolo Excel. Gli abbiamo inviato una tabella con le offerte di lavoro per il concorso nazionale per la funzione pubblica di quest'anno e gli abbiamo chiesto di progettare uno strumento generale per la selezione delle posizioni aperte nel settore pubblico, basandosi sul contenuto della tabella.
La tabella contiene una grande quantità di dati, pari a 10 MB, e include oltre 20.000 annunci di lavoro. Una caratteristica particolarmente interessante di MiniMax M2 è che chiede all'utente se sono necessarie modifiche all'attività prima dell'esecuzione.
Nel loro blog tecnico, hanno menzionato che M2 utilizza la tecnica del "pensiero interlacciato", applicata per la prima volta nel modello Claude Sonnet 4, ma la sua adozione è ancora molto limitata.
MiniMax offre un suggerimento che ricorda agli utenti di salvare i propri processi mentali utilizzando i tag "think" del modello. M2 si basa sul pensiero intervallato e il contesto è essenziale per la memoria; preservare queste informazioni consente un pensiero intervallato migliore.

▲FaX, direttore tecnico di MiniMax, ha spiegato come il pensiero interlacciato consenta ai modelli di svolgere meglio le attività degli agenti.
In parole povere, il pensiero intervallato consiste nel far progredire un compito tramite un modello più ampio che "fa le cose (utilizzando strumenti/chiamando interfacce), si ferma e pensa, poi fa le cose di nuovo e poi pensa di nuovo", anziché pensare a un mucchio di idee e poi eseguirle tutte in una volta.
Anche il Kimi K2 Thinking, recentemente aggiornato, impiega la tecnica del pensiero interlacciato . Questo approccio, basato sul pensiero e sull'elaborazione simultanea di idee, consente al modello di rivedere e modificare immediatamente i propri piani ogni volta che riceve l'output dello strumento. Questa tecnica è particolarmente adatta per le attività degli agenti con processi lunghi e risultati incerti.
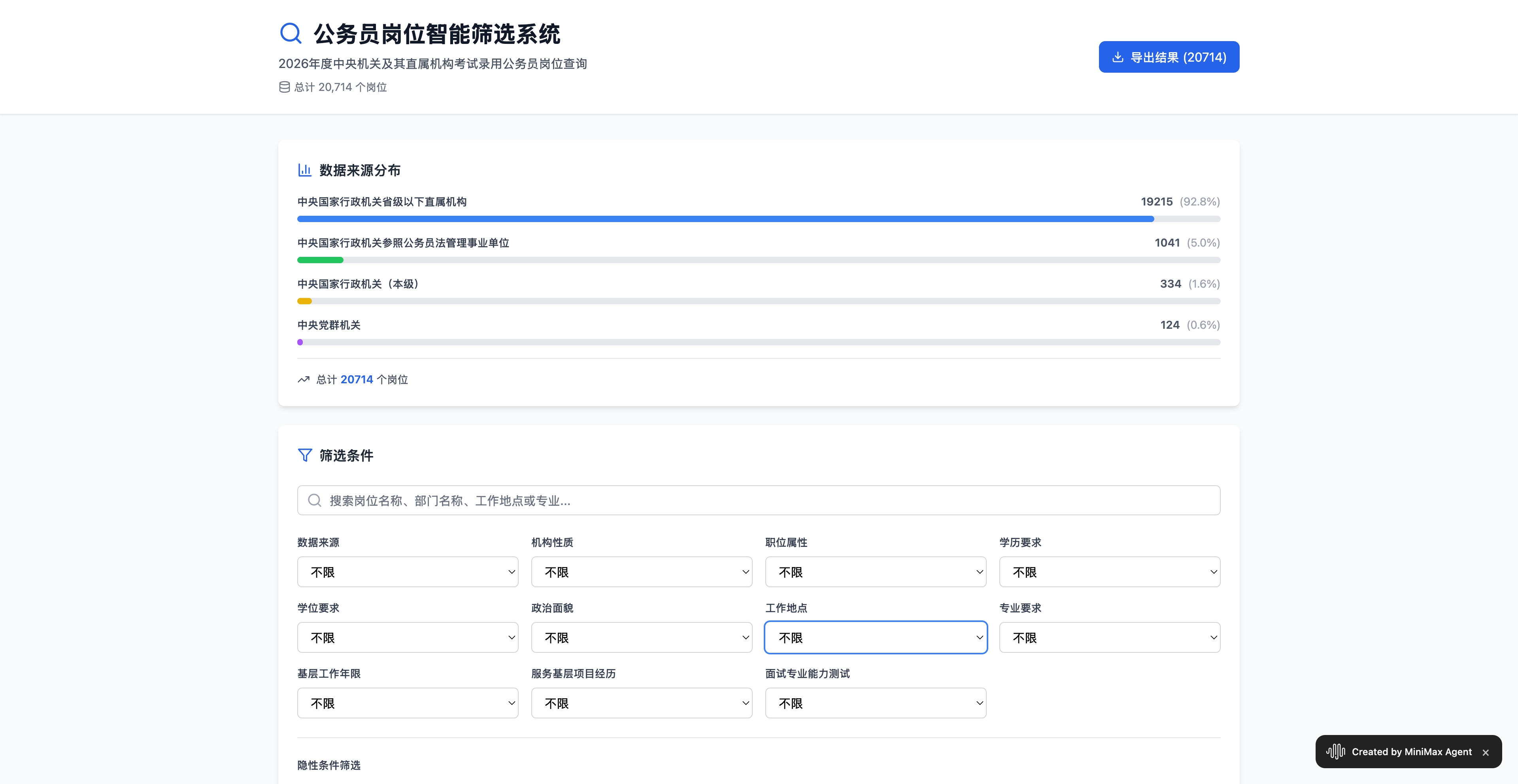
▲ Provalo qui: https://2rfxtimus5nr.space.minimaxi.com/; Anche se l'esame è terminato, puoi comunque vedere che la capacità del MiniMax M2 di elaborare i dati dei fogli di calcolo Excel non è da sottovalutare.
Il risultato finale è molto accurato, con 20.714 annunci di lavoro, e include statistiche su fattori come il fatto che il candidato sia neolaureato, abbia anni di esperienza in posizioni di base e abbia un luogo di residenza. Rispetto ad alcuni strumenti di selezione del lavoro a pagamento disponibili sul mercato, è molto più comodo generarne uno automaticamente tramite l'Agente.
Gli abbiamo anche chiesto di effettuare delle ricerche approfondite, fornendogli informazioni sull'M2 stesso e facendogli creare una splendida presentazione PowerPoint.
▲Link di anteprima: https://z4czsdfoakc7.space.minimaxi.com/
Oltre all'esperienza di programmazione immersiva che si ha costruendo un prodotto da zero, MiniMax fornisce anche tutorial dettagliati su come integrare strumenti da riga di comando come Claude Code o piattaforme di sviluppo come Cursor e VS Code.
▲Claude Codice utilizzando l'API del modello MiniMax M2
Il pensiero interlacciato rende i modelli più intelligenti, sapendo quando chiamare quale strumento. Ma il MiniMax M2 ha un'altra particolarità tecnica: utilizza un meccanismo di attenzione completa, che rappresenta un'eccezione alla norma .
Abbiamo già discusso in precedenza come DeepSeek riesca a raggiungere costi così bassi, uno dei motivi più importanti è l'utilizzo di meccanismi di attenzione sparsa e attenzione ibrida . L'attenzione sparsa consente al modello di concentrarsi selettivamente sulle informazioni importanti, ignorando quelle secondarie durante l'elaborazione dei token, proprio come fanno gli esseri umani.
Combinandolo con altre strategie, possiamo migliorare la velocità di inferenza del modello e ridurre i costi senza compromettere la qualità dell'output.

▲ Post del blog originale: https://huggingface.co/blog/MiniMax-AI/why-did-m2-end-up-as-a-full-attention-model
Il team di MiniMax ha anche scritto un post tecnico sul blog in cui spiega perché sono tornati al punto di partenza e hanno continuato a scegliere il meccanismo di attenzione completa, un metodo che aumenta la pressione di addestramento e inferenza.
Hanno affermato che la ragione principale è la "prestazione specifica". Gran parte di ciò che oggi viene definito attenzione sparsa o attenzione efficiente non mira a migliorare le prestazioni del modello, ma semplicemente a risparmiare risorse di elaborazione e ridurre i costi.
I modelli di attenzione completa offrono ancora prestazioni e affidabilità più elevate. Tuttavia, con l'aumento dei requisiti di lunghezza del contesto e il rallentamento del tasso di crescita del GPU computing, il potenziale dell'attenzione lineare e sparsa potrebbe gradualmente emergere.
Ciò che MiniMax M2 sta attualmente cercando di fare è raggiungere il più possibile un equilibrio tra qualità, velocità e prezzo con risorse di elaborazione limitate, e questa volta ci è effettivamente riuscito.

Pertanto, in una certa misura, molte persone ritengono che open source significhi regalare tecnologia ad altri gratuitamente; ma nella storia dello sviluppo tecnologico, open source significa consentire a diverse tecnologie di scontrarsi e a diversi ricercatori di collaborare, ottenendo così ulteriore innovazione tecnologica.
Quando Artificial Analysis, una piattaforma di analisi di modelli su larga scala, ha presentato le prestazioni complessive di MiniMax M2 sulla sua piattaforma, ha menzionato anche la tecnologia open source nazionale, ha affermato.
China AI Labs continua a mantenere una posizione di leadership nel campo dell'open source.
Il rilascio di MiniMax consolida la posizione di leadership della Cina nel campo dell'intelligenza artificiale open source, una posizione avviata da DeepSeek alla fine del 2024 e mantenuta dalle successive versioni di DeepSeek, Alibaba, Zhipu e Kimi, tra gli altri.
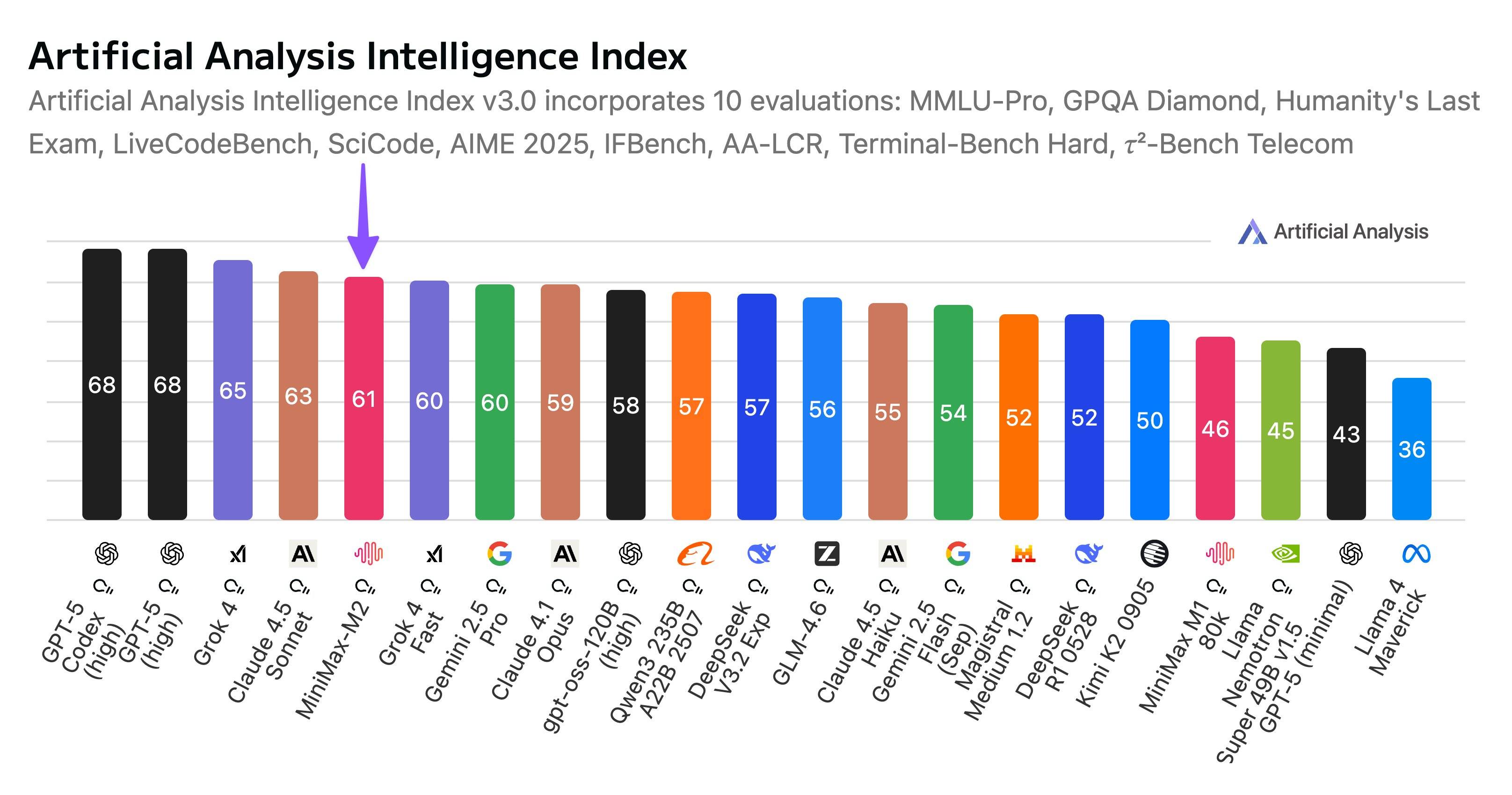
È vero. Abbiamo aspettato un anno per il DeepSeek R2, ma invece abbiamo visto il Kimi K2, che è diventato un successo all'estero, la serie Zhipu GLM e la serie Qwen, su cui fanno affidamento quasi tutti gli sviluppatori.
Tutti questi modelli open source sviluppati a livello nazionale, con i loro diversi approcci tecnici e le diverse direzioni applicative, solo se pienamente combinati possiedono veri vantaggi e punti di forza, impedendo al closed source di diventare l'unico rappresentante di un "buon modello".
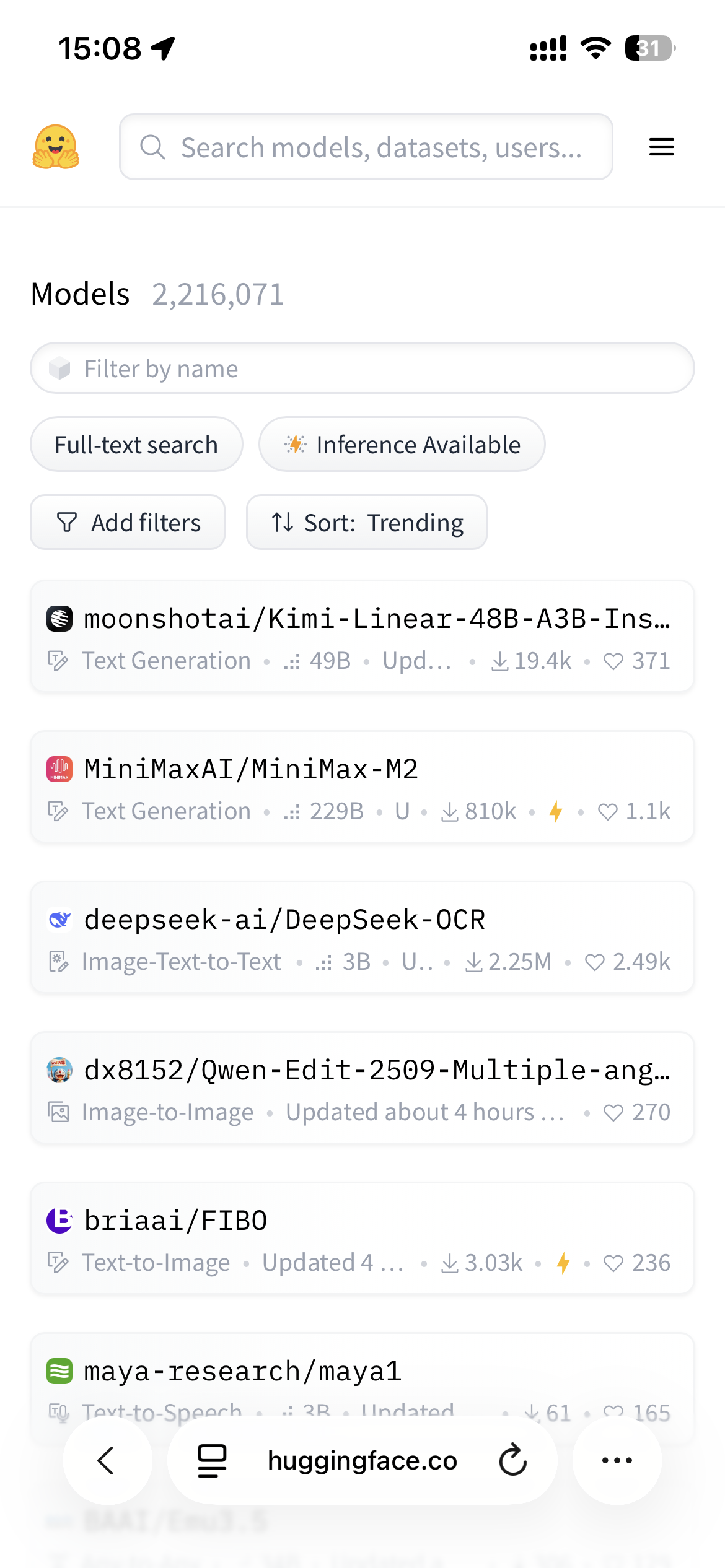
▲ Su Hugging Face, i quattro modelli più popolari sono tutti modelli open source sviluppati a livello nazionale; Fonte immagine: https://huggingface.co/models?sort=trending
Il codice closed-source non può sconfiggere il codice closed-source; solo il codice open-source può superare le barriere.
Qualche tempo fa, al 1024 Programmer's Day di Xiaohongshu, il fondatore di Hugging Face ha affermato che il divario tra open source e closed source si sta riducendo e che la Cina è relativamente avanzata in questo senso. Il responsabile tecnico di Xiaohongshu ha anche affermato che l'open source riduce i costi di utilizzo dell'intelligenza artificiale nella società e mobilita le forze di tutti per far progredire la tecnologia.
Indubbiamente, l'open source è una cosa positiva, ma nessuno si aspettava che ciò che avrebbe sconfitto il closed source sarebbe stato l'open source stesso.

L'avvento di DeepSeek non solo ha rivelato al mondo una logica di addestramento del modello completamente nuova, ottenendo risultati altrettanto sorprendenti a un costo inferiore, ma, cosa ancora più importante, ha fornito una direzione chiara per l'intera modalità operativa dell'intelligenza artificiale domestica.
Ha fatto capire a tutti che, in un contesto in cui all'epoca gli Stati Uniti monopolizzavano il dibattito globale sull'intelligenza artificiale, l'open source era l'unico modo per rendersi visibili.
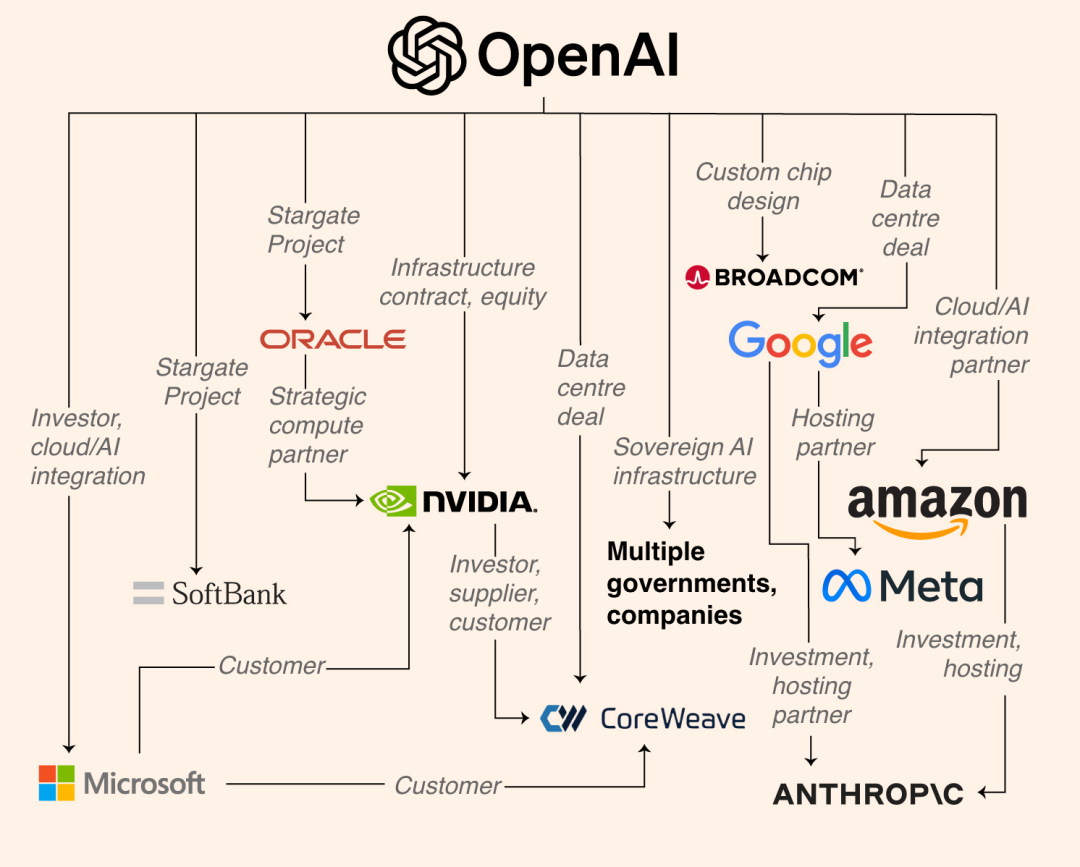
▲L'impero commerciale di OpenAI, con una potenza di calcolo da mille miliardi di dollari, che include Google, Meta, Anthropic, ecc.
Naturalmente, ci sono molte altre ragioni specifiche dietro la scelta dell'open source. OpenAI, Anthropic e Gemini stanno sviluppando i propri sistemi a porte chiuse. Possono addestrare modelli più grandi con schede grafiche illimitate e raccogliere centinaia di miliardi di dollari di finanziamenti.
Tuttavia, il dilemma che si trovano ad affrontare i modelli sviluppati a livello nazionale è la carenza di potenza di calcolo e la limitazione dei chip… Se i modelli non vengono condivisi, nessuno può riutilizzare la potenza di calcolo. Senza un modello di base utilizzabile, significa che tutto deve ricominciare da zero. Baidu inizialmente ha scelto di mantenere il modello closed-source per il bene del suo modello di business; a giugno di quest'anno, ha anche annunciato l'apertura ufficiale del codice sorgente della serie Wenxin Big Model 4.5.
D'altro canto, ci sono troppi produttori di modelli nazionali e la concorrenza è troppo agguerrita. Se sceglie di non aprire il codice sorgente, lo faranno altri; se sceglie di chiudere il codice sorgente, gli utenti potrebbero scegliere altri modelli.
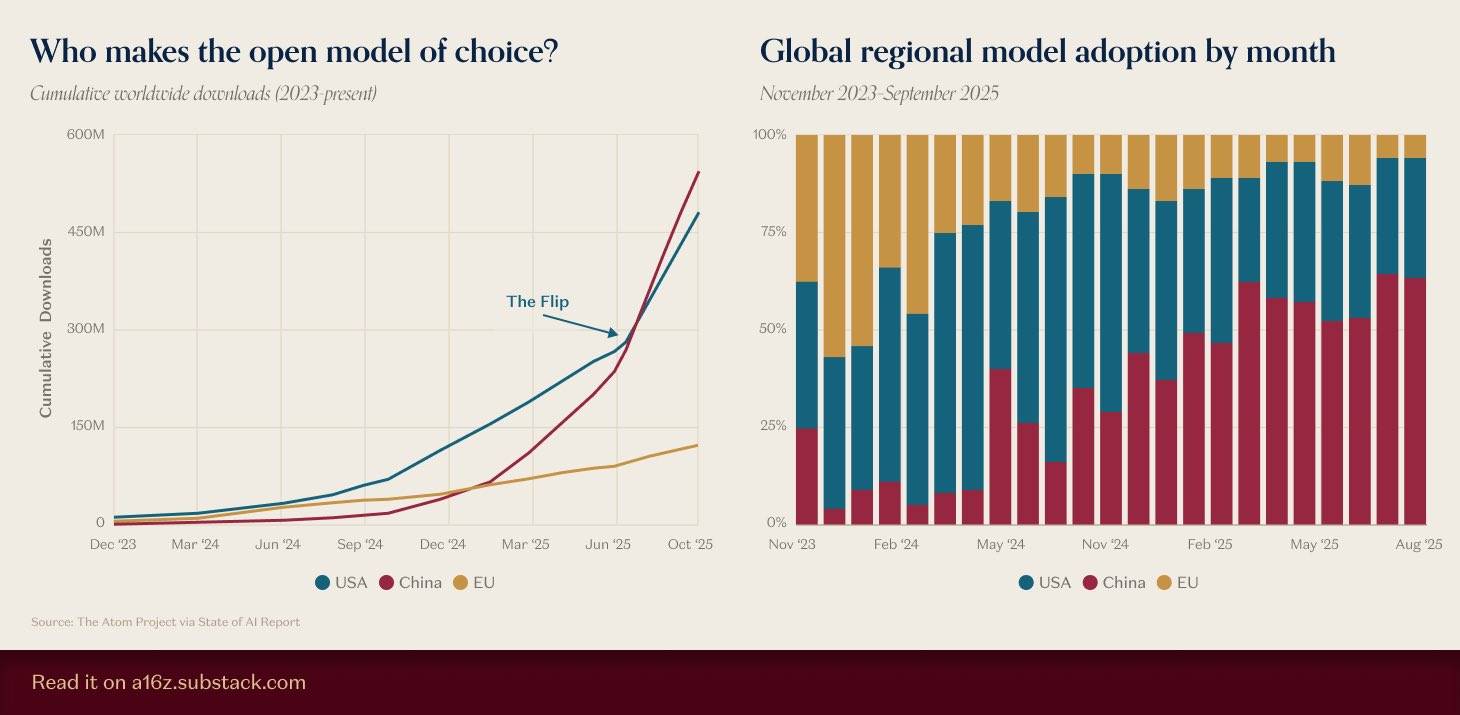
▲Fonte dell'immagine: https://a16z.substack.com/p/charts-of-the-week-open-model-of
Qualche tempo fa, a16z ha raccolto dati sui modelli open source e i risultati hanno mostrato che i download cumulativi dei modelli open source nazionali non solo hanno superato quelli dei modelli americani, ma il vantaggio continua anche ad aumentare.
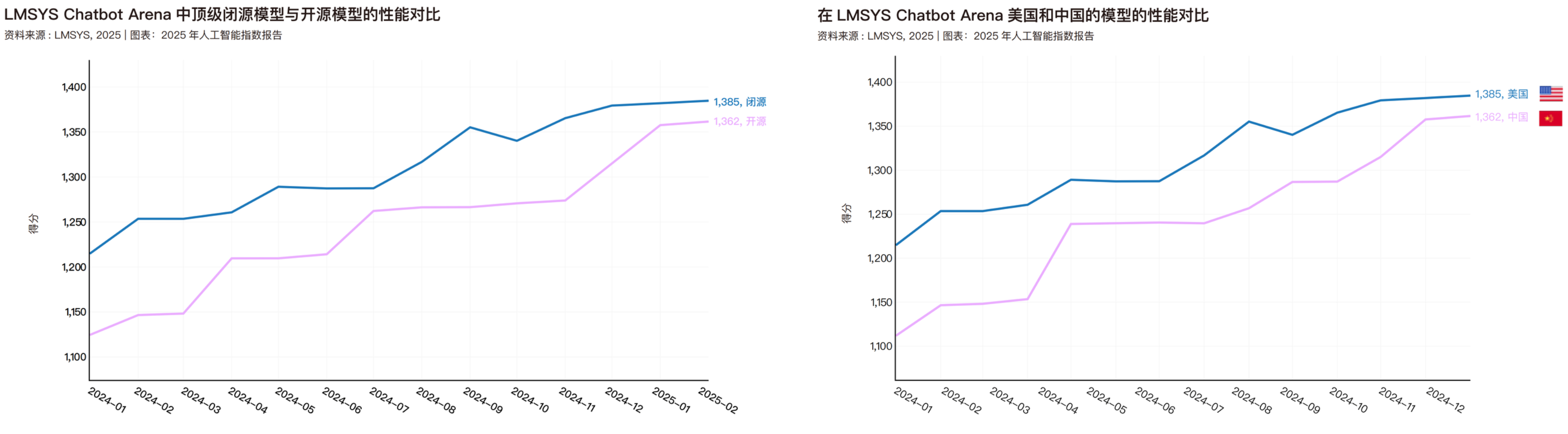
Ad aprile di quest'anno, la Stanford University ha pubblicato anche un rapporto sull'Indice di Intelligenza Artificiale 2025, che ha confrontato le prestazioni dei modelli open source e closed source, nonché le prestazioni dei modelli cinesi e statunitensi. I dati contenuti in questo rapporto si riferiscono solo a febbraio di quest'anno; entro l'anno prossimo, i modelli open source nazionali avranno probabilmente superato sia i modelli closed source che quelli americani.
Se analizziamo i vantaggi dell'open source nazionale al minimo possibile, scopriremo che il nostro attuale vantaggio è dovuto a un sistema open source completo e massiccio. Ogni anello di questo sistema contribuisce a rafforzare sempre di più le potenzialità dell'open source nazionale.
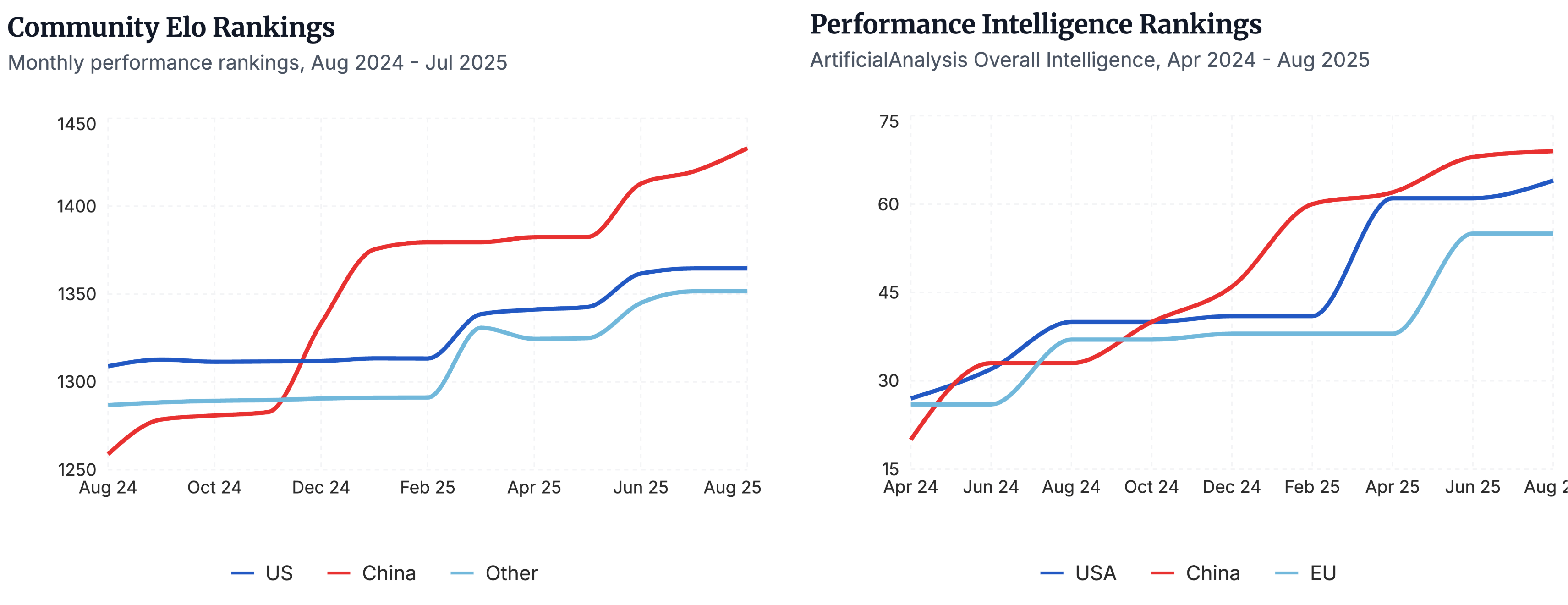
▲Che si tratti della valutazione da parte della comunità dei modelli open source nazionali, ad esempio la classifica Elo, o del confronto delle prestazioni per regione nel test di benchmark Artificial Analysis, i modelli open source nazionali occupano una posizione di leadership. | Fonte immagine: https://www.atomproject.ai/
DeepSeek ha aperto la prima crepa con la sua struttura dei costi e l'inferenza efficiente; Qwen ha creato una lacuna con la sua scala di ecosistema; MiniMax, Zhipu e Kimi, d'altro canto, hanno utilizzato approcci tecnici diversi per ampliare ulteriormente questa lacuna.
Quando piccoli team in tutto il mondo utilizzano Qwen per il fine-tuning, DeepSeek per le basi di inferenza e MiniMax per la verifica degli agenti, le soluzioni open source nazionali sono passate dall'essere scelte a diventare la soluzione predefinita. Di conseguenza, il centro dell'ecosistema open source globale ha iniziato a spostarsi verso la Cina.
Il mese scorso, Jensen Huang ha dichiarato in un'intervista a un summit sull'intelligenza artificiale che "la Cina vincerà la corsa all'intelligenza artificiale". Tuttavia, ha subito ritrattato la sua affermazione tramite l'account ufficiale di Nvidia, X, chiarendo che la Cina è in realtà "solo a pochi nanosecondi dagli Stati Uniti nella corsa all'intelligenza artificiale".

Non è la prima volta che Huang menziona la posizione della Cina nella corsa all'intelligenza artificiale. Ha dichiarato in diverse occasioni pubbliche che i modelli open source sono estremamente importanti, sia per gli sviluppatori, sia per le startup, sia per la cosiddetta corsa all'intelligenza artificiale.
Alla conferenza NVIDIA GTC tenutasi nell'ottobre di quest'anno, Jensen Huang ha ribadito nel suo discorso che nel mercato globale dei modelli open source, Tongyi Qianwen dalla Cina è al primo posto e detiene la maggior parte della quota di mercato.
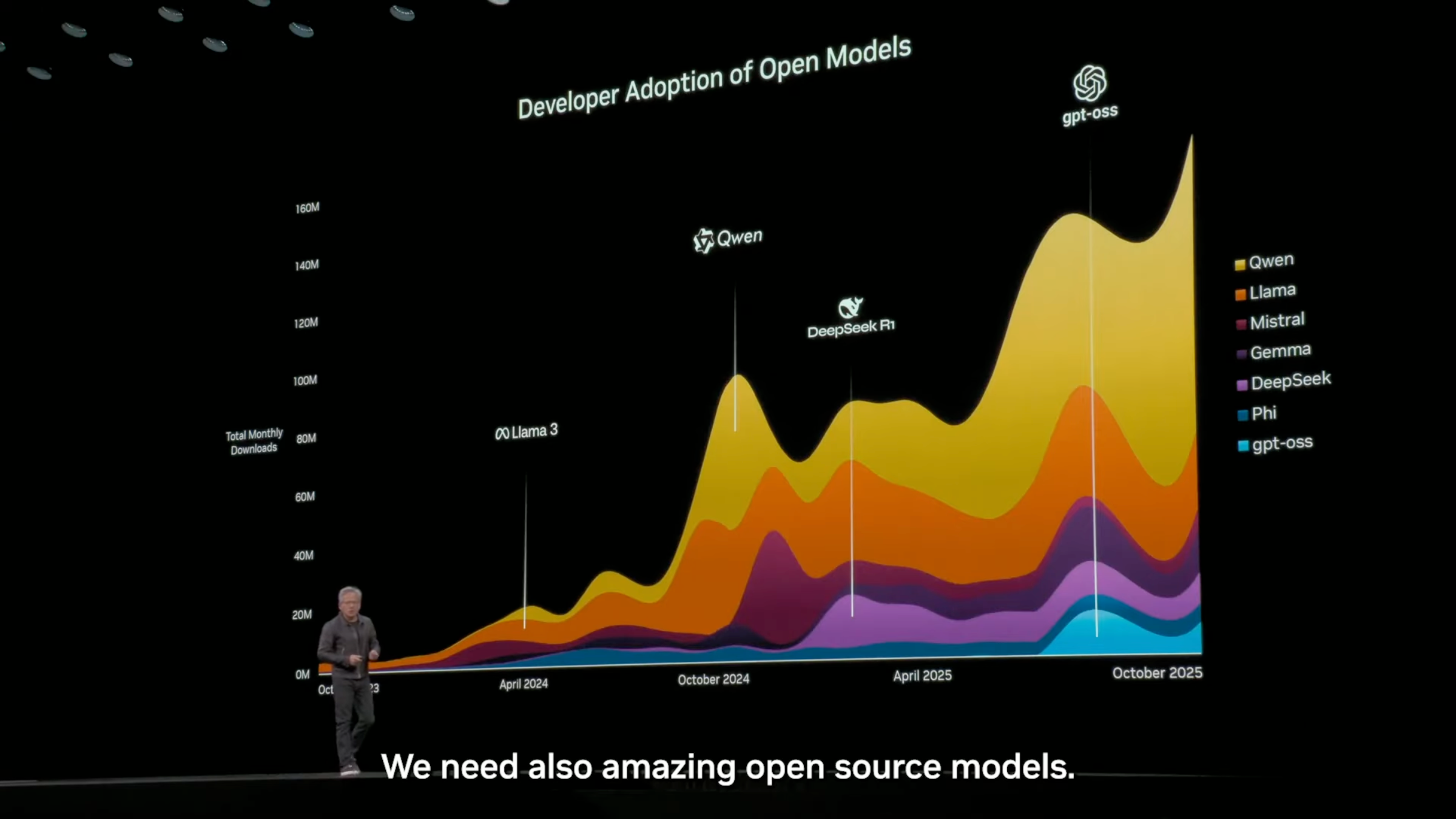
▲ Quasi il 60% sono Qwen
Ad aprile di quest'anno, durante una conferenza sulla tecnologia a Washington, ha affermato: "Senza dubbio, Huawei è una delle aziende tecnologiche più potenti al mondo… La Cina non è indietro nel campo dell'intelligenza artificiale. Siamo molto, molto vicini… Il 50% dei ricercatori di intelligenza artificiale del mondo sono cinesi. Dovremo competere".
Tuttavia, nella competizione per l'open source, guardate il leader statunitense dell'open source, Llama di Meta. Lo scorso aprile è stato rilasciato Llama 3, seguito da Llama 3.1 a luglio, Llama 3.2 a settembre e infine dal sorprendente Llama 4 ad aprile di quest'anno. Esiste persino una versione più avanzata, Behemoth, che non è ancora stata rilasciata.

▲The Llama 4, uscito ad aprile, menzionava tre versioni: Behemoth, Maverick e Scout. Sembra che Behemoth sia stato abbandonato.
Dopo di che, le uniche notizie su Meta riguardavano Zuckerberg che offriva stipendi enormi per rubare talenti, e poi, di recente, licenziava 600 persone. Persino il vincitore del premio Turing Yann LeCun si è dimesso per avviare un'attività in proprio.
Zuckerberg probabilmente non avrebbe mai immaginato che la sua scelta di aprire il codice sorgente nella Silicon Valley, che lo ha reso una figura unica, sarebbe stata superata da DeepSeek, la cui popolarità è esplosa a gennaio. Di conseguenza, Meta si trova ora di fronte a un dilemma: l'open source non è un'opzione e il closed source non è un'alternativa praticabile.
È difficile non essere d'accordo sul fatto che Llama debba metà del suo successo alla tecnologia open source nazionale.
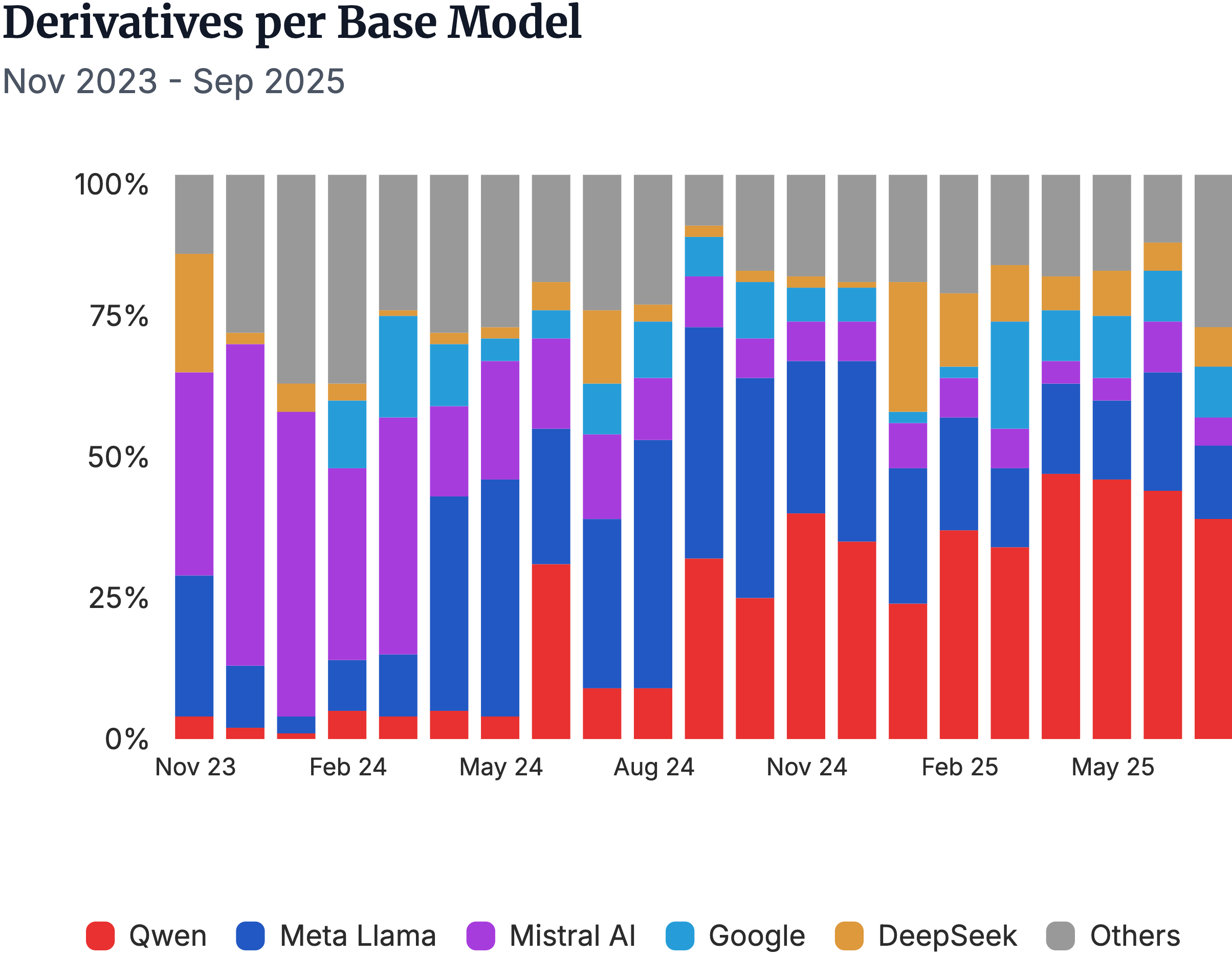
▲I modelli derivati meta-correlati e il vantaggio iniziale di Mistral AI sono stati completamente superati dal modello Qwen di Alibaba.
Qualche giorno fa, navigando sui social media, ho letto un commento che diceva: "L'open source è come trasformare il tuo avversario in tuo figlio; nessun figlio batterebbe suo padre". Le parole possono essere rozze, ma la verità è sensata. Nel ciclo open source dell'intelligenza artificiale, il modello open source rappresentativo della Cina è chiaramente diventato il fondamento dell'ecosistema dell'intelligenza artificiale.
Questa ondata di modelli di intelligenza artificiale, guidata da tecnologie open source sviluppate a livello nazionale, sta cambiando la questione su chi può definire il futuro dell'intelligenza artificiale. Permetterà a ciascuno di noi di utilizzare l'intelligenza artificiale più avanzata e intuitiva al mondo a costi inferiori e a una velocità maggiore.
I dettagli dell'ultima immagine sono i seguenti.
▲Dall'alto verso il basso:
Modelli all'avanguardia: DeepSeek, Qwen, Moonshot AI (Kimi)
Principali concorrenti: Z.Ai, MiniMax
Aziende da tenere d'occhio: StepFun, InclusionAI/Ant Financial, Meituan, Tencent, IBM, Nvidia, Google, Mistral
Aree di competenza: OpenAI, Ai2, Moondream, Arcee, RedNote, HuggingFace, LiquidAI, Microsoft, Xiaomi, Università Mohammed bin Zayed per l'Intelligenza Artificiale. Aziende emergenti: ByteDance Seed, Apertus, OpenBMB, Motif, Baidu, Marin Community, InternLM, OpenGVLab, ServiceNow, Skywork.
Menzioni d'onore: TNG Group, Meta, Cohere, Beijing Institute of Artificial Intelligence, Multimodal Art Projection, Huawei
#Benvenuti a seguire l'account WeChat ufficiale di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
