
La battaglia commerciale della Silicon Valley si sta trasformando in una gara di cucina? Zuckerberg una volta cucinò personalmente la zuppa per rubare talenti, e l’affermazione di OpenAI di non essere preoccupata è tutta una finzione.
Quando la beccaccia e la vongola si scontrano, il pescatore ne trae vantaggio. A volte spero addirittura che noi utenti siamo quel tipo di pescatori: più agguerrita è la concorrenza tra i produttori di modelli, prima avremo l'opportunità di utilizzare modelli migliori.
Il 22 dicembre 2022, tre settimane dopo il rilascio di ChatGPT, Google è diventato il primo colosso della tecnologia a emettere un "allarme rosso" in risposta alla minaccia rappresentata da OpenAI.
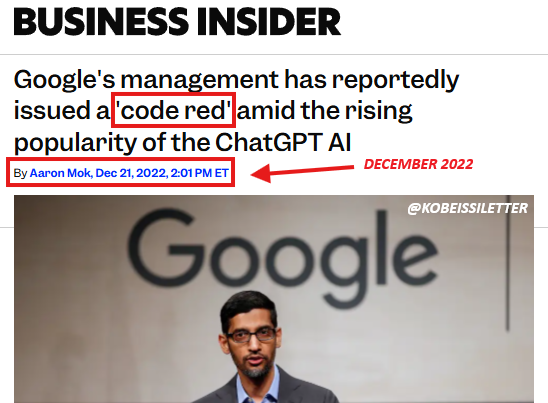
Ieri, due settimane dopo il lancio di Gemini 3, OpenAI ha emesso il suo primo "allarme rosso" a causa del significativo aumento del numero di modelli Gemini 3.
Quando ho letto la notizia per la prima volta, ho pensato che OpenAI stesse esagerando. Ho subito letto commenti come "l'orgoglio viene prima della caduta" e "vittoria e sconfitta sono comuni in guerra". Ma poi ho pensato che il cosiddetto "allarme rosso" potesse essere solo per gli investitori. Dopotutto, se OpenAI non riuscisse davvero a diventare il numero uno, il tempo necessario per diventare redditizia nel 2030 non avrebbe fatto che allungarsi ulteriormente.
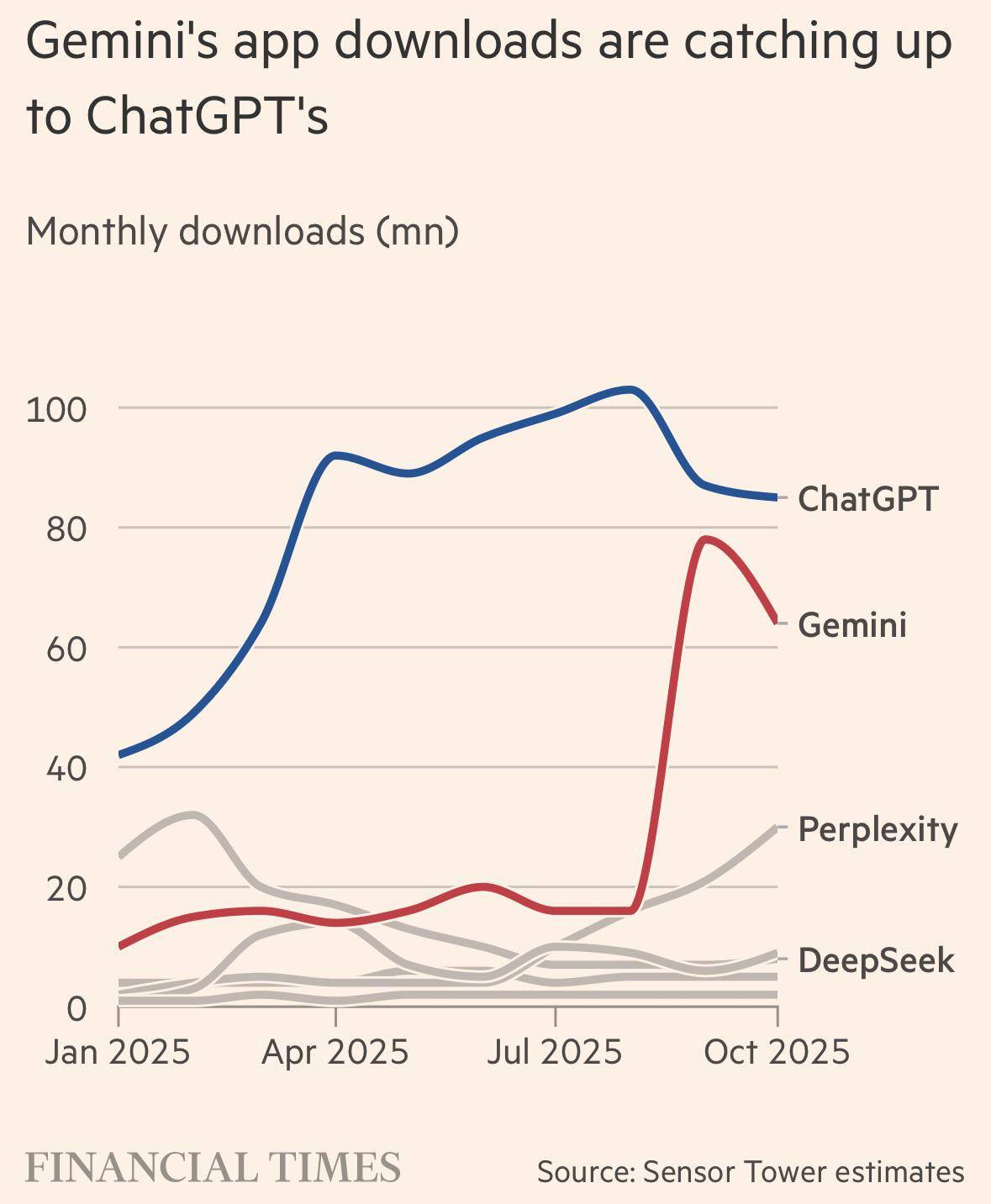
▲ I download dell'app Gemini stanno quasi raggiungendo ChatGPT.
Secondo le ultime notizie, la prossima settimana OpenAI lancerà un nuovo modello di inferenza, che internamente ha dimostrato di superare Gemini 3. Inoltre, hanno in programma di contrattaccare con un modello dal nome in codice "Garlic".
Tuttavia, lo scenario più realistico è che OpenAI rilascerà inevitabilmente un modello migliore di Gemini 3, mentre Google ha anche Gemini 4 e Gemini 5.
In effetti, ripensando alle notizie provenienti dalla Silicon Valley nell'ultimo anno, si può dire che si è trattato di uno spettacolo drammatico e tumultuoso. All'inizio dell'anno, l'improvvisa comparsa di DeepSeek R1 ci ha messo sotto pressione; a metà anno, Zuckerberg ha lanciato una frenetica "cattura di talenti", con stipendi alle stelle che hanno ridefinito la percezione comune dei talenti dell'intelligenza artificiale; e alla fine dell'anno, siamo stati nuovamente trascinati nella semplice arena della competizione tra modelli.

In una recente intervista podcast, Mark Chen, responsabile della ricerca presso OpenAI, ha descritto la battaglia nella Silicon Valley come un'evoluzione a livelli surreali. Ha affermato che, per impossessarsi dei cervelli di OpenAI, Zuckerberg ha persino iniziato a preparare una zuppa – letteralmente una zuppa bevibile – e a consegnarla personalmente a domicilio ai ricercatori.
Oltre a questi pettegolezzi, ha parlato anche delle opinioni di OpenAI su Gemini 3, se la scalabilità sia obsoleta, l'impatto di DeepSeek R1 su di essa, l'allocazione interna della potenza di calcolo dell'azienda e la tempistica per raggiungere l'AGI.
Il background di Mark Chen è piuttosto interessante: ha alle spalle una formazione in competizioni matematiche, si è laureato al MIT, ha lavorato nel trading ad alta frequenza (HFT) a Wall Street ed è entrato a far parte di OpenAI nel 2018 per fare ricerca con Ilya. A differenza di Altman, che è più un uomo d'affari, queste esperienze gli hanno conferito un tratto distintivo: un'estrema avversione al fallimento e una forte fede nella matematica.
Ha ammesso di non avere attualmente una vita sociale e di aver lavorato fino all'una o alle due di notte tutti i giorni nelle ultime due settimane.
Abbiamo compilato questa intervista di un'ora e mezza e ne abbiamo riassunto i punti salienti di seguito, che potrebbero fornire una migliore comprensione delle varie "battaglie" nella Silicon Valley nell'ultimo anno e degli sforzi che OpenAI compirà per mantenere la sua posizione di leader nell'era dell'intelligenza artificiale.
Per quanto riguarda Gemini 3, non siamo affatto preoccupati.
OpenAI ha davvero paura di Google? La valutazione di Mark è oggettiva ma acuta. Ha riconosciuto che Gemini 3 è un buon modello e che Google ha finalmente trovato la strada giusta. Tuttavia, ha sottolineato che, analizzando i dettagli, come i dati di SWE-bench ( che è anche l'unico benchmark a non essersi classificato al primo posto nell'immagine di Gemini 3 che domina la classifica ), Google non ha ancora risolto il problema fondamentale dell'efficienza dei dati.
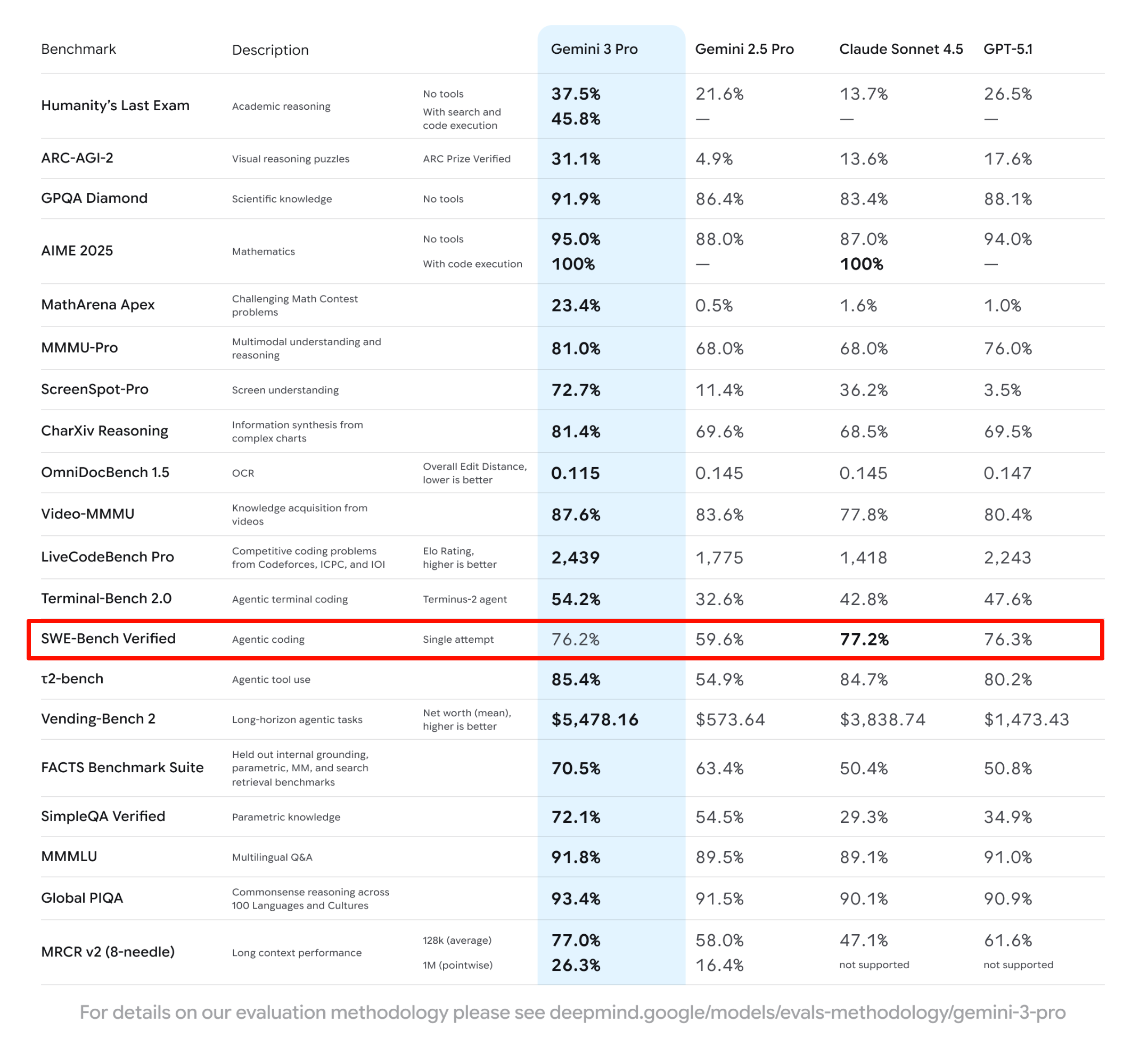
▲Le prestazioni del Gemini 3.0 Pro su SWE-Bench sono state peggiori dello 0,1% rispetto a quelle del GPT-5.1.
Lui stesso ha affermato con grande sicurezza che OpenAI ha già un modello mirato per affrontare questo problema e che sono fiduciosi di poter fare ancora meglio in termini di efficienza dei dati.
Mark ha persino affermato che il promemoria inviato da Altman qualche giorno fa, in cui si affermava che tutti avrebbero dovuto sentirsi sotto pressione, aveva lo scopo di spaventare tutti, ma in realtà mirava più a infondere un senso di urgenza. Ha affermato che questa è una tattica comune utilizzata dal management, e che lo scopo del promemoria è motivare il team, non creargli panico.
Penso che uno dei compiti di Sam sia infondere un senso di urgenza e velocità. Questa è una sua responsabilità, ed è anche una mia responsabilità.
Come manager, parte del nostro lavoro è infondere costantemente un senso di urgenza nell'organizzazione.

▲Come riportato in precedenza da The Information, Altman inviò un promemoria interno al lancio di Gemini 3, menzionando che avrebbe creato difficoltà a OpenAI.
Il loro problema più grande al momento è ancora l'allocazione della potenza di calcolo . Come direttore della ricerca presso OpenAI, uno dei suoi compiti è decidere come allocare la potenza di calcolo ai diversi progetti all'interno dell'azienda.
Insieme a Jakub Pachocki (Chief Scientist di OpenAI), è responsabile della definizione della direzione di ricerca di OpenAI e della determinazione della potenza di calcolo di cui ogni progetto può disporre. Ogni uno o due mesi, i due ricercatori effettuano una revisione di questo aspetto.
Hanno inserito tutti i progetti in corso di OpenAI in un'enorme tabella, circa 300 in totale; poi hanno fatto del loro meglio per comprendere ogni progetto, li hanno classificati in base alle priorità e infine hanno assegnato le GPU in base a questa tabella di priorità.

▲ La collaborazione tra NVIDIA e OpenAI su un milione di GPU
Ha anche affermato che ciò che consuma realmente la maggior parte delle GPU non è l'addestramento del modello rilasciato più importante, bensì gli esperimenti interni che esplorano la prossima generazione di paradigmi di intelligenza artificiale.
Pertanto, ai suoi occhi, il rilascio di Gemini 3, il benchmarking di un certo modello open source e il nuovo record raggiunto da un certo modello di pensiero sono tutti irrilevanti . Al contrario, ciò che andrebbe maggiormente evitato è lasciarsi fuorviare da questa competizione.
Ha affermato che, con l'attuale sviluppo dei modelli, possiamo facilmente rimanere in testa alla classifica per settimane o mesi con un semplice "piccolo aggiornamento". Ma se investiamo tutte le nostre risorse in queste iterazioni a breve termine, nessuno cercherà la prossima generazione di paradigmi. E una volta che qualcuno la troverà, l'intero settore dovrà seguire quella nuova strada per il prossimo decennio.
Solo un breve sussurro: prevedo che il rilascio del modello OpenAI la prossima settimana sarà solo un aggiornamento non pianificato che ha aggiornato alcune classifiche. Non sei ancora preoccupato?

Parlando delle classifiche, ha affermato di avere una serie di problemi personali per verificare se il modello possiede davvero un'intuizione matematica di alto livello. Ha citato un problema matematico di 42 punti, affermando che gli attuali modelli linguistici, inclusi i modelli di pensiero O1, possono avvicinarsi alla soluzione ottimale, ma non l'hanno mai risolta completamente.
Vuoi creare un generatore di numeri casuali modulo 42. Hai alcuni numeri primi modulo 42. L'obiettivo è generare questo generatore modulo 42 con il minor numero possibile di chiamate.
Oltre a parlare di Gemini 3, il conduttore gli ha anche chiesto cosa pensasse di DeepSeek.
Come Gemini 3, Mark ha ammesso che il modello open source di DeepSeek li aveva messi sotto pressione e li aveva persino fatti dubitare di essere sulla strada sbagliata.
La conclusione è che bisogna attenersi al proprio percorso, non lasciare che le azioni dei concorrenti interferiscano con il proprio ritmo e concentrarsi sulla propria tabella di marcia. OpenAI non diventerà un'azienda imitatrice; ciò che vuole fare è definire il prossimo paradigma.
Ilya ha un grande potenziale di scalabilità e OpenAI necessita di un pre-addestramento su larga scala.
Di recente, il dibattito sul fallimento della scalabilità è stato molto acceso. Ilya ha dichiarato per la prima volta in un'intervista podcast che l'era della scalabilità è finita, per poi chiarire sui social media che continuerà a portare miglioramenti e non è stagnante.
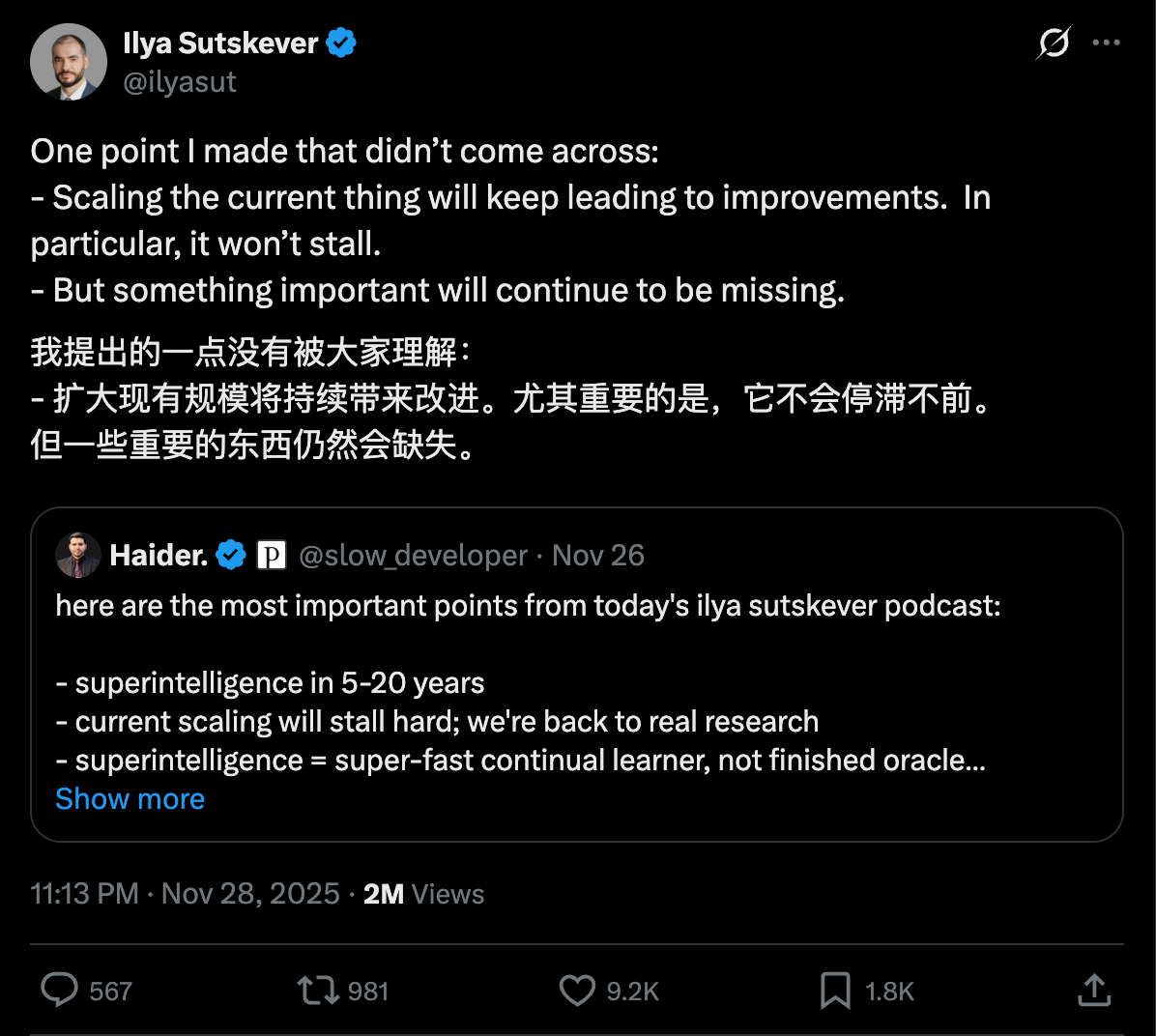
La cosiddetta Legge di Scaling segue la narrazione classica: con l'imponente infrastruttura informatica sviluppata negli ultimi anni, ogni decuplicazione della potenza di calcolo avrebbe dovuto comportare un significativo balzo in avanti. Tuttavia, da GPT-4 a GPT-5, il "salto di qualità" atteso non si è concretizzato, dando origine a discussioni sul fatto che "la Legge di Scaling abbia fallito". La recente intervista di Ilya ha ulteriormente amplificato questo punto di vista.
Mark Chen ha fermamente confutato questa opinione, affermando: "Siamo completamente in disaccordo". Ha rivelato che OpenAI ha investito ingenti risorse nell'inferenza negli ultimi due anni, portando a un leggero peggioramento del pre-addestramento. I precedenti problemi con il pre-addestramento di GPT-5 erano in realtà dovuti alla loro attenzione all'inferenza , non all'abbandono della Legge di Scaling.
Il suo compito è allocare le risorse di calcolo e ha ribadito che la potenza di calcolo non sarà mai eccessiva. Se oggi ci fosse una potenza di calcolo tre volte superiore, potrebbe utilizzarla tutta immediatamente; se oggi ci fosse una potenza di calcolo dieci volte superiore, potrebbe sfruttarla appieno nel giro di poche settimane. Per lui, la domanda di potenza di calcolo è reale e non vede segni di rallentamento.
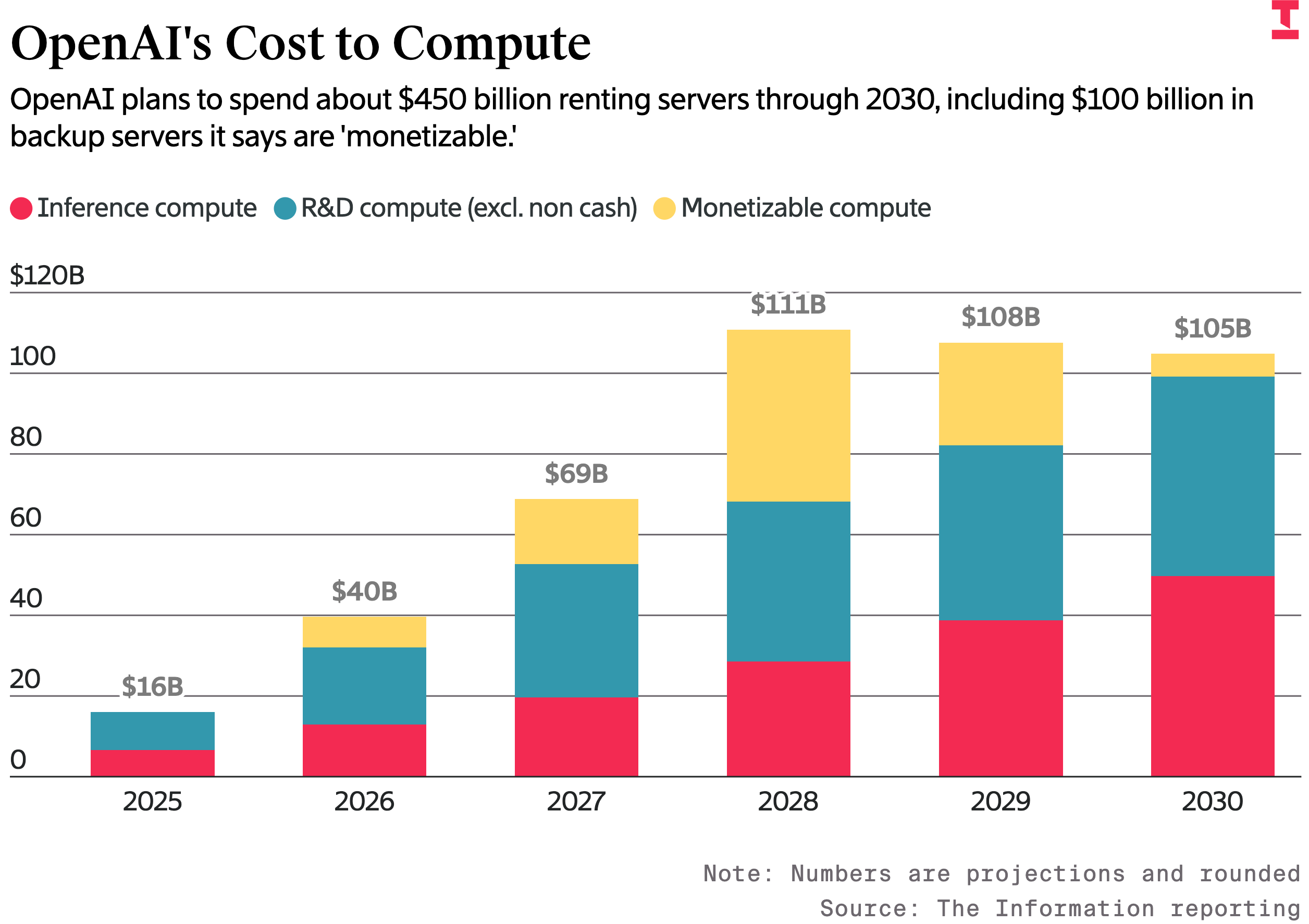
▲ Costi di elaborazione di OpenAI: prevede di spendere circa 450 miliardi di dollari in affitti di server entro il 2030. Il rosso rappresenta i costi di elaborazione inferenziale, il blu rappresenta la ricerca e sviluppo (escluse le operazioni di cassa) e il giallo rappresenta l'elaborazione redditizia.
Ha anche menzionato che negli ultimi sei mesi lui e lo scienziato capo di OpenAI, Jakub Pachocki, hanno spostato la loro attenzione sulla ridefinizione del predominio della pre-formazione .
Ha dichiarato esplicitamente che continueranno a sviluppare modelli in scala e che sono state conseguite numerose innovazioni algoritmiche, specificamente progettate per rendere la scalabilità più conveniente, ottenendo maggiori prestazioni con la stessa potenza di calcolo e mantenendo l'efficienza dei dati con una potenza di calcolo maggiore.
La zuppa sentita di Zuckerberg non poteva essere paragonata al messaggio motivazionale di OpenAI.
Infine, c'è il gossip menzionato nell'intervista. Meta non ha avuto altre notizie quest'anno, ma i media hanno enfatizzato la "massiccia fuga di cervelli di talenti OpenAI/talenti Apple/talenti Google verso Meta" per un intero trimestre. Mark Chen ha affrontato questo argomento direttamente nel podcast, e i dettagli sono stati quasi "oltraggiosi".
Ha detto che Zuckerberg stava davvero dando il massimo; per accaparrarsi i talenti, non solo scriveva email a mano, ma consegnava personalmente la zuppa di pollo. La guerra dei talenti alla fine si è trasformata in un meta-gioco a "chi cucina la zuppa migliore".
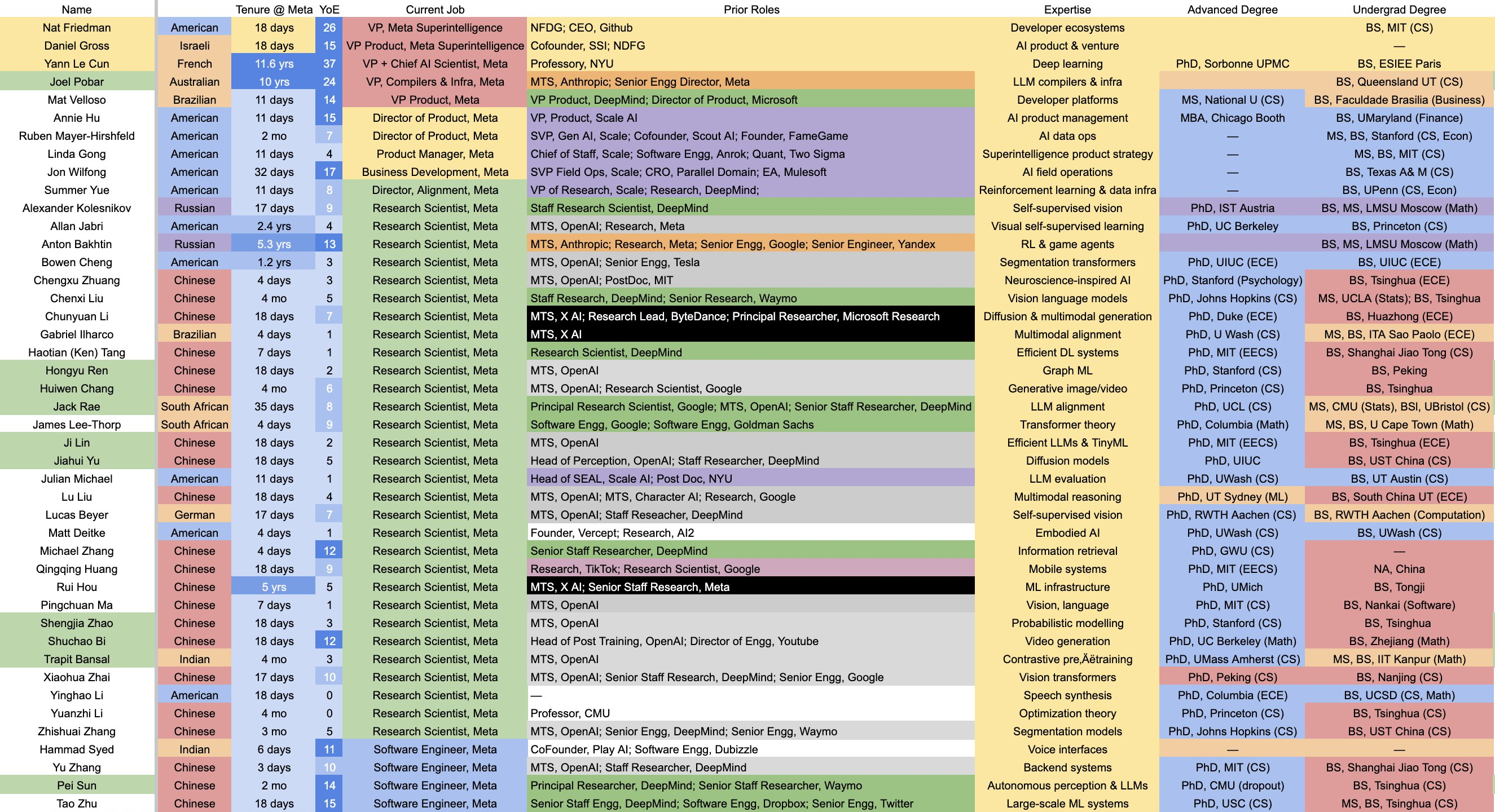
▲ Elenco dei Super Laboratori di Intelligenza di Meta, costruiti con enormi somme di denaro per rubare talenti
Tuttavia, Meta aveva cercato di rubare metà dei suoi diretti subordinati, ma tutti avevano scelto di restare. Perché non se ne erano andati? Non per soldi, visto che Meta ovviamente offriva di più, ma per le loro convinzioni .
Mark ha affermato che persino coloro che sono passati a Meta non hanno osato dire: "Meta creerà l'AGI prima di OpenAI". Chi è rimasto a OpenAI lo ha fatto perché credeva fermamente che fosse il luogo di nascita dell'AGI.
Ha anche detto di aver imparato dalle sue esperienze a Wall Street e giocando a poker che ciò che serve davvero è trattenere i talenti chiave, non ogni singolo individuo . Una volta capito che tipo di persone devi assolutamente trattenere, puoi concentrare tutte le tue risorse e la tua attenzione su quel gruppo.
Ha affermato che la sua emozione più forte era in realtà il desiderio di "proteggere l'istinto per la ricerca". Quando Barrett (vicepresidente della ricerca presso OpenAI) se ne andò, dormì addirittura nel suo ufficio per un mese solo per tenere il team di ricerca sulla buona strada.
▲ Barret e Mira (ex CTO di OpenAI) lavorano entrambi presso Thinking Machines.
Quindi, cos'è l'AGI, in cui OpenAI crede? Il conduttore gli ha chiesto: "Andrej Karpathy ha detto in un recente podcast che l'AGI è probabilmente ancora lontana 10 anni. Cosa ne pensi?"
Mark ha inizialmente commentato scherzosamente i vari "fantastici" testi di X, che alternano frasi come "l'IA è finita" e "l'IA è di nuovo praticabile". Crede che ognuno abbia una diversa comprensione dell'AGI e, anche all'interno di OpenAI, sia difficile avere una definizione unificata. Ma crede negli obiettivi che OpenAI si è prefissata per l'AGI.
- Entro un anno: cambiare la natura della ricerca. Attualmente, i ricercatori scrivono codice e conducono esperimenti autonomamente. Dopo un anno, il compito principale dei ricercatori sarà gestire gli stagisti di intelligenza artificiale. L'intelligenza artificiale dovrebbe essere in grado di fungere da assistente efficiente, gestendo la maggior parte dei compiti specifici.
- Entro 2 anni e mezzo: raggiungere l'automazione della ricerca end-to-end . Ciò significa che gli esseri umani sono responsabili solo della proposta di idee (progettazione di alto livello), mentre l'intelligenza artificiale è responsabile dell'implementazione del codice, del debug, dell'elaborazione dei dati e dell'analisi dei risultati, creando un ciclo chiuso.
Da Copilota a Scienziato, Mark sottolinea che l'obiettivo di OpenAI for Science non è vincere il premio Nobel in sé, ma creare una serie di strumenti che consentano agli scienziati attuali di accelerare il loro lavoro con un solo clic, anche se ciò richiede la ristrutturazione dell'intero sistema di valutazione scientifica, perché in futuro potrebbe essere difficile distinguere se una scoperta è stata fatta da un essere umano o dall'intelligenza artificiale.
Due anni e mezzo possono sembrare un lasso di tempo breve, ma per il settore dell'intelligenza artificiale, che ormai procede a ritmo settimanale, si tratta di una lunga maratona.
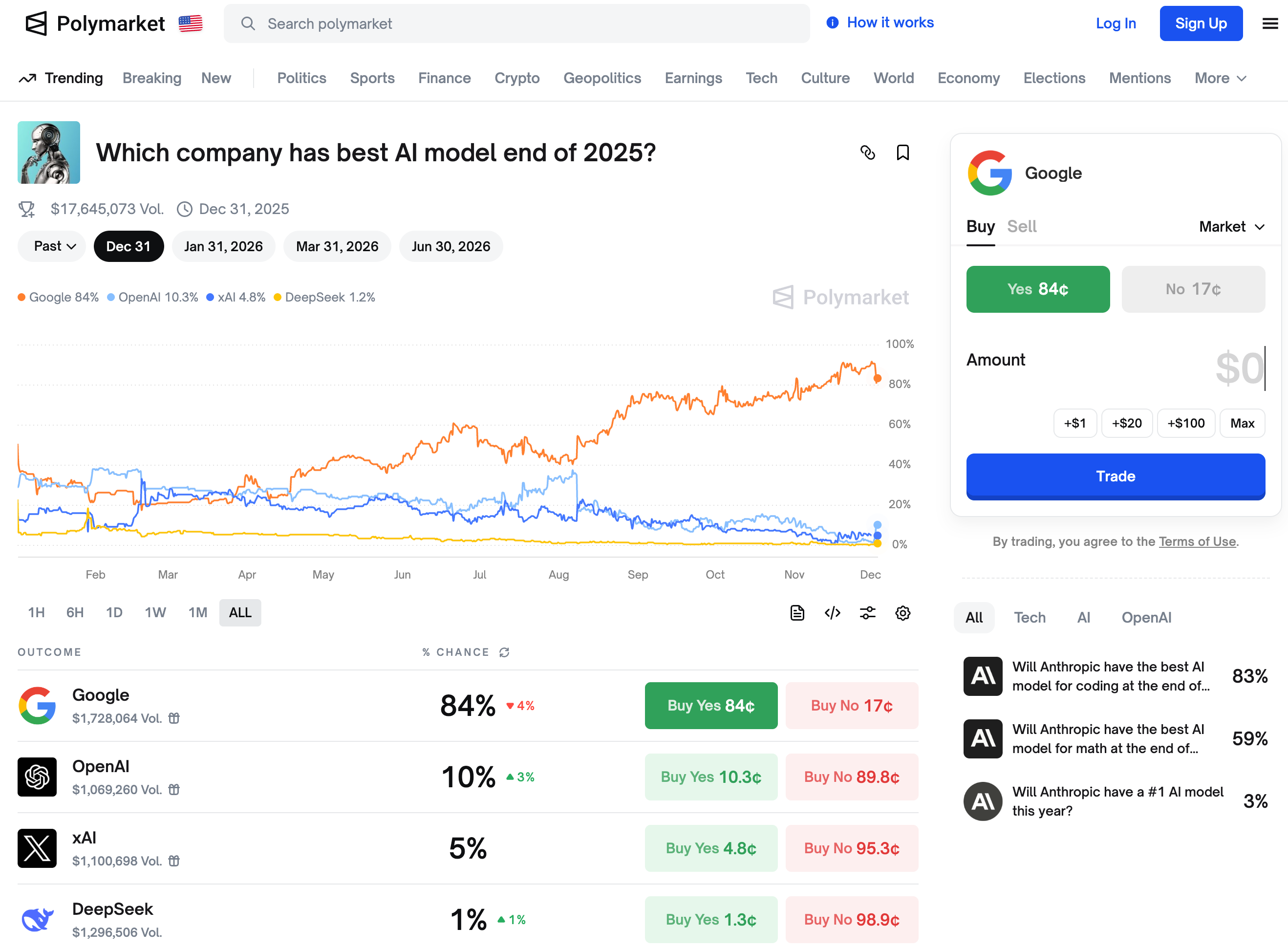
▲ Secondo le previsioni di mercato, Google è al primo posto come azienda che produrrà il miglior modello di intelligenza artificiale entro la fine del 2025.
Che si tratti delle promesse redditizie ma in definitiva vuote di Zuckerberg o della visione idealistica di OpenAI di definire il futuro, questo "dramma" della Silicon Valley è tutt'altro che finito. La compostezza di Mark Chen nel suo podcast potrebbe alleviare alcune ansie esterne, ma alla fine gli utenti voteranno con i piedi; i buoni modelli parleranno da soli.
#Benvenuti a seguire l'account WeChat ufficiale di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
