
Xiaomi ha improvvisamente lanciato un nuovo modello: paragonabile a DeepSeek-V3.2, che porta l’intelligenza artificiale al rapporto qualità-prezzo dei telefoni cellulari.

Il modello open source ha accolto un altro contendente di peso. Proprio ora, Xiaomi ha ufficialmente rilasciato e reso open source il suo nuovo modello, MiMo-V2-Flash.
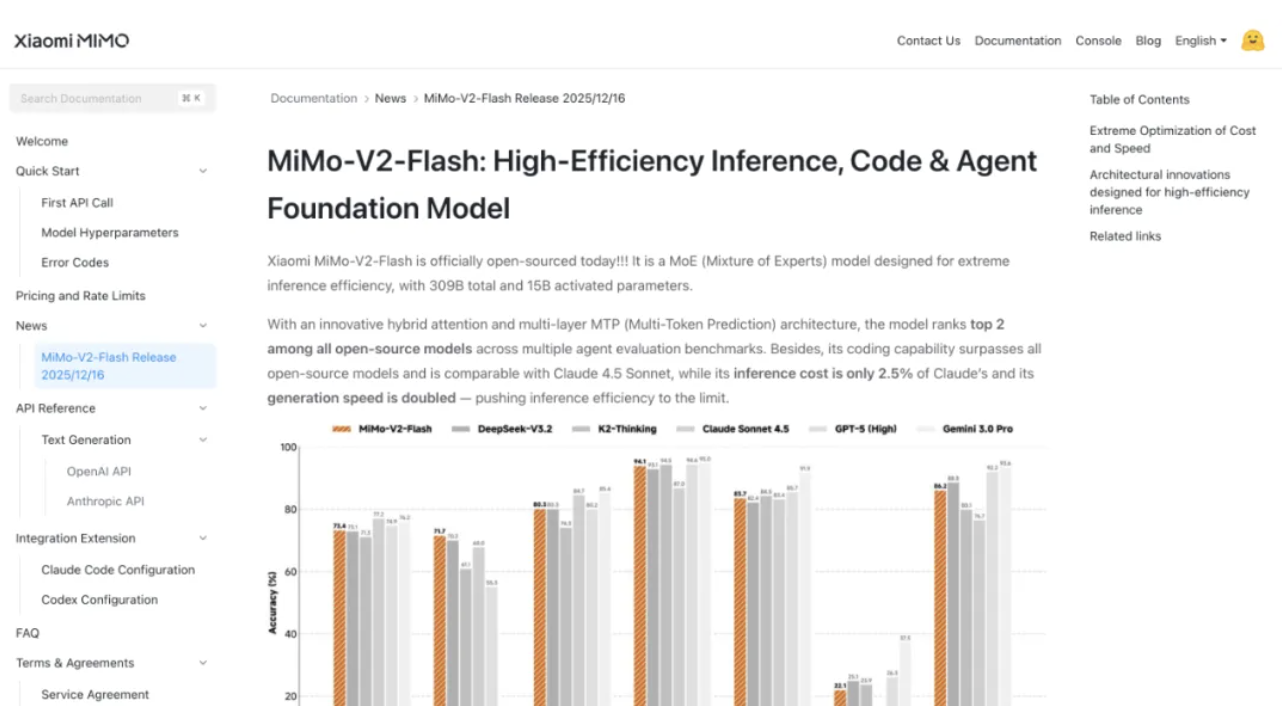
MiMo-V2-Flash ha un totale di 309 miliardi di parametri, di cui 15 miliardi attivi. Adotta un'architettura ibrida esperta (MoE) e le sue prestazioni possono competere con i principali modelli open source come DeepSeek-V3.2 e Kimi-K2.

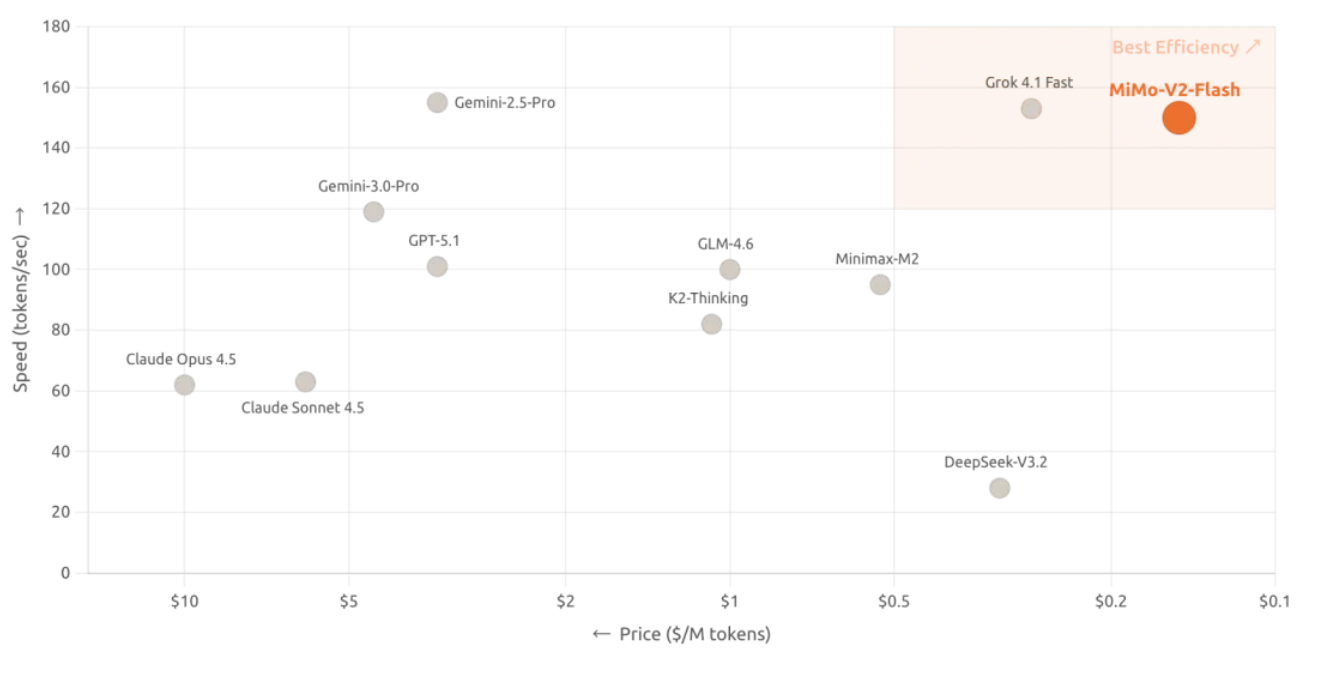
Inoltre, MiMo-V2-Flash adotta la licenza open source del MIT e il suo copyright di base è stato rilasciato anche su Hugging Face. Oltre all'open source, la vera caratteristica distintiva del nuovo modello risiede nella sua radicale innovazione nel design architettonico, che ha aumentato la velocità di inferenza a 150 token al secondo e ridotto il costo a 0,1 dollari per milione di token in input e 0,3 dollari per milione di token in output, rendendolo un eccezionale rapporto costo-prestazioni.
Secondo la pagina ufficiale, MiMo-V2-Flash supporta funzioni di pensiero profondo e di ricerca online, il che significa che non solo può scrivere codice e risolvere problemi matematici, ma anche ottenere le informazioni più recenti in tempo reale.
Ecco il link per provare AI Studio:
http://aistudio.xiaomimimo.com
SWE-Bench stabilisce un nuovo punto di riferimento per i modelli open source, raggiungendo la vetta delle classifiche open source.
Come di consueto, diamo prima un'occhiata ai punteggi benchmark di MiMo-V2-Flash.
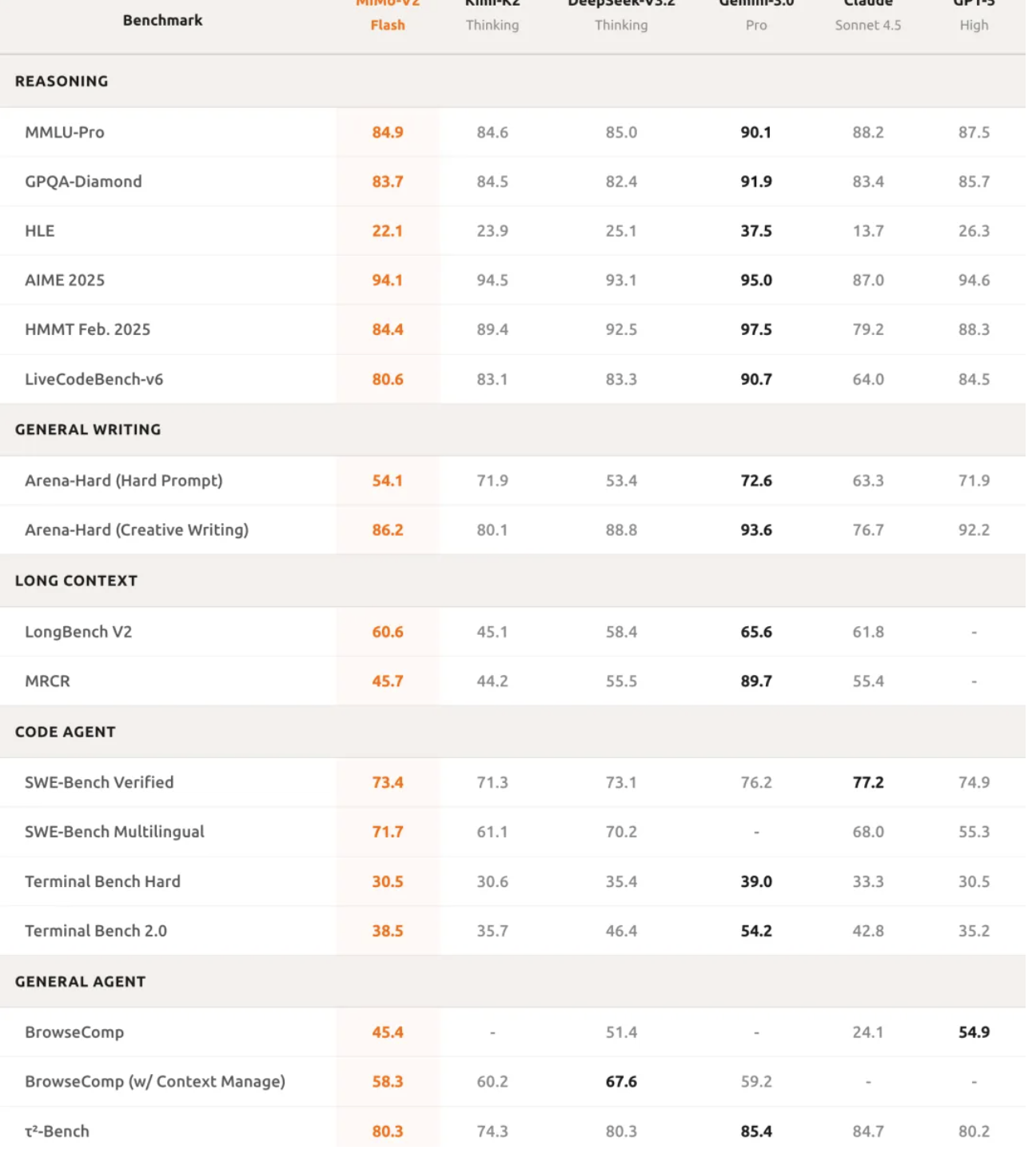
Nel ragionamento matematico, MiMo-V2-Flash si è classificato tra i primi due modelli open source sia nella competizione di matematica AIME 2025 che nel GPQA-Diamond Science Knowledge Test.
Le sue capacità di programmazione sono ancora più impressionanti, con un punteggio del 73,4% nel test SWE-bench Verified, superando tutti i modelli open source e avvicinandosi al GPT-5-High. In parole povere, questo test mette l'IA alla prova con bug software reali e un tasso di successo del 73,4% significa che è in grado di gestire la maggior parte dei problemi di programmazione pratici.
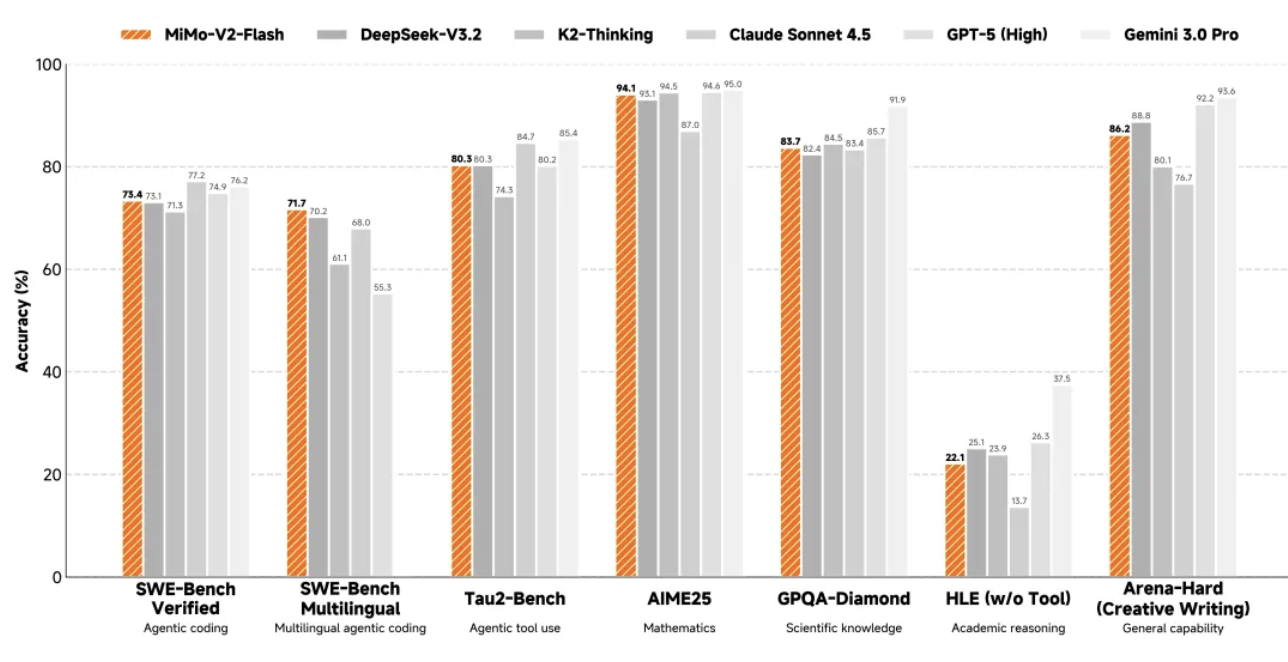
Nel test di benchmark multilingue SWE-Bench, il tasso di risoluzione è stato del 71,7%. Nel test di classificazione τ²-Bench, nel compito dell'agente intelligente, MiMo-V2-Flash ha ottenuto 95,3 punti nella categoria comunicazione, 79,5 punti nella categoria vendita al dettaglio e 66,0 punti nella categoria aviazione.
Il punteggio dell'agente di ricerca di BrowseComp era 45,4, ma è balzato a 58,3 dopo aver abilitato la gestione del contesto.
Questi dati dimostrano che MiMo-V2-Flash non solo è in grado di scrivere codice, ma anche di comprendere appieno la logica di attività complesse ed eseguire interazioni multi-turn con gli agenti. Anche le sue capacità di elaborazione di testi lunghi sono impressionanti; nei test reali, le sue prestazioni superano persino quelle del più grande Kimi-K2 Thinking, a dimostrazione delle potenti capacità di modellazione a lungo raggio dell'architettura ibrida di attenzione a finestra scorrevole.
Anche la qualità di scrittura è simile a quella dei modelli closed-source di fascia alta, il che significa che MiMo-V2-Flash non è solo uno strumento, ma anche un affidabile assistente quotidiano.
Il segreto per mantenere le prestazioni e ridurre i costi di 6 volte per l'output di testo lungo.
L'innovazione principale di MiMo-V2-Flash è il suo meccanismo ibrido di attenzione tramite finestra scorrevole.
Quando i modelli tradizionali su larga scala elaborano testi lunghi, il meccanismo di attenzione globale causa un'esplosione secondaria del carico computazionale, e anche la cache chiave-valore per l'archiviazione dei risultati intermedi aumenta vertiginosamente. Questa volta Xiaomi ha adottato un aggressivo rapporto 5:1, alternando 5 livelli di attenzione a finestra scorrevole e 1 livello di attenzione globale, con la finestra scorrevole che considera solo 128 token.
(Per chi non ha familiarità con l'intelligenza artificiale, ecco una breve spiegazione: nella modellazione su larga scala/elaborazione del linguaggio naturale, un "token" si riferisce alla più piccola unità di conteggio utilizzata dal modello durante la lettura e l'output del testo. Il modello non conta in modo fisso, come "un carattere cinese = 1, una parola inglese = 1", ma elabora il testo dividendolo in segmenti di token.)
In parole povere, il modello non ha bisogno di esaminare tutto il contenuto ogni volta; esamina solo i 128 token più recenti e occasionalmente controlla l'elenco globale. Ciò riduce significativamente i requisiti di elaborazione e archiviazione. Questo design riduce lo spazio di archiviazione della cache KV di quasi 6 volte, ma non compromette le capacità di testo lungo, supportando una finestra di contesto massima di 256k.
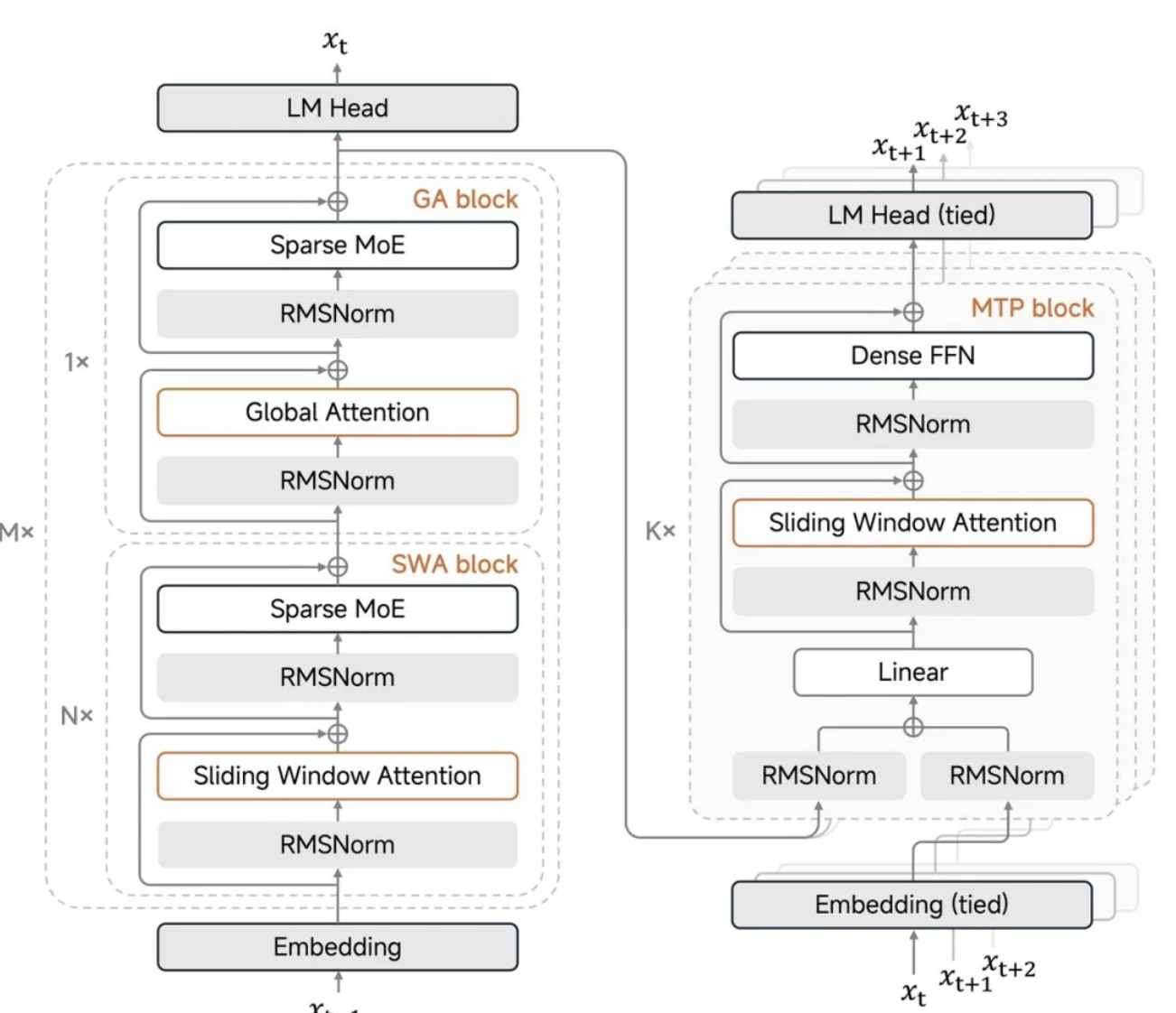
Il punto chiave è che Xiaomi ha anche sviluppato un "bias di attenzione apprendibile", che consente al modello di mantenere prestazioni stabili per testi lunghi anche con impostazioni di finestra così aggressive.
Luo Fuli ha sottolineato sui social media che una dimensione della finestra di 128 ha dimostrato di essere il "valore ottimale", mentre 512 in realtà comporta un degrado delle prestazioni. Questa scoperta è piuttosto controintuitiva; si potrebbe pensare che più grande è la finestra, meglio è, ma nei test reali, 128 è il valore ottimale. Inoltre, i valori di sink (valori di sink di attenzione) sono essenziali e non dovrebbero mai essere omessi.
Un'altra tecnologia all'avanguardia è la previsione multi-token leggera (MTP).
I modelli tradizionali possono generare un solo token alla volta durante la generazione di testo, proprio come un dattilografo che digita una parola alla volta. MiMo-V2-Flash, grazie al suo modulo MTP integrato nativamente, può predire più token in parallelo, indovinandone diversi contemporaneamente.
Nei test effettivi, può accettare in media da 2,8 a 3,6 token, aumentando direttamente la velocità di inferenza da 2 a 2,6 volte. Non è utile solo durante l'inferenza, ma accelera anche il campionamento e riduce i tempi di inattività della GPU durante la fase di training, il che rappresenta un doppio vantaggio.
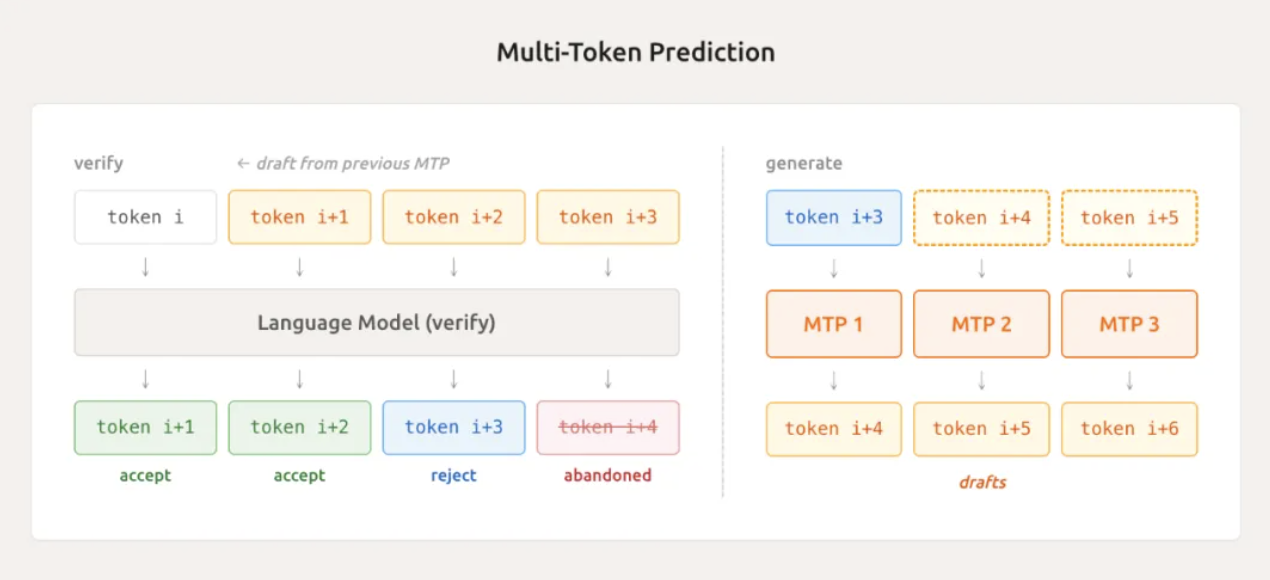
Luo Fuli ha affermato che con una configurazione MTP a tre livelli, è stata osservata una lunghezza di accettazione media superiore a 3, con conseguente aumento della velocità di codifica di circa 2,5 volte. Questo risolve efficacemente il problema dei tempi di inattività della GPU sprecati causati dai "campioni a coda lunga" nell'apprendimento per rinforzo basato su policy mini-batch.
Cosa sono i campioni a coda lunga? Sono quei task particolarmente difficili e lenti che trascinano con sé altri task, bloccando la GPU. MTP risolve questo problema, migliorando notevolmente l'efficienza.
Tuttavia, Luo Fuli ha anche ammesso che, a causa di limiti di tempo, questa volta non è stato possibile integrare completamente l'MTP nel ciclo di addestramento RL, ma è altamente compatibile con il processo. Xiaomi ha già reso open source l'MTP a tre livelli, rendendolo comodo per tutti da utilizzare e sviluppare nei propri progetti.
Come è possibile che le prestazioni non vengano compromesse quando viene utilizzato solo 1/50 della potenza di calcolo?
Durante la fase di pre-addestramento, il nuovo modello utilizza la precisione mista FP8 e viene addestrato su 27 trilioni di token di dati, supportando nativamente lunghezze di sequenza di 32k.
La precisione mista FP8 è una tecnica per la compressione delle rappresentazioni numeriche, che può ridurre l'utilizzo di memoria e accelerare l'addestramento mantenendo l'accuratezza. Questo metodo di addestramento non è comune nel settore e richiede una profonda ottimizzazione del framework sottostante.
Nella fase di formazione successiva, Xiaomi ha introdotto un'importante innovazione proponendo la Multi-Teacher Online Strategy Distillation (MOPD).
Le tradizionali pipeline di apprendimento per rinforzo con fine-tuning supervisionato non solo sono instabili nell'addestramento, ma sono anche estremamente costose dal punto di vista computazionale. L'approccio MOPD prevede che il modello studente venga campionata sulla propria distribuzione di policy e che più insegnanti esperti forniscano segnali di ricompensa densi in ogni posizione del token.
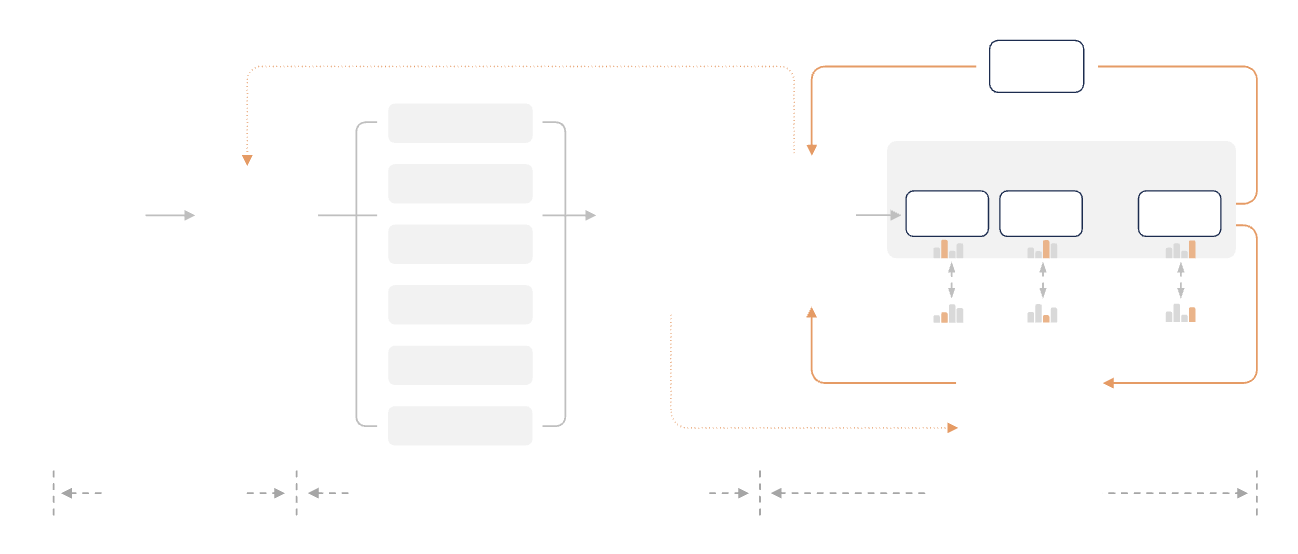
In parole povere, il modello studente svolge i compiti in modo indipendente e l'insegnante corregge ogni parola singolarmente, senza aspettare che l'intero brano sia scritto. Questo permette al modello studente di apprendere rapidamente le nozioni essenziali dall'insegnante e il processo di formazione è molto più stabile.
Il miglioramento più notevole riguarda l'efficienza. MOPD richiede solo 1/50 della potenza di calcolo dei metodi tradizionali per consentire ai modelli per studenti di raggiungere le massime prestazioni dei modelli per insegnanti. Ciò significa che Xiaomi può iterare i modelli più velocemente con meno risorse.
Inoltre, il MOPD supporta l'integrazione flessibile di nuovi insegnanti, e gli studenti modello possono diventare a loro volta insegnanti una volta cresciuti, dando vita a un ciclo chiuso di "insegnamento e apprendimento". Gli studenti di oggi possono diventare gli insegnanti di domani e, dopodomani, possono formare studenti ancora più forti. Questo approccio, simile a quello della bambola nidificata, è davvero ingegnoso.
Come afferma Luo Fuli, hanno preso in prestito il metodo On-Policy Distillation da Thinking Machines per fondere più modelli di apprendimento per rinforzo, ottenendo un notevole miglioramento dell'efficienza. Ciò ha gettato le basi per la costruzione di un sistema a ciclo continuo auto-rinforzante in cui i modelli degli studenti possono gradualmente evolversi in modelli più efficaci per gli insegnanti.
In termini di estensioni di apprendimento per rinforzo degli agenti, il team di ricerca Xiaomi MiMo-V2-Flash ha sviluppato oltre 100.000 attività verificabili basate su problemi reali di GitHub. La pipeline automatizzata viene eseguita su un cluster Kubernetes, in grado di eseguire più di 10.000 Pod contemporaneamente, con un tasso di successo del 70% nell'implementazione dell'ambiente.
Per le attività di sviluppo web, è stato sviluppato anche un validatore multimodale. Verifica i risultati dell'esecuzione del codice registrando video anziché screenshot statici, riducendo direttamente le illusioni visive e garantendo la correttezza delle funzioni.
Per gli sviluppatori, MiMo-V2-Flash può integrarsi perfettamente con gli ambienti di sviluppo più diffusi, come Claude Code, Cursor e Cline, e la sua finestra di contesto ultra-lunga da 256k supporta centinaia di cicli di interazione con gli agenti e chiamate agli strumenti.
Cosa significa 256k? Equivale più o meno a un romanzo di media lunghezza o a qualche decina di pagine di documentazione tecnica. Ciò significa che gli sviluppatori possono integrare direttamente MiMo-V2-Flash nei loro flussi di lavoro esistenti senza ulteriori adattamenti; possono utilizzarlo fin da subito.
Xiaomi ha inoltre contribuito con tutto il suo codice di inferenza a SGLang e ha condiviso la sua esperienza di ottimizzazione dell'inferenza sul blog LMSYS.
Il rapporto tecnico rivela i dettagli completi del modello, e i pesi del modello (incluso MiMo-V2-Flash-Base) sono pubblicati su Hugging Face con licenza MIT. Questo approccio open source completo è davvero raro tra le principali aziende cinesi.
MiMo-V2-Flash è attualmente disponibile gratuitamente sulla piattaforma API per un periodo di tempo limitato, consentendo agli sviluppatori di iniziare subito.
Le ambizioni di Xiaomi in materia di intelligenza artificiale vanno oltre il semplice assistente mobile.
Il lancio di MiMo-V2-Flash segna l'impegno a pieno titolo di Xiaomi nel campo dell'intelligenza artificiale.
Luo Fuli ha rivelato ulteriori informazioni sui social media: "MiMo-V2-Flash è stato lanciato ufficialmente. Questo è solo il secondo passo della nostra roadmap AGI". Il secondo passo è già di per sé impressionante, quindi quali altre grandi sorprese ci riserva? È qualcosa che non vediamo l'ora di vedere.
Naturalmente, Xiaomi ha anche ammesso apertamente nel suo rapporto tecnico che MiMo-V2-Flash è ancora indietro rispetto ai modelli closed-source più performanti. Tuttavia, il suo piano è chiaro: colmare il divario aumentando le dimensioni del modello e la potenza di calcolo, continuando al contempo a esplorare architetture di agenti più robuste ed efficienti.
La coevoluzione iterativa dei modelli di insegnanti e studenti nell'ambito del quadro MOPD lascia inoltre ampio spazio al futuro miglioramento delle capacità.
Considerando la questione da una prospettiva più ampia, questa rappresenta una scommessa strategica da parte di Xiaomi sull'intero ecosistema dell'intelligenza artificiale. Dagli smartphone all'IoT fino alle automobili, l'ecosistema hardware di Xiaomi necessita di una solida base di intelligenza artificiale, e MiMo-V2-Flash è chiaramente la pietra angolare che Xiaomi sta preparando per il suo intero ecosistema hardware.
Proprio come Xiaomi ha ridefinito lo standard di prezzo per i telefoni di punta un decennio fa con il suo telefono da 1999 yuan, MiMo-V2-Flash sta ora ridefinendo lo standard di prestazioni per i modelli open source di grandi dimensioni con un costo di 0,1 dollari per milione di token e un punteggio SWE-Bench del 73,4%.
Questa volta è arrivato davvero il "momento Xiaomi" del modello open source.
Indirizzo del modello HuggingFace:
http://hf.co/XiaomiMiMo/MiMo-V2-Flash
Indirizzo del rapporto tecnico:
http://github.com/XiaomiMiMo/MiMo-V2-Flash/blob/main/paper.pdf
#Benvenuti a seguire l'account WeChat ufficiale di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
