
“Un passo avanti” rispetto a GPT-5! Google lancia il pacchetto AI più potente, con l’abbonamento AI più costoso di sempre al prezzo di 1.800 yuan al mese

Il giorno prima del Google I/O dell'anno scorso, OpenAI ha lanciato GPT-4o.
Quest'anno le situazioni offensive e difensive sono diverse.
Qualche giorno fa, OpenAI ha rivelato che GPT-5 sarà All in One, ovvero integrerà vari prodotti. Proprio ora, Google ha implementato questa idea alla conferenza I/O e ha tirato fuori direttamente il suo contenitore di intelligenza artificiale più potente di sempre.
Dal lancio dei modelli Gemini 2.5 Pro e Flash, all'AI Mode, a Veo 3, Imagen 4 e ai kit di intelligenza artificiale per sviluppatori e creatori, Google ha praticamente compresso il percorso dal modello al prodotto in un'unica conferenza stampa.
Per essere più precisi, gli scenari applicativi dell'intelligenza artificiale più interessanti del momento sono stati "pre-sepolti" da Google nelle interfacce dei suoi prodotti, facendo capire alla gente che è ancora uno dei giganti dell'intelligenza artificiale al mondo, con la più grande forza ingegneristica e capacità di integrazione ecologica.
Non c'è da stupirsi che molti internauti abbiano scherzato dicendo che, dopo la conferenza stampa durata quasi due ore, un gran numero di start-up moriranno per mano di Google.
Tuttavia, non è difficile vedere che alcune funzioni presentate alla conferenza stampa sono ancora in fase di "trailer" e di test su piccola scala e potrebbero essere ancora lontane dall'essere realmente implementate.

Aiutami a "acquistare biglietti + trovare posti + compilare moduli" in una volta sola: il nuovo volume di ricerca basato sull'intelligenza artificiale di Google sta impazzendo.
L'intelligenza artificiale sta riscrivendo la logica di base della ricerca.
Alla conferenza I/O dello scorso anno, Google ha lanciato la funzionalità AI Overviews, che ora conta più di 1,5 miliardi di utenti attivi al mese.
L'intelligenza artificiale generativa ha gradualmente cambiato il modo in cui le persone effettuano ricerche, ma il risultato è che non ci accontentiamo più di inserire domande semplici nella casella di ricerca, ma poniamo domande più complesse, più lunghe e più multimodali.
Oggi Google ha nuovamente intensificato i suoi sforzi per integrare ricerca e intelligenza artificiale, lanciando un'esperienza di ricerca AI end-to-end: AI Mode.
Come ha spiegato Sundar Pichai, CEO di Google, questo è il modulo di ricerca basato sull'intelligenza artificiale più potente che Google abbia mai sviluppato. Non solo possiede capacità di ragionamento più avanzate e di comprensione multimodale, ma supporta anche un'esplorazione approfondita attraverso domande contestuali e collegamenti web.

Ad esempio, quando un utente si trova di fronte a una domanda di ricerca che richiede un'interpretazione complessa, la modalità AI può attivare il meccanismo di "ricerca approfondita", ragionare tra diverse informazioni e generare un report di citazioni di livello esperto in pochi minuti, facendo risparmiare ore di tempo di ricerca.
Allo stesso tempo, Google ha integrato le funzionalità multimodali del Progetto Astra nella ricerca per migliorare ulteriormente l'interattività in tempo reale della ricerca. Grazie alla funzione Cerca in tempo reale, gli utenti possono semplicemente accendere la fotocamera per porre domande e ricevere feedback in tempo reale.
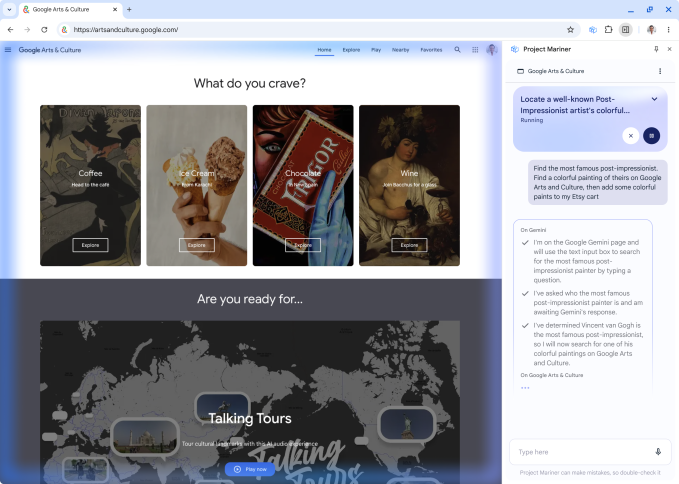
Quest'anno è il primo anno di Agent e Google ha anche lanciato con cura la funzionalità Project Mariner Agent per aiutare gli utenti a completare le attività in modo più efficiente.
Ad esempio, con una sola frase, "Aiutami a trovare due biglietti a prezzi accessibili per la partita di sabato, che si trovano al piano inferiore", AI Mode può cercare automaticamente opzioni su più piattaforme di biglietteria, confrontare prezzi e inventario in tempo reale e completare operazioni noiose come la compilazione di moduli, migliorando notevolmente l'efficienza.
Grazie al modello Gemini e al Google Shopping Graph, Google AI Mode può aiutarti a restringere il campo dei tuoi prodotti e a trovare ispirazione. Se vuoi vedere come ti stanno i vestiti, carica una tua foto per provarli virtualmente.
Inoltre, la modalità AI offre anche potenti funzionalità di personalizzazione. Può fornire suggerimenti personalizzati in base alle preferenze contestuali dell'utente e generare grafici e risultati di visualizzazione, in particolare nelle ricerche sportive e finanziarie.
Questa funzionalità è ora completamente disponibile negli Stati Uniti e in futuro verrà estesa ad altre regioni.
Essendo in grado di scrivere codice e salvare token, Gemini 2.5 ottiene la personalità "studente maestro"
In termini di capacità del modello, Google ha rilasciato la versione I/O di Gemini 2.5 Pro, che ha raggiunto il primo posto in classifica.
Ora, Gemini 2.5 Pro introduce una modalità di miglioramento dell'inferenza chiamata "Deep Think". Questa funzione prende in considerazione più presupposti prima di generare una risposta, fornendo una comprensione più approfondita del contesto della domanda.

2.5 Pro Deep Think si è classificato al primo posto nelle Olimpiadi della matematica degli Stati Uniti del 2025 (USAMO) e nel LiveCodeBench (benchmark di programmazione) e ha ottenuto un punteggio dell'84,0% nel MMMU (test di ragionamento multimodale).
Google ha tuttavia affermato che dedicherà più tempo a condurre valutazioni di sicurezza all'avanguardia e che chiederà ulteriori consigli agli esperti in materia. Come primo passo, la funzionalità Deep Think sarà attualmente aperta a un gruppo ristretto di tester tramite l'API Gemini.
È stato migliorato anche il Gemini 2.5 Flash, incentrato sull'efficienza.
La nuova versione 2.5 di Flash presenta miglioramenti nei benchmark chiave, quali ragionamento, multimodalità, codice e contesto lungo, risultando al contempo più efficiente, con il 20-30% in meno di token utilizzati nella valutazione.
Flash 2.5 è ora disponibile per tutti nell'app Gemini e verrà distribuito a inizio giugno per gli sviluppatori tramite Google AI Studio e per le aziende tramite Vertex AI.
In termini di esperienza dello sviluppatore, 2.5 Pro e 2.5 Flash introdurranno la funzione "Thought Summary" in Gemini API e Vertex AI, che può presentare il percorso di ragionamento del modello in modo strutturato con titoli, informazioni chiave e strumenti di chiamata.
Anche gli sviluppatori ne trarranno vantaggio. Google ha annunciato che supporterà ufficialmente gli strumenti MCP nell'API e nell'SDK Gemini, consentendo agli sviluppatori di accedere facilmente a più strumenti open source ed ecosistemi di plug-in.
Musica, film e immagini sono tutti disponibili online. Google ha reso l'intelligenza artificiale un successo
In questa conferenza, Google ha presentato una nuova generazione di modelli di immagini e video: Veo 3 e Imagen 4.
A differenza della generazione video tradizionale, Veo 3 è un modello di generazione video che supporta l'audio. Può simulare il traffico, il canto degli uccelli e perfino le conversazioni dei personaggi nelle scene di strada urbane, migliorando notevolmente il senso di immersione.
Il modello non solo genera video basati su prompt di testo e immagini, ma sincronizza anche con precisione l'ambiente fisico con la sincronizzazione labiale, migliorando notevolmente il realismo della creazione del video.
Veo 3 è attualmente disponibile per gli abbonati Ultra sull'app Gemini e sulla piattaforma Flow, ed è supportato dagli utenti aziendali sulla piattaforma Vertex AI.

Il Flow di cui sopra è uno strumento di intelligenza artificiale per la realizzazione di film creato da Google per i creatori.
Gli utenti descrivono semplicemente le scene dei film in linguaggio naturale per gestire attori, location, oggetti di scena e stile, generando automaticamente segmenti narrativi. Flow è ora disponibile per gli utenti di Gemini Pro e Ultra negli Stati Uniti, con un'implementazione globale in corso.
In termini di generazione delle immagini, la nuova versione di Imagen 4 è più precisa e veloce e può visualizzare in modo realistico e dettagliato tessuti, gocce d'acqua e peli di animali, riuscendo anche a generare stili più astratti.
Supporta la risoluzione 2K e diversi rapporti d'aspetto, ed è notevolmente ottimizzato nella composizione e nell'ortografia, il che lo rende adatto alla realizzazione di biglietti d'auguri, poster e persino fumetti.
Imagen 4 è disponibile oggi in Gemini, Whisk, Vertex AI e nelle applicazioni Slides, Vids e Docs di Workspace. Si dice che in futuro verrà lanciata una versione dieci volte più veloce.

Per quanto riguarda la creazione musicale, Google ha ampliato l'accesso al Music AI Sandbox basato su Lyria 2 e ha lanciato il modello di generazione musicale interattiva Lyria RealTime. Il modello è ora disponibile per gli sviluppatori tramite API e AI Studio.
Considerando che i contenuti generati da Veo 3, Imagen 4 e Lyria 2 continueranno a portare la filigrana SynthID, Google ha rilasciato un nuovo SynthID Detector.
Gli utenti devono solo caricare i file per verificare se contengono filigrane SynthID, utilizzate per contrastare la contraffazione e tracciare la fonte dei contenuti di intelligenza artificiale.
Google vuole creare un "modello mondiale" che possa addirittura aiutarti a completare le attività?
Google spera di trasformare Gemini in un "modello mondiale" in grado di pianificare, comprendere e simulare tutti gli aspetti del mondo reale.
Demis Hassabis, CEO di Google DeepMind, ha affermato che questa direzione è uno dei concetti chiave del Progetto Astra.

Nel corso dell'ultimo anno, Google ha gradualmente integrato in Gemini Live la comprensione dei video, la condivisione dello schermo, le funzioni di memoria, ecc. Ora, al nuovo output vocale di Gemini è stata aggiunta l'audio nativo, che è più naturale; vengono potenziate simultaneamente anche le capacità di memoria e di utilizzo del computer.
Inoltre, Google sta anche studiando come utilizzare le funzionalità degli agenti per aiutare le persone a gestire il multitasking.
Project Mariner è uno di questi, in grado di completare fino a dieci attività contemporaneamente, come la richiesta di informazioni, la prenotazione, lo shopping e la ricerca. È ora disponibile per gli utenti Ultra negli Stati Uniti e sarà presto integrato nell'API Gemini e in altri prodotti principali.
Vengono rilasciate numerose nuove funzionalità di intelligenza artificiale. Emergerà una caratteristica davvero eccezionale?
NotebookLM ha annunciato ufficialmente ieri di essere diventata la seconda app per la produttività e la nona in assoluto nell'App Store nel giro di 24 ore dal suo lancio.
NotebookLM è un'importante esplorazione degli strumenti di Google per prendere appunti basati sull'intelligenza artificiale e offre funzioni quali la panoramica audio e la mappatura mentale.
Tra queste, le panoramiche audio supportano attualmente più di 80 lingue e questa settimana Google ha anche annunciato che introdurrà una maggiore personalizzazione per questa funzionalità. Gli utenti possono scegliere la lunghezza del riassunto in base alle proprie esigenze, che si tratti di una rapida consultazione o di una lettura approfondita.
Questa funzionalità sarà inizialmente disponibile in inglese e in seguito verrà estesa ad altre lingue.
Allo stesso tempo, Google risponde anche alle esigenze degli utenti in termini di presentazione visiva e aggiungerà presto una funzione di panoramica video a NotebookLM. Gli utenti possono convertire il contenuto delle note in video didattici con un solo clic, trasmettendo le informazioni in modo più intuitivo.

Nel campo della programmazione dell'intelligenza artificiale, Google ha portato anche gli ultimi progressi di Jules.
Questo assistente di programmazione autonomo, apparso originariamente in Google Labs, è in grado di comprendere il codice e di completare autonomamente attività di sviluppo come la scrittura di test, la creazione di funzioni e la correzione di bug. Ora è ufficialmente entrata nella fase di beta testing pubblica.

Inoltre, Google ha lanciato un nuovo servizio in abbonamento, Google AI Ultra.
Il piano offre agli utenti professionali accesso illimitato ai modelli più potenti e alle funzionalità avanzate di Google. È adatto a professionisti come registi, sviluppatori, creativi, ecc., con una quota mensile di 249,99 $.
Il programma è attualmente disponibile negli Stati Uniti e presto sarà esteso ad altri Paesi.

In effetti, oggi all'intelligenza artificiale non mancano né modelli né funzioni. Ciò che è davvero raro è un "prodotto eccezionale" che possa essere integrato nella vita quotidiana e penetrare davvero nella mente degli utenti comuni.
Google lo sa bene e sta lavorando duramente per trovare la risposta.
Possiamo quindi vedere che in questa conferenza stampa Google ha fatto quasi tutto e menzionato tutto: dai testi, alle immagini, ai video, alla musica, alla ricerca, agli agenti e agli strumenti creativi.
Le carte sono state svelate e la tecnologia è pronta. Ora tutto ciò di cui Google ha bisogno è di una mossa che colpisca davvero i punti deboli dell'utente.
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
