
Una conversazione con il team di Ideal Assisted Driving: come la guida assistita si è evoluta da “scimmia” a “umana”

Più o meno nello stesso periodo dell'anno scorso, iFanr e Dongchehui hanno avuto un incontro con il team di Ideal Assisted Driving presso l'Ideal Beijing R&D Center. All'epoca, la nuova architettura tecnologica di Ideal Assisted Driving, "end-to-end + VLM Visual Language Model", stava per essere implementata nei veicoli. La dichiarazione del team di Ideal Assisted Driving all'epoca era la seguente:
Il quadro teorico alla base del "modello di linguaggio visivo end-to-end + VLM" è la "risposta definitiva" alla guida autonoma.
Con la transizione dell'architettura tecnica "end-to-end + modello di linguaggio visivo VLM" a VLA (Vision-Language-Action, modello di linguaggio visivo-azione), siamo un passo più vicini alla "risposta definitiva".
Secondo Li Xiang e il team di guida assistita di Ideal, questo è un passo fondamentale nell'evoluzione delle capacità di guida assistita di Ideal dalla fase "monkey" a quella "human". Contemporaneamente, oggi abbiamo visitato il centro di ricerca e sviluppo di Ideal a Pechino per continuare a discutere delle nuove tendenze in questo campo con il team di guida assistita di Ideal.

▲ Lang Xianpeng, vicepresidente senior della ricerca e sviluppo sulla guida autonoma presso Ideal Auto
Nella guida assistita, qual è la differenza tra scimmie ed esseri umani?
Prima che la soluzione di guida assistita di Ideal passasse al "modello di linguaggio visivo end-to-end + VLM" lo scorso anno, aveva adottato l'architettura tecnica standard del settore "Percezione – Pianificazione – Controllo". Questa architettura si basa sulla scrittura da parte degli ingegneri di regole corrispondenti per guidare il controllo del veicolo in base a diverse condizioni di traffico reali, ma è difficile coprire tutte le condizioni di traffico reali.

Questa è l'"era meccanica" della guida assistita. La guida assistita può gestire solo situazioni con regole corrispondenti e non ha capacità di pensiero e apprendimento.
Il "modello di linguaggio visivo end-to-end + VLM" è l'"era delle scimmie" della guida assistita. Rispetto alle macchine, le scimmie sono più intelligenti e hanno una certa capacità di imitare e imparare. Naturalmente, le scimmie sono anche più attive e disobbedienti.
L'essenza del modello di linguaggio visivo "end-to-end + VLM" è l'apprendimento per imitazione, basato su un'ampia gamma di dati di guida umana per l'addestramento. La quantità e la qualità di questi dati determinano le prestazioni. Inoltre, per motivi di sicurezza, in questa architettura, il modello di linguaggio visivo VLM, responsabile di scenari complessi, non partecipa al controllo del veicolo; fornisce solo supporto decisionale e guida della traiettoria.

VLA (Vision-Language-Action) è l'"era umana" della guida assistita, che possiede la capacità di "pensare, comunicare, ricordare e migliorare se stessi".
Le scimmie hanno attraversato una lunga trasformazione per diventare esseri umani. In teoria, l'apprendimento per imitazione del modello di linguaggio visivo end-to-end + VLM può anche apprendere quasi tutti i dati di guida umani in un lungo periodo di tempo e comportarsi quasi come un essere umano.
Ma il prezzo è il "tempo".
Lang Xianpeng, vicepresidente senior della ricerca e sviluppo sulla guida autonoma presso Ideal Auto, ha dichiarato:
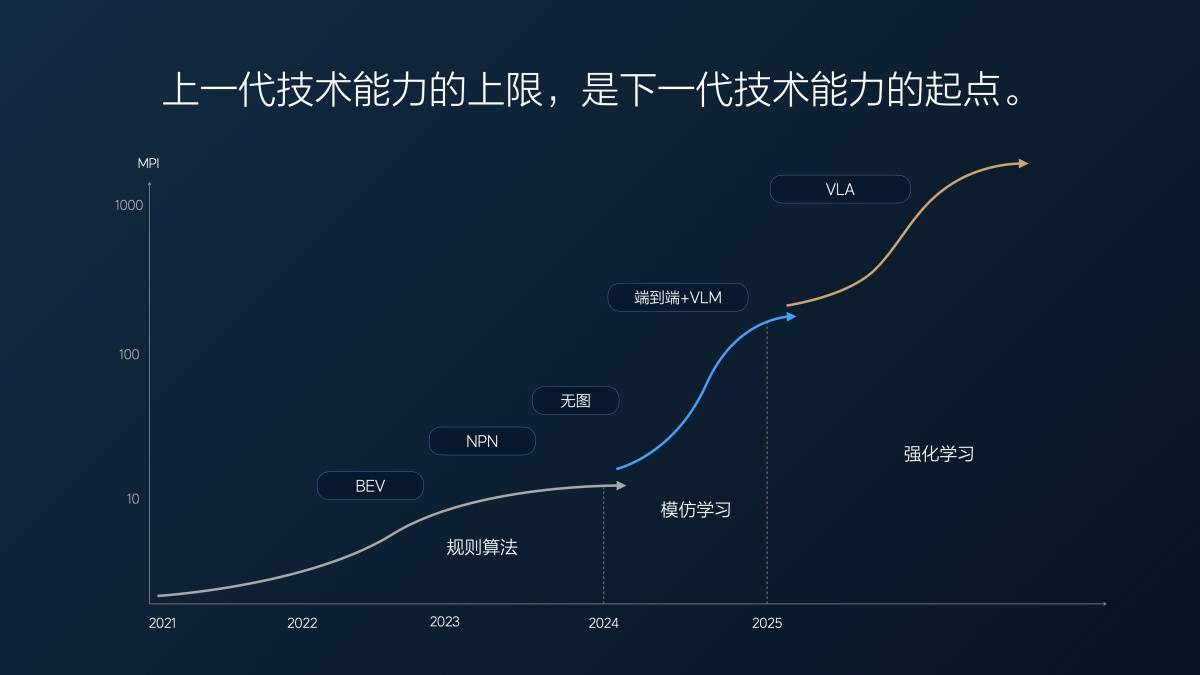
Il nostro MPI (chilometraggio medio di acquisizione) end-to-end effettivo lo scorso anno era di circa dieci chilometri nella prima versione di luglio dell'anno scorso. All'epoca pensavamo che fosse piuttosto buono perché la nostra versione senza mappe era in fase di elaborazione da molto tempo e il MPI completo (autostrada + città) era di soli 10 chilometri circa.
Da 1 a 2 milioni di clip (videoclip utilizzati per addestrare la guida assistita end-to-end), e poi a 10 milioni di clip, con l'aumentare della quantità di dati, l'MPI ha raggiunto i 100 chilometri all'inizio di quest'anno. In 7 mesi, l'MPI è aumentato di dieci volte, in media diverse volte al mese.
Ma dopo aver raggiunto i 10 milioni di clip, abbiamo scoperto un problema: aumentare semplicemente la quantità di dati era inutile; la quantità di dati preziosi si stava riducendo. È come un esame: quando si fallisce, prendere un punteggio casuale può migliorare il punteggio molto rapidamente. Ma quando si è sugli 80 o 90, è molto difficile migliorare anche solo di 5 o 10 punti.
A questo punto, abbiamo utilizzato il super allineamento per forzare il modello a produrre risultati che soddisfacessero le aspettative umane. Abbiamo anche selezionato alcuni dati e li abbiamo integrati con il super allineamento per migliorare ulteriormente le capacità del modello. Questo approccio ha avuto un certo effetto, ma ci sono voluti circa cinque mesi, da marzo a fine luglio di quest'anno, per ottenere un miglioramento di circa il doppio delle prestazioni del modello.
Questo è il primo problema riscontrato dall'architettura tecnica "end-to-end + VLM visual language model" dopo il suo rapido progresso: più passa il tempo, più scarsi diventano i dati utili e più lento è il miglioramento delle prestazioni del modello.

È stato anche esposto il problema fondamentale. Lang Xianpeng ha affermato:
In sostanza, l'attuale apprendimento imitativo end-to-end manca di capacità di pensiero logico approfondite. È come una scimmia alla guida di un'auto. Datele delle banane e potrebbe comportarsi come previsto, ma non ne capirà il motivo. Potrebbe venire da voi quando suonate un gong, o ballare quando suonate un tamburo, ma non ne capirà il motivo.
Pertanto, l'architettura end-to-end non ha la capacità di pensare in modo approfondito. Al massimo, è una risposta allo stress. In altre parole, dato un input, il modello fornisce un output. Non c'è una logica profonda dietro.
Ecco perché aggiungiamo un Visual Language Model (VLM) al modello end-to-end di grandi dimensioni. Il VLM ha maggiori capacità di comprensione e di pensiero, consentendo un migliore processo decisionale. Tuttavia, questo modello è lento a elaborare e non è strettamente integrato con il modello end-to-end di grandi dimensioni. Di conseguenza, il modello end-to-end di grandi dimensioni spesso non riesce a comprendere o accettare le decisioni prese dal VLM.
L'anno scorso, in questo stesso periodo, il team Ideal Assisted Driving ha affermato:
Ci sono due tendenze future. In primo luogo, la scala dei modelli aumenterà. Il Sistema 1 e il Sistema 2 sono attualmente due modelli end-to-end con un VLM. Questi due modelli potrebbero essere uniti. Attualmente, sono scarsamente accoppiati, ma in futuro potranno esserlo più strettamente. In secondo luogo, possiamo anche imparare dall'attuale tendenza dei modelli multimodali di grandi dimensioni. Questi modelli si stanno muovendo verso la multimodalità nativa, in grado di gestire linguaggio, parlato, visione e lidar. Questo è un aspetto che prenderemo in considerazione in futuro.
La tendenza è diventata rapidamente realtà.
Lang Xianpeng ha anche spiegato i motivi del passaggio da end-to-end + VLM a VLA:
Quando lavoravamo all'end-to-end l'anno scorso, riflettevamo costantemente se fosse sufficiente e, in caso contrario, cos'altro dovevamo fare.
Abbiamo condotto alcune ricerche preliminari sulla VLA. In effetti, la ricerca preliminare sulla VLA rappresenta la nostra comprensione del fatto che l'intelligenza artificiale non è un apprendimento per imitazione. Deve possedere capacità di pensiero e ragionamento come gli esseri umani. In altre parole, deve essere in grado di risolvere cose che non ha mai visto o scenari sconosciuti. Perché questo può avere una certa capacità di generalizzazione end-to-end, ma non è sufficiente per dire che ha capacità di pensiero.
Proprio come una scimmia, potrebbe fare qualcosa che pensi sia al di là della tua immaginazione, ma non sempre lo farà. Ma gli esseri umani sono diversi. Gli esseri umani possono crescere e iterare, quindi dobbiamo sviluppare la nostra intelligenza artificiale in linea con lo sviluppo dell'intelligenza umana. Siamo passati rapidamente dalla soluzione end-to-end alla VLA.
VLA (Vision-Language-Action) è la tendenza di pensiero dell'anno scorso e l'architettura tecnica che oggi è diventata realtà.
Sebbene VLA e VLM differiscano solo per una lettera, le loro connotazioni sono molto diverse.
La visione in VLA si riferisce all'immissione di varie informazioni dei sensori, tra cui informazioni di navigazione, che consentono al modello di comprendere e percepire lo spazio.
Il linguaggio VLA si riferisce alla capacità del modello di riassumere, tradurre, comprimere e codificare la comprensione spaziale percepita in un'espressione linguistica, proprio come un essere umano.
L'azione di VLA è il modello che genera una strategia comportamentale basata sul linguaggio di codifica della scena per guidare l'auto.
La differenza più intuitiva è che le persone possono controllare l'auto attraverso il linguaggio. Possono farla rallentare o accelerare, girare a sinistra o a destra parlando. Questo è dovuto principalmente alla componente linguistica. I comandi ricevuti dal modello più ampio di comandi umani sono anche comandi all'interno del modello VLA, il che equivale a connettere persone e auto.
Inoltre, non esiste alcuna barriera tra visione e comportamento. La velocità e l'efficienza dall'input delle informazioni visive all'output del comportamento di controllo del veicolo risultano notevolmente accelerate, e i problemi della lentezza del VLM e della mancanza di comprensione end-to-end del VLM vengono risolti.
Una differenza più significativa è la capacità di Chain of Thought (CoT). Il modello VLA ha una frequenza di inferenza di 10 Hz, più di tre volte superiore a quella del VLM. Offre inoltre una percezione e una comprensione più complete dell'ambiente circostante, consentendo un ragionamento più rapido e razionale e la generazione di decisioni di guida.
Oltre alle capacità di pensiero e di comunicazione, il VLA ha anche una certa capacità di memoria, che gli consente di ricordare le preferenze e le abitudini del proprietario, nonché una capacità di apprendimento autonomo piuttosto forte.

▲ Ideal i8 è il primo modello ad utilizzare la tecnologia Ideal VLA
Guida assistita ideale "Flying Life"
Nel mondo reale, se gli esseri umani vogliono diventare conducenti esperti, devono prima iscriversi a una scuola guida e prendere la patente, poi applicare un "adesivo di tirocinio" e mettersi in viaggio, guidando su strade vere per alcuni anni.
Lo stesso vale per la precedente formazione sulla guida assistita, che non solo richiede dati di guida reali per la formazione, ma richiede anche un gran numero di prove su strada nel mondo reale.
In alcuni romanzi, alcuni concorrenti talentuosi possono diventare maestri di arti marziali con livelli di abilità estremamente elevati attraverso la lettura, come l'"Immortale della spada confuciana" Xie Xuan in "Il canto della giovinezza" e Xuanyuan Jingcheng in "Lo spadaccino nella neve".
Tuttavia, nei romanzi tradizionali di arti marziali, ci sono solo personaggi come Wang Yuyan in "I semidei e i semidiavoli" che sono esperti nei classici delle arti marziali ma non hanno vere e proprie capacità di combattimento.

▲ Immagini da "Speeding Life"
Naturalmente, ci sono anche situazioni intermedie: nel film di corse "Speeding Life", il pilota automobilistico squattrinato Zhang Chi riproduceva costantemente nella sua mente le complesse condizioni della pista nella zona di Bayinbuluke, guidava mentalmente 20 volte al giorno, simulava la guida più di 36.000 volte in 5 anni e poi, quando tornava sulla pista reale, diventava il campione.
Guidare virtualmente, migliorare costantemente e superare i migliori risultati del passato: questo è "l'algoritmo".
Tuttavia, prima che Zhang Chi tornasse in pista e diventasse nuovamente il pilota campione, aveva già dato prova del suo valore su questa pista molte volte e accumulato molta esperienza pratica di guida.
Auto vera e strada vera, accumulare esperienza fino a comprendere tutte le condizioni stradali di questa pista, questi sono i "dati".

Lang Xianpeng ha affermato che per sviluppare un buon modello VLA sono necessari quattro livelli di capacità: dati, algoritmi, potenza di calcolo e capacità ingegneristiche.
Ideal ha da tempo sottolineato la sua abbondanza di dati, l'eccellenza dei dati, la validità del database e l'accuratezza dell'etichettatura e del data mining. Per quanto riguarda i dati, Ideal ha anche una nuova competenza: generare training sui dati.

Il modello globale viene utilizzato per ricostruire la scena, e poi scene simili vengono generate sulla base dei dati reali ricostruiti. Ad esempio, è ideale ricostruire una scena ETC ad alta velocità nel modello globale. In questo scenario, non solo è possibile utilizzare le condizioni dei dati reali originali, come un terreno soleggiato e asciutto durante il giorno, ma è anche possibile generare scene come neve intensa durante il giorno con terreno scivoloso e pioggia leggera di notte con scarsa visibilità.
Anche l'algoritmo di addestramento ideale per i modelli VLA è strettamente correlato ai dati generati. Lang Xianpeng ha spiegato:
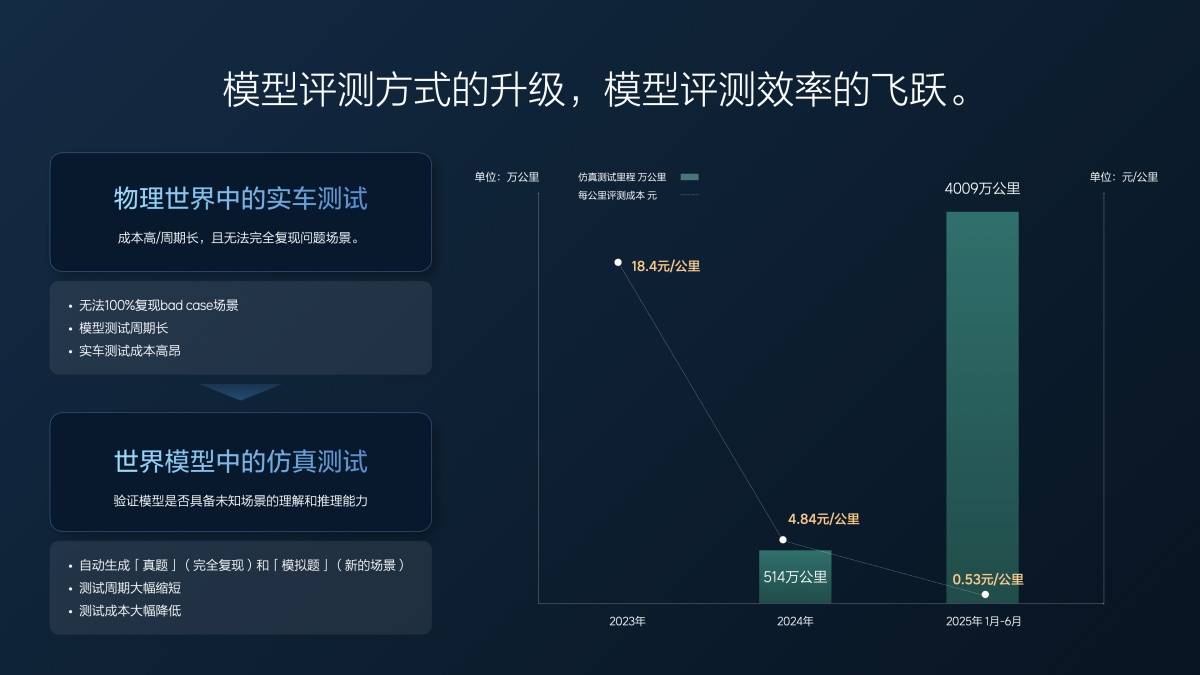
Non abbiamo ancora raggiunto lo sviluppo end-to-end nel 2023. Il chilometraggio effettivo di prova dei veicoli reali all'anno è di circa 1,57 milioni di chilometri e il costo al chilometro è di 18 yuan.
Quando abbiamo iniziato a lavorare sui sistemi end-to-end, una parte del nostro lavoro era già stata svolta tramite test di simulazione. Nel corso del 2024, abbiamo percorso circa 5 milioni di chilometri in test di simulazione e oltre 1 milione di chilometri in test su veicoli reali. Il costo medio è sceso a meno di 5 yuan al chilometro, che comunque ammontava a circa 30 milioni di yuan. Tuttavia, con gli stessi 30 milioni di yuan, siamo riusciti a testare 6 milioni di chilometri.
Nei primi sei mesi di quest'anno (dal 1° gennaio al 30 giugno), abbiamo percorso 40 milioni di chilometri di test, di cui solo 20.000 su veicoli reali, coprendo scenari di base. Tutti i nostri test, inclusi il Super Alignment e le attuali funzionalità VLA che avete visto, vengono eseguiti tramite simulazione. Il costo è di 0,5 centesimi al chilometro, coprendo a malapena i costi dell'elettricità e del server. Inoltre, la qualità dei test è elevata, con tutti i casi e gli scenari completamente replicati e accurati, garantendo risultati accurati. L'aumento del chilometraggio dei test e il miglioramento della qualità dei test hanno aumentato l'efficienza della ricerca e sviluppo.
In molti si sono chiesti se fosse impossibile per noi costruire un VLA in sei mesi e se non fossimo nemmeno riusciti a testarlo completamente. In realtà, ne abbiamo fatti molti.
Oltre al basso costo, il vantaggio dei test di simulazione è la capacità di riprodurre perfettamente la scena. Nei test reali, è difficile riprodurre una scena al 100%. Per il modello VLA, anche la minima differenza nella riproduzione della scena può comportare un'enorme differenza nelle prestazioni di guida.

In questo senso, la forma di addestramento ideale del modello VLA è in qualche modo simile al modello del film "Speeding Life", in cui il protagonista conduce continuamente un addestramento virtuale basato sull'esperienza di guida reale.
Naturalmente, l'addestramento del modello VLA richiede anche un'enorme potenza di calcolo. L'attuale potenza di calcolo totale di Ideal è di 13 EFLOPS, di cui 3 EFLOPS dedicati all'inferenza e 10 EFLOPS dedicati all'addestramento. Convertito in schede grafiche, questo equivale a 20.000 GPU NVIDIA H20 per l'addestramento e 30.000 GPU NVIDIA L20 per l'inferenza.

Domande e risposte chiave
D: La guida assistita intelligente presenta un "triangolo impossibile" – efficienza, comfort e sicurezza – che sono reciprocamente vincolati e potrebbero essere difficili da raggiungere simultaneamente in questa fase. A quale parametro sta attualmente dando priorità il VLA di Ideal Auto? Ha appena menzionato l'MPI. Possiamo dedurre che l'obiettivo finale di Ideal Auto sia migliorare la sicurezza per ridurre efficacemente i sorpassi?
Lang Xianpeng: L'MPI è una delle nostre metriche. Un'altra è l'MPA, che si riferisce al chilometraggio prima di un incidente. I proprietari di auto ideali subiscono un incidente circa ogni 600.000 chilometri di guida umana, mentre chi utilizza la guida assistita subisce un incidente ogni 3,5-4 milioni di chilometri. Continueremo a migliorare questi dati sul chilometraggio. Il nostro obiettivo è aumentare l'MPA a 10 volte quello della guida umana, il che significa che è 10 volte più sicuro della guida umana, e raggiungere un tasso di incidenti di 6 milioni di chilometri. Tuttavia, questo obiettivo può essere raggiunto solo dopo aver migliorato il modello VLA.
Abbiamo anche analizzato l'MPI. Sebbene alcuni rischi per la sicurezza possano portare al sorpasso del conducente, anche altri fattori, come lo scarso comfort in caso di frenate improvvise o brusche, possono indurre il sorpasso del conducente. Sebbene i rischi per la sicurezza non si verifichino sempre, gli utenti potrebbero comunque essere riluttanti a utilizzare la guida assistita se il comfort di guida non è ottimale. Poiché l'MPI misura la sicurezza, oltre alla sicurezza stessa, ci siamo concentrati sul miglioramento del comfort di guida nell'MPI. Provate le funzionalità di guida assistita dell'Ideal i8 e scoprirete un significativo miglioramento del comfort rispetto alle versioni precedenti.
L'efficienza viene dopo la sicurezza e il comfort. Ad esempio, se prendiamo la strada sbagliata, anche se ci sarà una perdita di efficienza, non la correggeremo immediatamente adottando misure pericolose. Dobbiamo comunque perseguire l'efficienza sulla base della sicurezza e del comfort.

D: Quali sono le difficoltà del modello VLA? Quali sono i requisiti per le aziende? Quali sfide dovrà affrontare un'azienda se desidera implementare il modello VLA?
Lang Xianpeng: Molti si sono chiesti se le case automobilistiche possano saltare l'algoritmo della regola precedente e la fase end-to-end se vogliono sviluppare un modello VLA. Credo che non sia possibile.
Sebbene i dati, gli algoritmi e altri aspetti del VLA possano differire dai modelli precedenti, si basano comunque su basi preesistenti. Senza un ciclo chiuso completo di dati raccolti da veicoli reali, non ci sono dati per addestrare il modello globale. Ideal Auto è stata in grado di implementare il modello VLA perché dispone di 1,2 miliardi di punti dati. Solo con una comprensione approfondita di questi dati possiamo generare dati migliori. Senza queste basi di dati, in primo luogo, è impossibile addestrare il modello globale e, in secondo luogo, non è chiaro che tipo di dati generare.
Allo stesso tempo, il supporto della potenza di calcolo per la formazione di base e per l'inferenza richiede molti fondi e capacità tecniche, che non possono essere completati senza un'accumulazione preventiva.
D: Quest'anno, i test effettivi sui veicoli di Ideal sono di 20.000 chilometri. Quali sono le basi per ridurre significativamente i test effettivi sui veicoli?
Lang Xianpeng: Riteniamo che i test su auto reali presentino numerose sfide. Il costo è un problema, ma il più significativo è l'impossibilità di replicare completamente lo scenario esatto in cui si è verificato il problema durante i test. Inoltre, i test su auto reali sono inefficienti, poiché richiedono ai conducenti di guidare il veicolo e poi di riprovarlo. Le nostre simulazioni attuali sono paragonabili ai test su auto reali. Oltre il 90% dei test sull'attuale Super Edition e sulla versione VLA dell'Ideal i8 è simulato.
Dallo scorso anno utilizziamo test di simulazione per verificare la nostra versione end-to-end. Riteniamo che sia altamente affidabile ed efficace, quindi lo abbiamo sostituito ai test su veicoli reali. Sebbene alcuni test siano insostituibili, come i test di durata dell'hardware, generalmente utilizziamo test di simulazione per i test relativi alle prestazioni, con risultati eccellenti.
Con l'avvento dell'era industriale, i processi di "taglia e brucia" sono stati sostituiti dalla meccanizzazione; con l'avvento dell'era dell'informazione, Internet ha sostituito una notevole quantità di lavoro. Lo stesso vale nell'era della guida autonoma. Con l'avvento dell'era end-to-end, siamo passati all'utilizzo dell'intelligenza artificiale per la guida autonoma. Dall'impiego di un gran numero di ingegneri e tester di algoritmi a un approccio basato sui dati, stiamo migliorando le capacità di guida autonoma attraverso processi di dati, piattaforme di dati e iterazioni di algoritmi. Nell'era dei modelli automatizzati virtualizzati (VLA) su larga scala, l'efficienza dei test è il fattore chiave per il miglioramento delle capacità. Per ottenere un'iterazione rapida, è necessario eliminare i fattori che la ostacolano. Se sono ancora coinvolti significativi interventi manuali e su veicoli reali, la velocità sarà ridotta. Non si tratta necessariamente di sostituire i test sui veicoli reali; piuttosto, la tecnologia e l'approccio richiedono intrinsecamente l'uso di test di simulazione. Senza questo, non stiamo praticando l'apprendimento per rinforzo né sviluppando modelli VLA.
D: VLA in realtà non sovverte end-to-end + VLM, quindi si può dire che VLA è un'innovazione che tende a concentrarsi sulle capacità ingegneristiche?
Zhan Kun (Esperto Senior di Algoritmi, Guida Autonoma, Ideal Auto): La VLA è più di una semplice innovazione ingegneristica. Se siete interessati all'intelligenza incarnata, noterete che questa tendenza è guidata dall'applicazione di modelli di grandi dimensioni al mondo fisico. Ciò implica essenzialmente lo sviluppo di un algoritmo VLA. Il nostro modello VLA mira ad applicare le idee e gli approcci dell'intelligenza incarnata al campo della guida autonoma. Siamo stati i primi a proporlo e a metterlo in pratica. La VLA è anche end-to-end, poiché la sua essenza è l'input della scena e l'output della traiettoria, un concetto simile alla VLA. Tuttavia, l'innovazione algoritmica richiede un ulteriore approccio. End-to-end può essere inteso come VA senza il linguaggio. Il linguaggio corrisponde al pensiero e alla comprensione. Abbiamo incorporato questa componente nella VLA, unificando il paradigma della robotica e rendendo la guida autonoma una categoria della robotica. Questa rappresenta un'innovazione algoritmica, non solo ingegneristica.
Una delle principali sfide per la guida autonoma è l'innovazione ingegneristica. Il VLA è un modello di grandi dimensioni e implementarlo su piattaforme di edge computing è estremamente impegnativo. Molti team non pensano necessariamente che il VLA sia una cattiva idea, ma piuttosto che la sua implementazione sia difficile. Metterlo in pratica è incredibilmente impegnativo, soprattutto quando i chip edge non dispongono di sufficiente potenza di calcolo. Pertanto, dobbiamo implementarlo su chip ad alta potenza di calcolo. Non si tratta solo di innovazione ingegneristica, ma richiede un'ampia ottimizzazione dell'implementazione ingegneristica per raggiungere il successo.
D: Quando si implementano modelli VLA di grandi dimensioni a bordo, si verificherà un processo di potatura o distillazione del modello? Come possiamo trovare un equilibrio tra efficienza di inferenza e prestazioni del modello?
Zhan Kun: Abbiamo trovato un attento equilibrio tra efficienza e distillazione durante l'implementazione. Il nostro modello base è un modello proprietario 8×0,4B MoE (Mixture of Experts), unico nel settore. Dopo un'analisi approfondita dei chip NVIDIA, abbiamo scoperto che questa architettura è perfetta. Offre un'elevata velocità di inferenza e un'ampia capacità di modellazione, consentendo di gestire modelli di grandi dimensioni con scenari e funzionalità diversificate. Questa è stata la nostra scelta architettonica.
Inoltre, abbiamo distillato un modello di grandi dimensioni. Inizialmente abbiamo addestrato un modello basato su cloud da 32 miliardi di dollari, che contiene una vasta quantità di conoscenze e capacità di guida. Abbiamo distillato i suoi processi di pensiero e ragionamento in un modello MoE da 3,2 miliardi di dollari e utilizzato la tecnologia Diffusion in combinazione con Vision and Action (un modello di diffusione in grado di generare immagini, video, audio, traiettorie di movimento e altri dati. Nello specifico, nello scenario VLA ideale, la tecnologia Diffusion viene utilizzata per generare traiettorie di guida).
Abbiamo apportato numerose ottimizzazioni utilizzando questo approccio. In particolare, abbiamo implementato anche ottimizzazioni ingegneristiche per Diffusion. Invece di utilizzare semplicemente Diffusion standard, abbiamo implementato la compressione dell'inferenza, che può essere considerata una forma di distillazione. In precedenza, Diffusion avrebbe potuto richiedere 10 passaggi di inferenza, ma utilizzando il flow matching ne sono necessari solo due. Questa compressione è la ragione fondamentale per cui siamo stati in grado di implementare VLA.

D: VLA è una soluzione adeguata? Quanto tempo ci vorrà per raggiungere il cosiddetto "momento GPT"?
Zhan Kun: Quando in precedenza si affermava che il modello multimodale non aveva raggiunto il momento GPT, ci si riferiva probabilmente all'intelligenza artificiale fisica come il VLA, piuttosto che al VLM. In effetti, il VLM ora soddisfa pienamente uno standard molto innovativo di "momento GPT". Se ci concentriamo sull'intelligenza artificiale fisica, l'attuale VLA, soprattutto nei campi della robotica e dell'intelligenza incarnata, potrebbe non aver raggiunto lo standard di "momento GPT" perché non ha capacità di generalizzazione altrettanto buone.
Tuttavia, nel campo della guida autonoma, il VLA risolve effettivamente un paradigma di guida relativamente unificato, e in questo modo esiste la possibilità di raggiungere un "momento GPT". Siamo anche pienamente consapevoli che l'attuale VLA è la prima versione, e la prima ad essere spinta alla produzione di massa nel settore, quindi ci saranno sicuramente dei difetti.
Questo importante tentativo consiste nell'utilizzare la tecnologia VLA per esplorare una nuova strada. Contiene molte aree da esplorare e molti punti di esplorazione da implementare. Ciò non significa che se non riusciamo a raggiungere il "momento GPT", non possiamo avviare la produzione di massa. Ci sono molti dettagli da considerare, tra cui la nostra valutazione e simulazione, per verificare se può essere implementato in produzione di massa e se può offrire agli utenti un'esperienza "migliore, più confortevole e più sicura". Se i tre punti sopra menzionati saranno raggiunti, potremo offrire agli utenti un'esperienza di consegna migliore.
I "momenti GPT" si riferiscono più a una forte versatilità e generalizzazione. In questo processo, man mano che estendiamo la guida autonoma ai robot spaziali o ad altri campi di applicazione, potremmo sviluppare capacità di generalizzazione più forti o capacità di coordinamento più complete. Dopo l'implementazione, passeremo gradualmente ai momenti ChatGPT man mano che "i dati degli utenti si iterano, gli scenari diventano più ricchi, il pensiero diventa più logico e le interazioni vocali diventano più frequenti".
Come ha affermato il Dott. Lang Bo (Dott. Lang Xianpeng), se raggiungeremo 1000 MPI entro il prossimo anno, potremmo dare agli utenti la sensazione che abbiamo davvero raggiunto un "momento GPT" per VLA.
#Benvenuti a seguire l'account pubblico ufficiale WeChat di iFaner: iFaner (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
