
Fare un video con la tua bocca sta davvero arrivando! Questa nuova app, Meta, è terrificante
Quest’anno è un anno di grandi progressi per l’IA nel campo della produzione di immagini e video.
Qualcuno ha vinto il premio per l’arte digitale con un’immagine generata dall’IA e ha sconfitto un gruppo di artisti umani; ci sono applicazioni come Tiktok che generano immagini attraverso l’input di testo e le trasformano nello sfondo del green screen di brevi video; ci sono nuovi prodotti che possono fai testo Genera video direttamente e realizza direttamente l’effetto di “fai video con la tua bocca”.
Il prodotto questa volta proviene da Meta, che ha coltivato profondamente l’intelligenza artificiale per molti anni, ed è stato follemente ridicolizzato a causa del metaverso qualche tempo fa.

▲ Il Meta Metaverse è stato ridicolizzato selvaggiamente
Solo che questa volta non puoi prenderlo in giro, perché ha davvero una piccola svolta.
Testo in video, cosa si può fare
Ora puoi muovere la bocca per fare un video.
Anche se questo è un po’ esagerato, il Make-A-Video di Meta questa volta probabilmente si sta davvero muovendo verso questo obiettivo.

Ciò che Make-A-Video può fare attualmente è:
- Text-to-video: trasforma la tua immaginazione in video reali e unici
- Converti le immagini direttamente in video: lascia che una o due immagini si muovano naturalmente
- Video esteso per la generazione di video: inserisci un video per creare una variante video
In termini di generazione diretta di video dal testo, Make-A-Video ha sconfitto molti studenti professionisti di design di animazione. Almeno può fare qualsiasi stile e il costo di produzione è molto basso.
Sebbene il sito Web ufficiale non ti consenta di generare direttamente un’esperienza video, puoi prima inviare le tue informazioni personali, quindi Make-A-Video condividerà prima eventuali sviluppi con te.

Non ci sono molti casi che possono essere visti finora e i casi mostrati sul sito ufficiale hanno ancora dei punti strani nei dettagli. Tuttavia, il fatto che il testo possa essere trasformato direttamente in video è di per sé un miglioramento.
Un orsacchiotto sta disegnando un autoritratto e puoi vedere la proiezione innaturale della mano dell’orso sulla parte in ombra del foglio.

I robot ballano a Times Square.

Il gatto tiene in mano il telecomando della TV per cambiare canale.Gli artigli del gatto sono molto simili alle mani umane ea volte fa un po’ paura a guardarlo.

E un bradipo peloso con un cappello di maglia arancione giocherella con un laptop, la luce dello schermo del computer negli occhi.

Quanto sopra sono stili surreali e le custodie più simili alla realtà sono più facili da indossare.
I casi mostrati da Make-A-Video sono buoni se si concentrano solo su aree locali, come il primo piano dell’artista che dipinge sulla tela, il cavallo che beve l’acqua e il piccolo pesce che nuota nella barriera corallina.



Ma una giovane coppia leggermente più realistica che cammina sotto la pioggia battente è molto strana: la parte superiore del corpo va bene, ma i piedi della parte inferiore del corpo tremolano, a volte allungati, come in un film di fantasmi.

Ci sono anche video in stile pittorico di astronavi che atterrano su Marte, coppie in smoking intrappolate negli acquazzoni, luce solare sui tavoli e bambole panda in movimento. In termini di dettagli, questi video non sono perfetti, ma solo per l’effetto innovativo del text-to-video AI, sono comunque sorprendenti.




I dipinti statici possono anche essere animati con l’aiuto di Make-A-Video: la barca si muove tra le grandi onde.

Le tartarughe nuotano nel mare L’immagine iniziale è molto naturale, ma in seguito diventa più simile a un ritaglio di uno schermo verde, il che è innaturale.
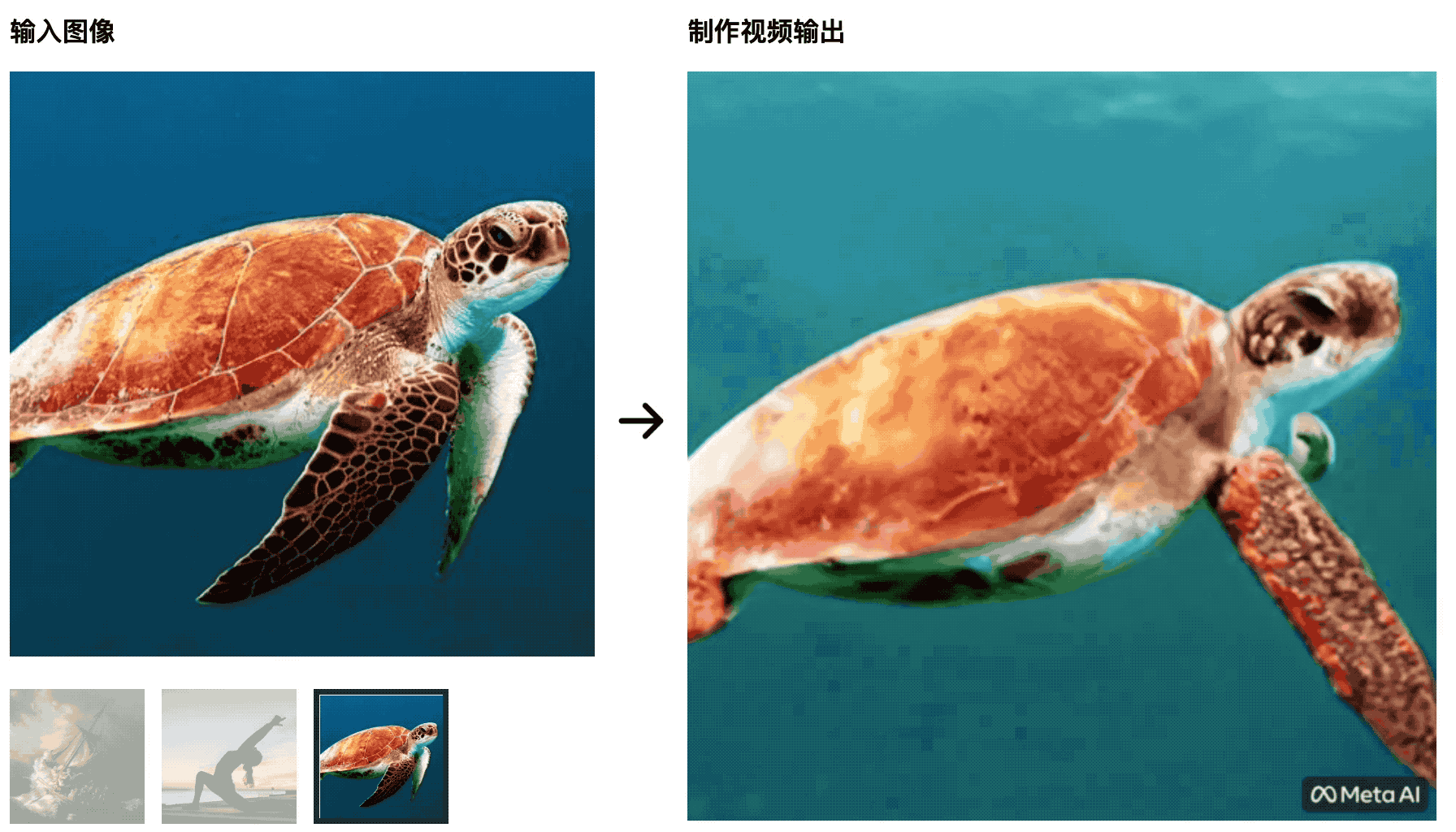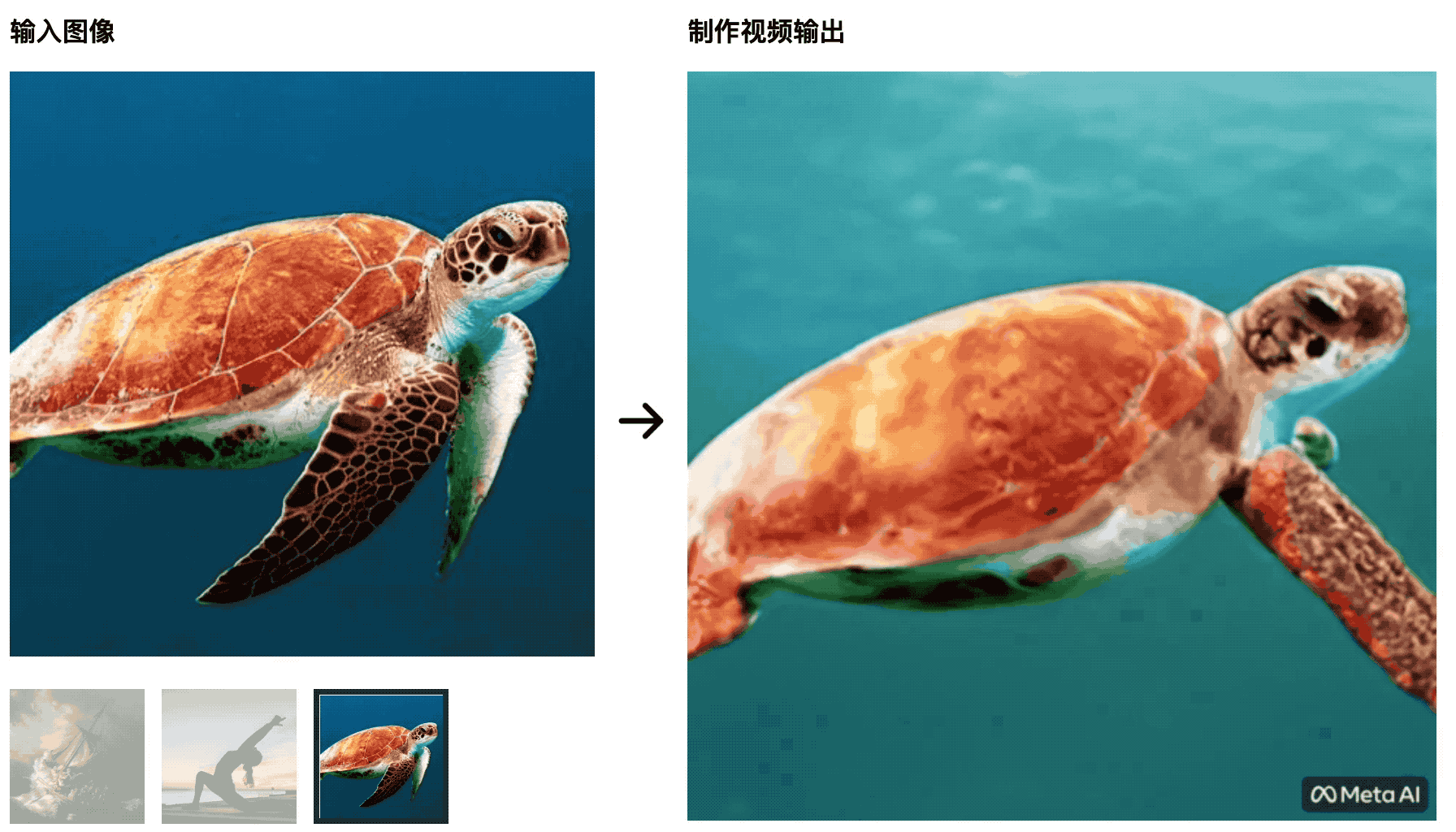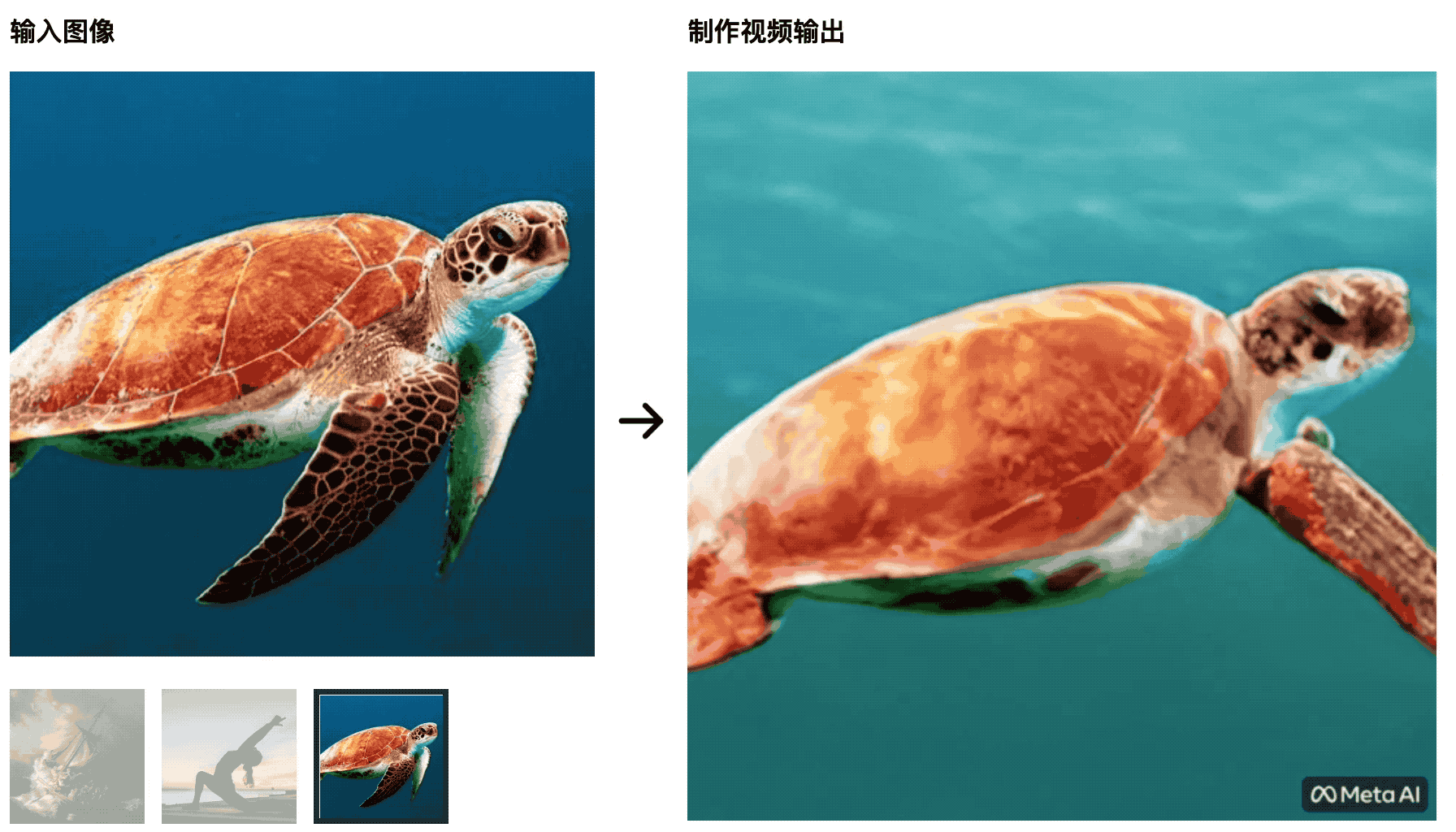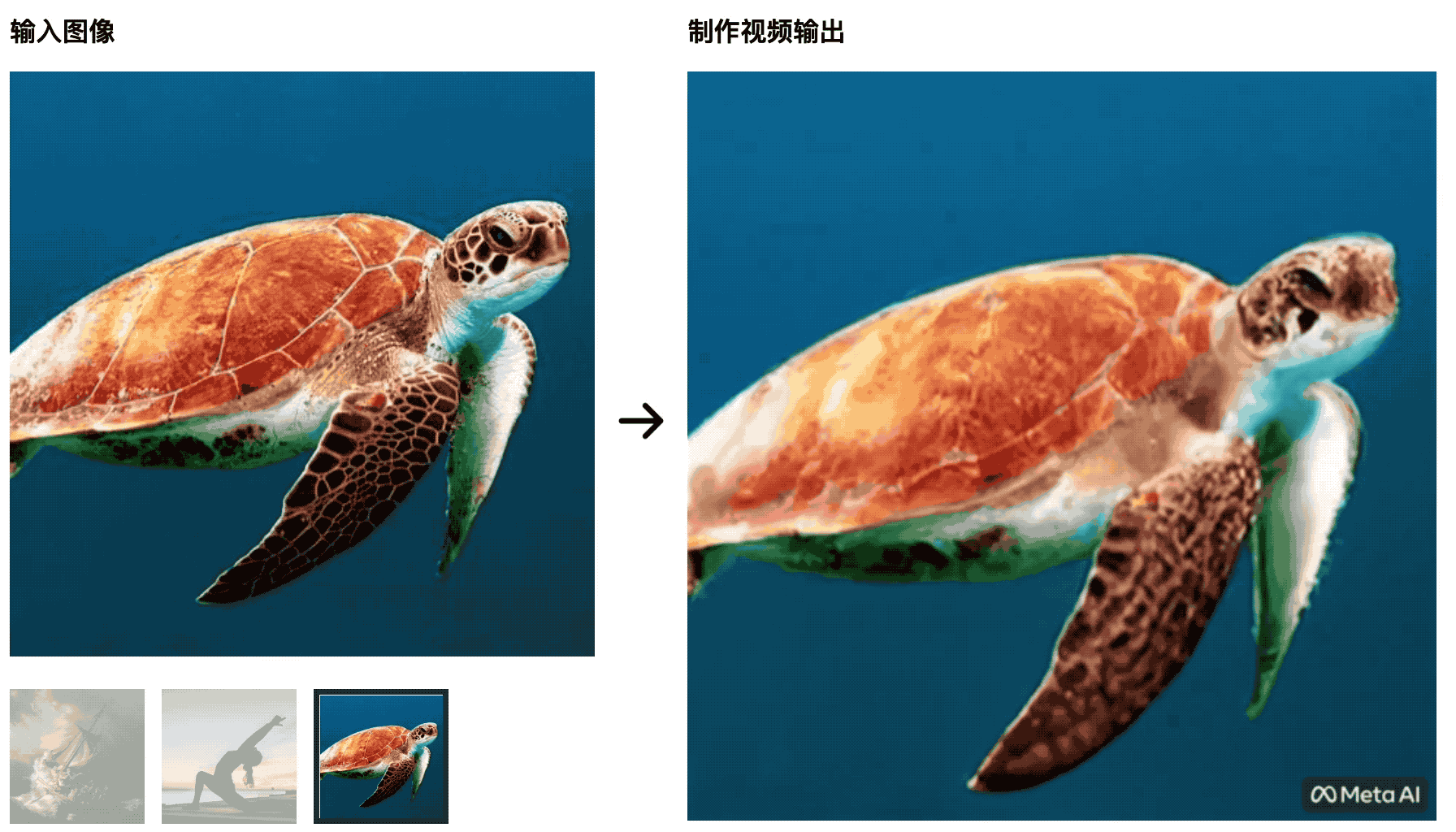
L’istruttore di yoga allunga il suo corpo al sole nascente e il tappetino da yoga cambierà con le modifiche del video: questa IA non sarà in grado di sconfiggere gli studenti che studiano la produzione cinematografica e televisiva e le variabili di controllo non sono ben fatte.

Infine inserisci un video per imitarne lo stile per creare varianti video Ci sono anche 3 casi.
Uno dei cambiamenti è relativamente meno raffinato. Il video degli astronauti che svolazzano nello spazio è stato trasformato in una versione leggermente meno estetica di 4 versioni approssimative del video.

Ci sono alcuni cambiamenti sorprendenti nel video dell’orsetto che balla, almeno la postura della danza è cambiata.

Per quanto riguarda l’ultimo video del coniglio che mangia l’erba, è il più “anneng mi distingue come maschio e femmina”. È difficile riconoscere chi è il video iniziale negli ultimi 5 video e sembra molto armonioso.

Non appena il testo per le immagini è progredito, il video è qui
In ” Dopo AlphaGo, sovverte di nuovo completamente la cognizione umana “, una volta abbiamo introdotto l’applicazione per la generazione di immagini DALL·E. Qualcuno l’ha usato per creare immagini per competere con artisti umani e alla fine vincere.
Si può dire che il Make-A-Video che vediamo ora sia una versione video di DALL·E (versione primaria) – è come il DALL·E di 18 mesi fa, con un enorme passo avanti, ma l’effetto attuale potrebbe non le persone sono soddisfatte.

▲ Pittura estesa realizzata da DALL·E
Si può anche dire che è un prodotto che si erge sulle spalle del gigante DALL·E e fa risultati. Rispetto alle immagini generate dal testo, Make-A-Video non ha apportato troppe nuove modifiche al back-end.
“Abbiamo visto che i modelli che descrivono le immagini generate dal testo erano anche sorprendentemente efficaci nel generare brevi video”, hanno affermato i ricercatori nel loro articolo.

▲ Opere pluripremiate che descrivono immagini generate da testo
Al momento, i video prodotti da Make-A-Video hanno 3 vantaggi:
- Addestramento accelerato dei modelli T2V (da testo a video)
- Non c’è bisogno di dati da testo a video accoppiati
- Il video convertito eredita lo stile dell’immagine/video originale
Queste immagini hanno certamente degli inconvenienti e la suddetta innaturalità è tutta reale. E non sono come i video nati in questa era, la qualità dell’immagine è sfocata, il movimento è rigido, la corrispondenza del suono non è supportata, la durata di un video non supera i 5 secondi e la risoluzione è 64 x 64px.

▲ Questo video ha alcuni fotogrammi della lingua e delle mani del cane che sono molto strani
Anche il primo modello CogVideo in grado di sintetizzare video dal testo, pubblicato pochi mesi fa da un gruppo di ricerca dell’Università di Tsinghua e dell’Istituto di ricerca Zhiyuan (BAAI), presenta un problema del genere. Basato sull’architettura Transformer pre-addestrata su larga scala, propone una strategia di formazione gerarchica multi-frame rate, in grado di allineare in modo efficiente clip di testo e video, ma non può sopportare il controllo.
Ma chi può dire che 18 mesi dopo, Make-A-Video e CogVideo non realizzeranno video migliori della maggior parte?

▲ Video generato da CogVideo: attualmente supporta solo la generazione cinese
Sebbene non siano stati rilasciati molti strumenti di conversione da testo a video, ce ne sono molti in arrivo. Dopo il rilascio di Make-A-Video, gli sviluppatori della start-up StabilityAI hanno dichiarato pubblicamente: “La nostra (applicazione da testo a video) sarà più veloce, migliore e applicabile a più persone”.
La concorrenza è migliore e la funzione di conversione da testo a immagine, sempre più realistica, ne è la prova migliore.
#Benvenuto a prestare attenzione all’account WeChat ufficiale di Aifaner: Aifaner (WeChat: ifanr), contenuti più interessanti ti verranno forniti il prima possibile.
Love Faner | Link originale · Visualizza commenti · Sina Weibo
