
La controversia sulla “distillazione” che ha paralizzato Anthropic è stata accolta con un commento serio da un importante esperto statunitense di intelligenza artificiale: il successo della Cina nel campo dell’intelligenza artificiale non si baserà su scorciatoie.

Ieri, Anthropic ha criticato tre laboratori di intelligenza artificiale cinesi (DeepSeek, Dark Side of the Moon e MiniMax) per aver "distillato" il modello di Claude, scatenando un putiferio online.
Riguardo a questo incidente, Nathan Lambert, uno dei più rinomati ricercatori nel campo dell'RLHF (Reinforcement Learning Based on Human Feedback) e autore del libro "RLHF", ha sottolineato che la questione non è così grave come si immagina, ma non è nemmeno così semplice come sembra.
Egli ritiene che le aziende cinesi di intelligenza artificiale dispongano di infrastrutture eccellenti, abbiano introdotto numerose innovazioni e stiano affrontando diverse sfide tecniche, ma che abbiano raggiunto questi risultati non "prendendo scorciatoie".
Prima di parlare della distillazione, vediamo perché vale la pena ascoltare le parole di Lambert.
Nathan Lambert è uno scienziato presso l'Allen Institute for AI Research. Ha conseguito il dottorato di ricerca presso l'Università della California, Berkeley, dove ha studiato con Pieter Abbeel, un rinomato studioso nel campo della robotica. Sebbene non sia l'inventore della tecnologia RLHF, il suo libro open source, *RLHF*, è ora uno dei materiali di riferimento standard per i professionisti dell'intelligenza artificiale che desiderano comprendere il processo di addestramento di modelli di grandi dimensioni.
A differenza degli influencer dell'intelligenza artificiale che sono ovunque, lui è qualcuno che ha effettivamente addestrato grandi modelli.
Lo stesso giorno in cui è stato pubblicato il post sul blog di Anthropic, Lambert ha pubblicato un articolo di analisi dettagliata intitolato "Quanto è importante la distillazione per il modello di grandi dimensioni della Cina?". Le sue argomentazioni principali differivano significativamente dall'interpretazione dei media tradizionali ed erano più perspicaci e complete di quelle dell'utente medio di Internet.
Cos'è la distillazione e cosa ha detto Anthropic?
Innanzitutto, diamo un'occhiata al nocciolo dell'accusa di Anthropic: la "distillazione".
Si riferisce alla capacità di consentire a un modello debole di apprendere dall'output di un modello forte, acquisendo così rapidamente capacità simili.
Anthropic sostiene che le tre aziende hanno utilizzato circa 24.000 account falsi per generare oltre 16 milioni di conversazioni con Claude, violando i termini di servizio e le restrizioni di accesso regionali, per addestrare i rispettivi modelli.
Il blog includeva anche un avviso di sicurezza: i modelli creati illegalmente potrebbero non avere le stesse misure di sicurezza del modello originale e le conseguenze sarebbero imprevedibili se utilizzati per attacchi informatici, sviluppo di armi biologiche o sorveglianza su larga scala.
Anthropic chiama questa infrastruttura "cluster Hydra": una rete distribuita di decine di migliaia di account, con traffico distribuito simultaneamente tra l'API di Anthropic e diverse piattaforme di aggregazione API di terze parti.
Nei casi più estremi, una rete proxy gestisce contemporaneamente oltre 20.000 account falsi, mescolando il traffico distillato con i normali flussi di richieste degli utenti per eludere gli algoritmi di rilevamento. Tali reti non hanno un singolo punto di errore: se un account viene bloccato, un altro viene immediatamente sostituito.
I media stranieri hanno subito replicato, ribadendo la retorica di Anthropic. Tuttavia, questa logica narrativa si è presto ritorta contro di loro: dopotutto, la "distillazione" è un'attività che anche le aziende americane di intelligenza artificiale praticano durante l'addestramento, e la stessa Anthropic ha adottato pratiche simili.
E: Anthropic ha "distillato" la più grande base di conoscenza dell'umanità.
Ma Lambert era più equilibrato e riteneva che questi tre laboratori di intelligenza artificiale cinesi dovessero essere esaminati separatamente per primi.
Lambert sottolinea che la giustapposizione di queste tre aziende nello stesso post del blog da parte di Anthropic nasconde una differenza fondamentale: non stanno facendo la stessa cosa, hanno dimensioni molto diverse e motivazioni diverse.
Secondo le accuse di Anthropic, DeepSeek esegue il minor numero di distillazioni, solo 150.000, ma i suoi metodi sono più precisi. Invece di raccogliere direttamente le risposte, Anthropic sostiene che DeepSeek stia producendo in serie dati di addestramento per la catena di pensiero.
Ciò che conta non è "a quali conclusioni si è giunti", ma il processo per giungere a tali conclusioni.
Ma che tipo di scala è 150.000 volte? Lambert ritiene che questa quantità di dati abbia un impatto trascurabile sul presunto modello V4 di DeepSeek o sull'addestramento complessivo di qualsiasi modello. "È più come un piccolo team che conduce un esperimento interno, e molto probabilmente nemmeno la persona responsabile dell'addestramento ne è a conoscenza."

La portata di Moonlight's Darkness non è "trascurabile": 3,4 milioni di interazioni, mirate ad aree quali il ragionamento degli agenti, le chiamate degli strumenti, l'analisi di codice e dati, lo sviluppo dell'uso del computer e la visione artificiale, molte delle quali sono le combinazioni di capacità di Claude più popolari di recente tra i clienti aziendali.
Anthropic sottolinea che MiniMax ha il traffico più elevato tra i tre, con circa 13 milioni di visite, e il suo pubblico di riferimento è la codifica proxy, le chiamate di strumenti e l'orchestrazione di attività complesse.
Il totale combinato di Moonlight e MiniMax è di circa 16,5 milioni di volte. In base all'importo medio di token per conversazione, si stima che l'importo totale sia compreso tra 150 e 400 miliardi di token, il che si traduce in un costo per token compreso tra diverse centinaia e decine di milioni di dollari USA.
Tuttavia, il problema è che concentrarsi esclusivamente sulla distillazione è problematico.
Dov'è il limite massimo del processo di distillazione?
Questo è ciò che Lambert voleva realmente dire, ed è anche la parte più trascurata dell'intera faccenda.
Fornire l'output di un modello forte a un modello debole, consentendo al modello debole di acquisire rapidamente capacità simili: questa logica è di per sé vera, e Lambert non la nega. Tuttavia, sottolinea un problema che nessuno ha definito chiaramente: il limite massimo di distillazione dipende dal tipo di capacità desiderata.
In qualità di esperto di RLHF, Lambert ritiene che l'attuale addestramento basato su modelli all'avanguardia si basi in larga misura sull'apprendimento per rinforzo (RL). Tuttavia, RL e distillazione sono fondamentalmente due cose diverse:
La distillazione è imitazione, apprendimento dell'output di un modello forte e copia della sua "forma di risposta"; la RL è esplorazione, in cui il modello deve ragionare ampiamente da solo, generare i propri dati, ripetere ripetutamente gli errori e perfezionare le proprie capacità attraverso tentativi ed errori.
In altre parole, un modello veramente potente non ha mai bisogno solo della risposta corretta, ma spesso deve trovare autonomamente il percorso risolutivo. Questo è qualcosa che non si può ottenere distillando l'output delle API di altri.

Prendiamo come esempio il tentativo di distillazione di DeepSeek: il piccolo modello DeepSeek-R1-Distill-Qwen 1.5B, ottenuto distillando il proprio modello R1 basato sul vicino Qianwen, ha superato o1-preview di OpenAI nel benchmark della competizione matematica AIME24 con soli 7.000 campioni e un costo computazionale estremamente basso.
Ma il punto chiave è che questo miglioramento si basa in larga misura sui risultati dell'apprendimento per rinforzo, piuttosto che sul processo di distillazione in sé.
In altre parole, la distillazione può aiutarti a "riscaldarti" più velocemente, ma per raggiungere davvero il livello più alto, devi comunque affidarti alla gestione della vita reale.
Differenze nella distribuzione dei dati tra diversi modelli
Lambert ha anche sottolineato un problema tecnico che viene raramente menzionato dagli esterni: esistono sottili differenze nella distribuzione dei dati tra i diversi modelli.
Alimentare l'output di Claude direttamente con un modello di un'altra architettura non è necessariamente efficace e a volte può persino causare interferenze. La differenza negli spazi di rappresentazione interni dei due modelli può far sì che la risposta dell'"insegnante" determini distorsioni inaspettate nella risposta dello "studente".
Ciò significa che la distillazione non è mai qualcosa che può essere "utilizzato così com'è", ma richiede piuttosto un notevole lavoro ingegneristico per essere veramente efficace. Questo di per sé è un argomento di ricerca.
Ecco perché Lambert considera la presunta "distillazione" di Anthropic un approccio innovativo, che può essere interpretato come uno sforzo per affrontare questo argomento di ricerca.

La caratteristica più importante di Anthropic è proprio quella più difficile da sintetizzare.
Le tre aziende citate da Anthropic si sono tutte concentrate sulla stessa area: il comportamento dell'agenzia, inclusa la capacità dell'intelligenza artificiale di pianificare autonomamente, richiamare strumenti e scomporre attività complesse per un'esecuzione graduale.
Questa è la direzione più importante intrapresa da Claude al momento, ed è anche la capacità che Anthropic desidera meno che venga copiata.
Ma Lambert ritenne che proprio queste capacità fossero le più difficili da ottenere tramite distillazione.
Come accennato in precedenza, la forza di un potente agente di intelligenza artificiale non risiede nel conoscere o nell'essere addestrato a fornire la risposta corretta, ma nell'"essere in grado di esplorare autonomamente soluzioni quando ci si trova di fronte a situazioni inaspettate", il che può essere inteso come la capacità di ottenere risultati allo stato dell'arte (SOTA) con capacità di 0 o pochi colpi.
Il valore generato in questo processo si riflette nel percorso di ragionamento, che è difficile da apprendere tramite distillazione, almeno per ora.
Il divario tra DeepSeek-R1-Distill (il modello di distillazione) e DeepSeek-R1 (l'oggetto di distillazione) è l'esempio più diretto dell'argomentazione di Lambert.
Il primo funziona bene nei compiti di ragionamento matematico formattati; tuttavia, il divario tra i due è reale nei compiti proxy complessi che richiedono esplorazione autonoma e programmazione dinamica.

Perché Anthropic si esprime ora?
Lambert ha espresso un giudizio che molti potrebbero condividere: questa volta la decisione di Anthropic di citare pubblicamente le aziende cinesi di intelligenza artificiale non è stata motivata principalmente da una "difesa tecnica".
Pochi giorni prima che Anthropic pubblicasse questo post sul blog, il Dipartimento della Difesa degli Stati Uniti aveva minacciato Anthropic di collaborare fornendo "accesso illimitato" o di affrontare accordi sfavorevoli, come l'etichettatura come "pericolo per la catena di approvvigionamento", il che significava che sarebbe stata esclusa dall'elenco dei fornitori della difesa/governo.
Anthropic si trova ora di fronte a un dilemma: vuole mantenere il suo posizionamento di modello sicuro e umano e la sua immagine aziendale, ma non vuole nemmeno lasciarsi sfuggire un importante contratto con il governo degli Stati Uniti.
Lambert sottolinea una contraddizione fondamentale: anche il mondo accademico americano e gli sviluppatori di modelli open source stanno praticando la distillazione, eppure le principali aziende, tra cui Anthropic, non hanno intrapreso alcuna azione sostanziale nei loro confronti. Affermare che ciò sia dovuto esclusivamente al fatto che la controparte è un'azienda cinese sembra eccessivamente geopolitico.
Di conseguenza, il post sul blog di Anthropic era più simile a un "giuramento di fedeltà" che a un resoconto di un importante evento di rischio tecnico.

Doppi standard
La posizione di Anthropic su questa questione ha un fondamento inevitabile.
Come menzionato nell'articolo di ieri di APPSO: Anthropic ha "distillato" la più grande base di conoscenza nella storia dell'umanità.
All'inizio del 2024, in un magazzino negli Stati Uniti, gli operai inserirono nuovi libri nelle macchine, ne tagliarono il dorso, li scansionarono e poi inviarono la carta al riciclo. Questo compito fu commissionato da Anthropic, nome in codice interno "Panama", il cui obiettivo era quello di scansionare in modo distruttivo tutti i libri del mondo: Anthropic non voleva che il mondo esterno sapesse di averlo fatto.
Nel 2021, il co-fondatore di Anthropic, Ben Mann, ha scaricato un gran numero di libri illeciti dal sito web anti-pirateria LibGen in 11 giorni; l'anno successivo è stato lanciato un altro sito web, Pirate Library Mirror, che affermava apertamente di "violare deliberatamente le leggi sul copyright nella maggior parte dei paesi". Mann ha inviato il link a un collega e ha commentato: "Tempismo perfetto!!!"
Nelle successive cause legali sui diritti d'autore dei libri, Anthropic è stata costretta a pagare un risarcimento di 1,5 miliardi di dollari, pari a circa 3.000 dollari a libro.
I ricercatori di Stanford e Yale hanno scoperto che Claude 3.7 Sonnet può riprodurre opere protette da copyright come Harry Potter con una precisione del 95,8% in determinate condizioni, quasi parola per parola. Questo non solo contraddice la consolidata affermazione di Anthropic secondo cui "il modello apprende semplicemente le regole del linguaggio", ma fa anche sembrare infondate le accuse di "distillazione" mosse dall'azienda nei confronti di chiunque.
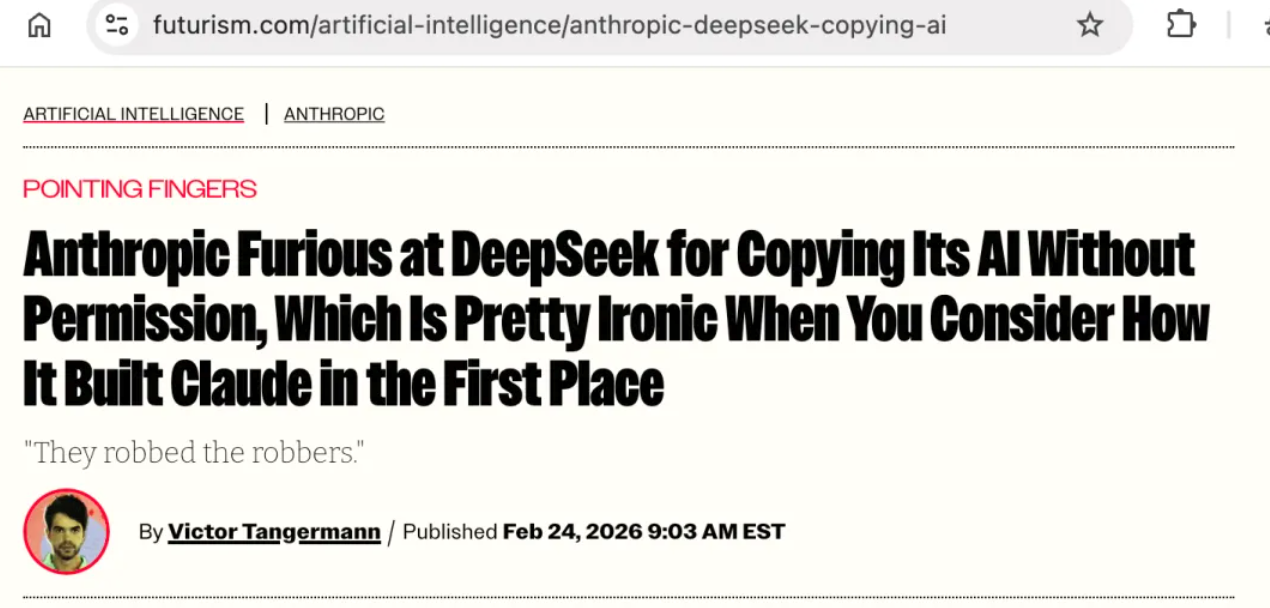
Il titolo di Futurism è diretto: "Anthropic si infuria per la copia non autorizzata dell'intelligenza artificiale da parte di DeepSeek, il che è piuttosto ironico se si considera il modo in cui ha creato Claude".
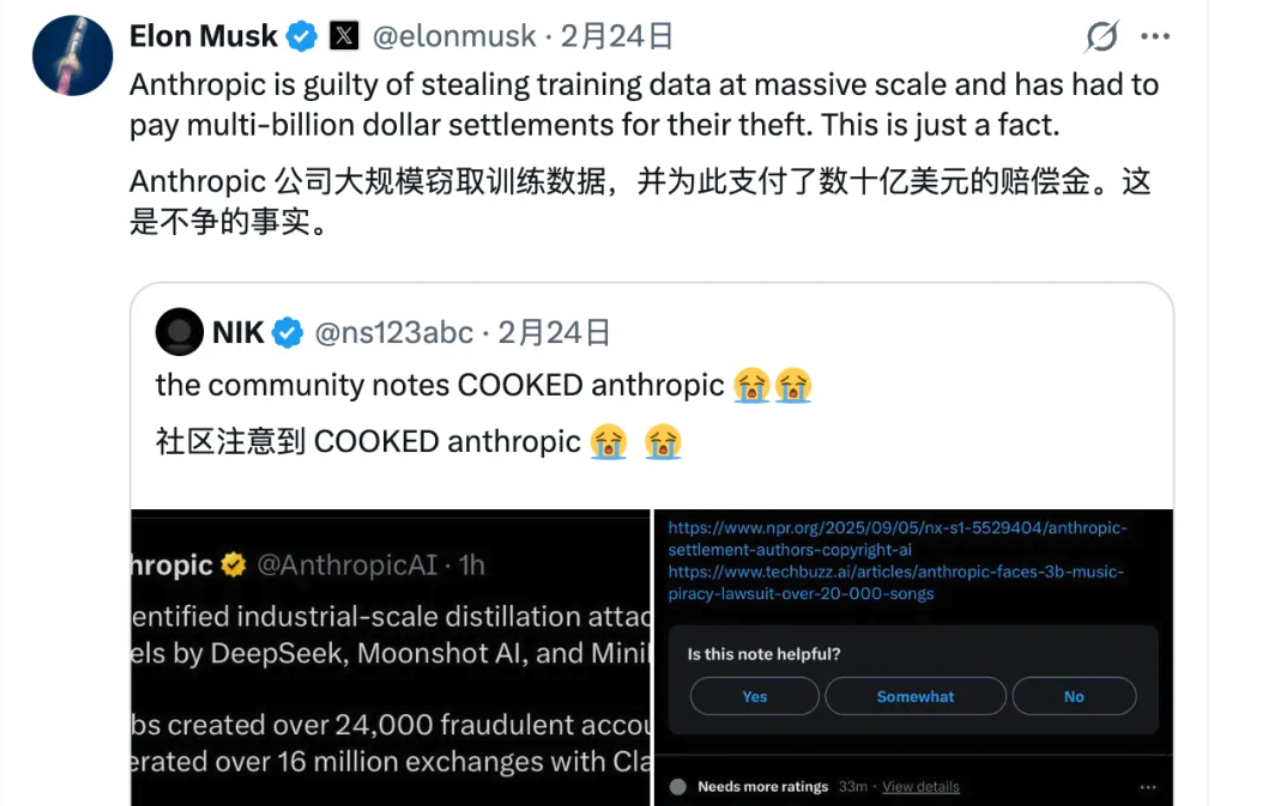
Musk ha gettato benzina sul fuoco con i suoi commenti sulla X: "Anthropic ha rubato dati di addestramento su larga scala e ha pagato miliardi di dollari in risarcimenti. Questo è un dato di fatto."
La controargomentazione ha un punto ancora più incisivo: Anthropic ha preso ciò che ha preso da quei libri senza pagare alcuna quota di utilizzo, e poi lo ha utilizzato per scopi commerciali (sia Claude che l'API di Anthropic sono servizi a pagamento); mentre da una prospettiva aziendale, l'azienda che ha distillato Claude almeno lo ha pagato…
Naturalmente, da un punto di vista giuridico, si tratta di due questioni di natura completamente diversa. Ma in ogni caso, Anthropic sembra ancora un ipocrita doppio standard.
"L'era post-distillazione"
Infine, vorrei sottolinearlo ancora una volta: la distillazione è utile, ma non così utile come si potrebbe immaginare.
Le 150.000 scansioni di DeepSeek sono trascurabili secondo qualsiasi standard ragionevole. Moonshot e MiniMax insieme ne hanno effettuate 16,5 milioni, il che è un'altra questione in termini di scala, ma la reale capacità in cui potranno tradursi dipenderà dalla loro capacità di risolvere il problema tecnico di "come sfruttare al meglio questi dati".
Date le differenze nella distribuzione dei dati, nell'architettura del modello e il fatto che l'acquisizione delle capacità degli agenti dipende fortemente dall'apprendimento per rinforzo, la distillazione non è mai così semplice come "prendere e usare".
Lambert ha comunque dato un po' di lustro ad Anthropic: "L'iterazione rapida combinata con dati di alta qualità può portare molto lontano e non è impossibile che il modello dello studente superi quello dell'insegnante".

Tuttavia, ha anche chiaramente sottolineato che la vera innovazione si basa sull'apprendimento per rinforzo, non sulla distillazione. A giudicare dagli articoli pubblicati su DeepSeek, Moonlight e MiniMax, tutti dispongono di un'infrastruttura piuttosto completa e di talenti eccellenti, ben lungi dall'essere "piccole officine" che cercano di superare gli altri affidandosi a trucchi intelligenti.
La distillazione può aiutarti a partire più velocemente, ma non esistono scorciatoie per raggiungere il livello più alto.
In un certo senso, la controversia sulla "distillazione" sollevata da Anthropic è di per sé un microcosmo di questa era dell'intelligenza artificiale.
Fin dall'inizio, l'intero settore si è basato su regole ambigue: esercitarsi con cose scritte da esseri umani, iterare con i risultati open source di altre persone e agire rapidamente laddove la legge non lo proibisce esplicitamente.
Ora le regole stanno iniziando a inasprirsi: prima il copyright, poi i chip e ora le API… Chi stabilisce le regole? Chi ne trae vantaggio? Chi abusa delle regole per tornaconto personale, pur sostenendo di essere umano?
Le risposte a queste domande stanno diventando sempre più chiare.
#Benvenuti a seguire l'account WeChat ufficiale di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
