
Anthropic ha “distillato” la più grande base di conoscenza dell’umanità.

All'inizio del 2024, in un magazzino da qualche parte negli Stati Uniti, gli operai stavano facendo qualcosa di piuttosto strano: inserirono i libri uno alla volta in una macchina, ne tagliavano il dorso, li scannerizzavano e poi inviavano la carta rimanente al riciclaggio.
Questi libri sono stati appena acquistati, alcuni addirittura nuovi di zecca. Nessuno li leggerà; il loro unico scopo è quello di essere distrutti.
L'azienda che ha ordinato questo era un'azienda di intelligenza artificiale chiamata Anthropic.

Nei documenti interni, il progetto era denominato in codice "Progetto Panama". Un documento di pianificazione affermava senza mezzi termini: "Questo è il nostro piano per scansionare in modo distruttivo tutti i libri del mondo e non vogliamo che il mondo esterno sappia che lo stiamo facendo".
Alla fine la gente lo ha scoperto.
L'anno scorso, un giudice federale ha desecretato una serie di documenti relativi a una causa per violazione del copyright, per un totale di oltre 4.000 pagine. Ciò che il mondo esterno ha visto non sono stati solo i segreti di un'azienda, ma il vero volto dell'intero settore dell'intelligenza artificiale nella sua guerra dei dati.
Libri fisici "mangiati" dai grandi modelli
Perché questi giganti della tecnologia all'avanguardia trattano i libri stampati in modo così primitivo e persino brutale? La risposta sta nell'estrema sete di dati di alta qualità dell'intelligenza artificiale.
Anthropic si rese conto fin da subito che i soli contenuti online non erano sufficienti per addestrare i modelli di intelligenza artificiale.
Secondo il Washington Post, uno dei fondatori di Anthropic ha scritto in un documento del gennaio 2023 che i modelli di addestramento con i libri potrebbero insegnare all'intelligenza artificiale "come scrivere meglio" invece di limitarsi a imitare il linguaggio incoerente online.
Il libro è stato sottoposto a un rigoroso lavoro di editing e correzione di bozze, e la sua struttura dei contenuti è chiara. Si tratta di un corpus di alta qualità, difficile da sostituire con testi online.
La logica in sé non è difficile da comprendere, ma il problema è: se il valore dei libri è riconosciuto, perché non pagarli? Il motivo è che negoziare le licenze individualmente con editori e autori è dispendioso in termini di tempo, lavoro e denaro. Per questo motivo, Anthropic ha lanciato il "Progetto Panama". L'affermazione "Non vogliamo che il mondo esterno lo sappia" indica che l'azienda sa anche che questa argomentazione è insostenibile.
Ancor prima del lancio del "Progetto Panama", Anthropic aveva già provato ad acquisire libri attraverso un altro metodo.

I documenti del tribunale mostrano che il co-fondatore dell'azienda, Ben Mann, ha scaricato un gran numero di romanzi e libri di saggistica da un sito web chiamato LibGen nell'arco di 11 giorni nel giugno 2021. LibGen è una "biblioteca ombra" in cui la maggior parte delle risorse è sospettata di violazione del copyright. Gli screenshot del browser allegati ai documenti mostrano che ha utilizzato un software di condivisione file per completare questi download.
Un anno dopo, nel luglio 2022, è stato lanciato un altro sito web, Pirate Library Mirror, che dichiarava apertamente di "violare deliberatamente le leggi sul copyright nella maggior parte dei paesi". Mann ha inviato il link a questo sito web ad altri dipendenti di Anthropic, commentando: "Tempismo perfetto!!!"
Dietro quel punto esclamativo si nasconde il vero atteggiamento di un dirigente aziendale nei confronti di un sito web pirata che ammette apertamente di violare la legge.
Anthropic ha successivamente dichiarato di non aver mai utilizzato questi dati per addestrare il suo modello commerciale ufficialmente rilasciato. Tuttavia, questa spiegazione è alquanto debole. Li hanno scaricati e salvati, ma "non li hanno utilizzati nel modello ufficiale". Dove esattamente venga tracciata questa linea di demarcazione probabilmente non è chiaro nemmeno ad Anthropic stessa.
Per il "Panama Project", Anthropic ha specificamente incaricato Tom Turvey di dirigere il progetto. Turvey aveva precedentemente collaborato alla creazione del progetto Google Libri, che aveva anche scatenato anni di controversie sul copyright a causa della scansione massiccia di libri. È difficile affermare che la scelta di Anthropic di affidargli la guida di questo progetto sia stata una coincidenza.
In definitiva, Anthropic si è affidata principalmente a due librai per la fornitura all'ingrosso:
Il rivenditore americano di libri usati Better World Books e la britannica World of Books acquistano spesso decine di migliaia di libri alla volta. Documenti interni mostrano anche che i dipendenti hanno discusso di contattare la Biblioteca Pubblica di New York e hanno persino menzionato di aver chiesto aiuto a una nuova biblioteca da tempo sottofinanziata.
Una volta completato l'approvvigionamento, l'intero processo di scansione assomigliava a una catena di montaggio industriale.

Il fornitore ha utilizzato una taglierina idraulica per rifilare con precisione i dorsi dei libri, e le pagine sciolte sono state poi inserite in uno scanner industriale ad alta velocità. Dopo la scansione, la carta rimanente è stata consegnata a un'azienda di riciclaggio. Uno dei fornitori di servizi di scansione che ha presentato un'offerta ha scritto nella sua proposta che Anthropic sperava di completare la digitalizzazione di un numero di libri compreso tra 500.000 e 2 milioni entro sei mesi.
Il vice consulente generale di Anthropic, Aparna Sridhar, ha risposto che il tribunale aveva stabilito che l'addestramento sull'intelligenza artificiale era "di natura trasformativa" e che la decisione di Anthropic di transare era problematica "in termini di come era stato ottenuto parte del materiale, non se potevamo utilizzare tale materiale".
Questa argomentazione può reggere dal punto di vista legale, ma rivela anche qualcosa: l'azienda non ha mai creduto di aver fatto qualcosa di sbagliato, ma solo che alcuni dei suoi metodi non erano abbastanza puliti.
Useranno i tuoi libri per la formazione e poi ti ruberanno il lavoro.
La stessa cosa sta accadendo ad altre aziende, e alcuni dettagli sono ancora più drammatici.
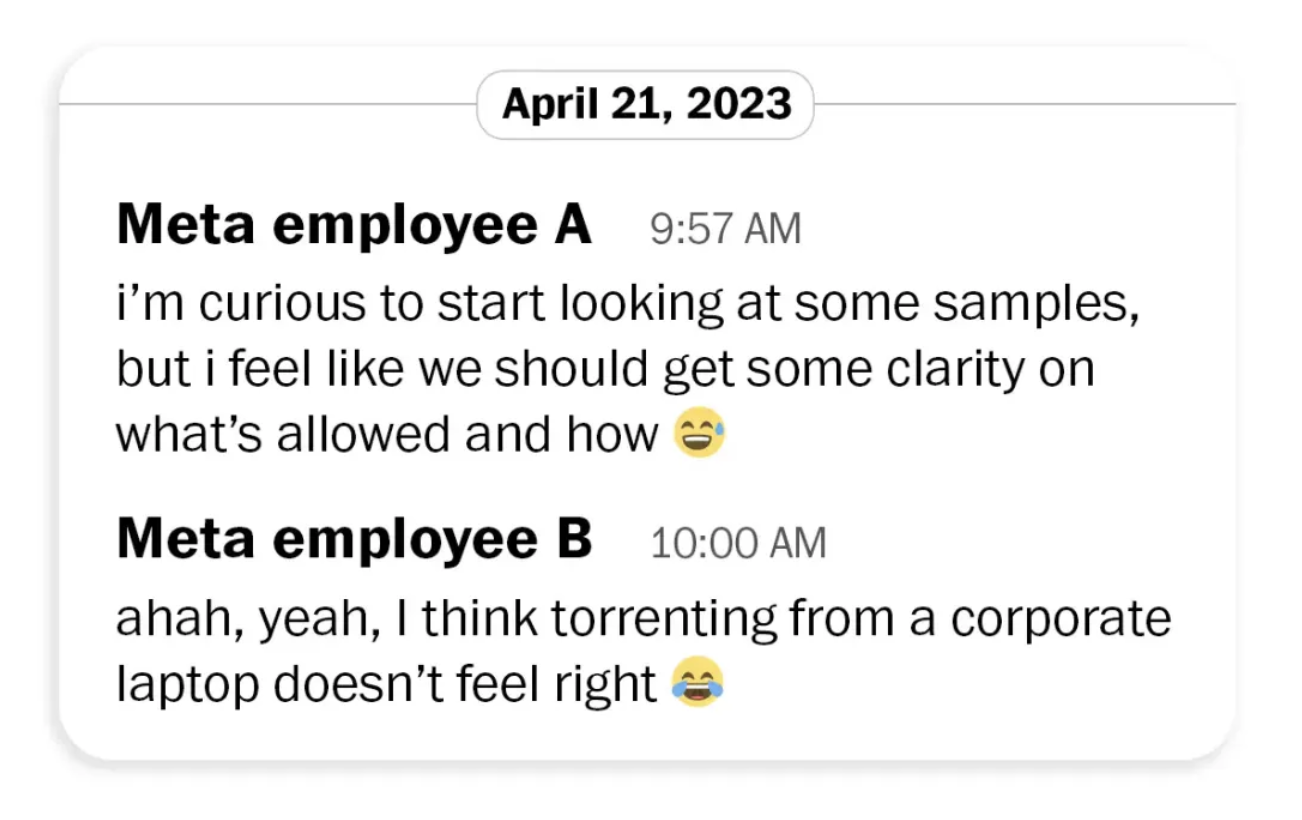
I documenti della causa contro Meta mostrano che un dipendente ha scritto direttamente nel 2023: "Non mi sembra giusto usare il portatile aziendale per scaricare torrent". In seguito ha sollevato specificamente la questione con il team legale, affermando che usare siti torrent potrebbe significare distribuire opere piratate ad altri, "il che potrebbe non essere legalmente consentito".
Ma queste preoccupazioni alla fine non cambiarono nulla.
Un'e-mail interna del dicembre 2023 rivelava che l'utilizzo di LibGen era stato approvato dopo essere stato "segnalato a MZ", riferendosi al CEO Mark Zuckerberg. L'e-mail dichiarava anche apertamente i rischi di cui erano a conoscenza: "Se i media suggerissero che abbiamo utilizzato set di dati noti per essere piratati, ciò potrebbe indebolire la nostra posizione negoziale sulle questioni normative".
In altre parole, non erano inconsapevoli di ciò che stavano facendo; stavano semplicemente valutando il costo di essere scoperti. Per mitigare questo rischio, i dipendenti hanno deliberatamente affittato i server di Amazon per i download torrent invece di quelli di Meta, per evitare di essere ricondotti a Meta.
OpenAI e Microsoft devono affrontare accuse di violazione del copyright da parte degli autori dei libri. OpenAI ha persino ammesso di aver scaricato LibGen, ma ha affermato di aver rimosso i file prima del rilascio di ChatGPT.
Il conflitto sul copyright tra le aziende di intelligenza artificiale e i loro creatori non è iniziato con Anthropic.
All'inizio degli anni 2000, Google condusse una scansione su larga scala delle collezioni delle biblioteche, innescando anche una causa legale durata un decennio. Alla fine, il tribunale stabilì che le azioni di Google costituivano "fair use" perché fornivano solo estratti destinati a guidare i lettori verso i libri, anziché sostituirli.
All'epoca, questo verdetto sembrava ragionevole, ma vent'anni dopo ha fornito uno scudo per l'intero settore dell'intelligenza artificiale.
Google Libri è uno strumento di indicizzazione, mentre l'intelligenza artificiale generativa elabora direttamente il contenuto dei libri e ne produce il testo, a volte entrando in diretta competizione con gli autori. La natura è cambiata, ma la logica giuridica che invoca rimane la stessa, il che è di per sé degno di considerazione.

Lo scorso giugno, il giudice federale William Alsup ha stabilito che l'uso dei libri da parte di Anthropic per addestrare l'intelligenza artificiale era legale, paragonando il processo a un insegnante che "addestra gli studenti a scrivere buoni saggi". Sebbene questa analogia possa sembrare banale, in realtà gli insegnanti non formano milioni di studenti contemporaneamente, né ne ricavano miliardi di dollari.
Alla fine, Anthropic ha scelto di pagare un risarcimento record di 1,5 miliardi di dollari nella storia delle controversie sul copyright legate all'intelligenza artificiale. Tuttavia, a un esame più attento, il risultato finanziario non è stato un cattivo affare. Secondo la legge statunitense sul copyright, il limite massimo di risarcimento danni per ogni opera è di 150.000 dollari, mentre questo accordo si traduce in circa 3.000 dollari per libro, solo il 2% del limite massimo.
Il compenso è stato diviso equamente tra l'autore e l'editore, ma questo accordo ha suscitato polemiche all'interno della comunità degli autori.
Molti autori ritengono che gli editori non abbiano fatto del loro meglio per proteggere le loro opere dall'uso improprio dell'intelligenza artificiale, eppure hanno ricevuto metà del risarcimento. Ancora più importante, l'accordo transattivo non impone ad Anthropic di ammettere alcun comportamento illecito, e la sentenza del tribunale secondo cui "l'addestramento all'intelligenza artificiale costituisce un uso corretto" rimane valida.

In altre parole, l'acquisto di Anthropic per 1,5 miliardi di dollari non è stato solo un accordo, ma anche un'approvazione: possiamo continuare a farlo. Alcuni analisti sottolineano che, con questo precedente stabilito, la violazione del copyright non è più un limite per le aziende di intelligenza artificiale, ma piuttosto un "pedaggio" che può essere calcolato in anticipo nei costi.
Per molti scrittori, questo significa molto più di un semplice assegno. Il reddito annuo medio di uno scrittore americano si aggira intorno ai 20.000 dollari, mentre le aziende di intelligenza artificiale, che valgono centinaia di miliardi di dollari, utilizzano ampiamente il loro lavoro senza autorizzazione e il compenso che ricevono in seguito è ben al di sotto del limite legale.
Ciò che è ancora più preoccupante è che l'intelligenza artificiale sta producendo in massa contenuti testuali. Questo afflusso di testi a basso costo sul mercato sta rendendo ancora più difficile guadagnarsi da vivere scrivendo. L'intelligenza artificiale viene addestrata utilizzando libri scritti da esseri umani, ma i contenuti prodotti dall'intelligenza artificiale stanno riducendo lo spazio a disposizione degli esseri umani per continuare a scrivere libri, creando un circolo vizioso.
I sostenitori hanno una loro logica: l'intelligenza artificiale non memorizza il contenuto dei libri, ma piuttosto estrae modelli linguistici, il che è più simile a una persona che sviluppa la propria espressione dopo aver letto molto. Questa analogia non è del tutto priva di fondamento, ma omette una differenza cruciale:
Una persona legge un libro, ma non un milione; mentre l'intelligenza artificiale digerisce decenni di scritti umani in pochi mesi, per poi replicarli all'infinito e riprodurli a un costo marginale estremamente basso. La scala cambia la natura, quindi non è ragionevole equiparare le due cose.
Milioni di libri sono stati tagliati, scansionati e riciclati, fino a giungere a un accordo transattivo. Quei libri sono spariti da tempo. Nel frattempo, l'intelligenza artificiale continua a scrivere, a una velocità sempre maggiore. Questo è forse l'aspetto più inquietante dell'intera vicenda: nessuno ha veramente pagato il prezzo della distruzione e dell'uso indiscriminato dei libri per addestrare l'intelligenza artificiale.
Indirizzo di riferimento allegato:
https://www.washingtonpost.com/technology/2026/01/27/anthropic-ai-scan-destroy-books/
#Benvenuti a seguire l'account WeChat ufficiale di iFanr: iFanr (ID WeChat: ifanr), dove vi verranno presentati contenuti ancora più interessanti il prima possibile.
